|
Title: BIP39 Validator: Validate wordlists before submission Post by: NotATether on November 27, 2020, 04:06:51 AM I present the the first release of my tool, BIP39 Validator. It is a Python program you can run on a wordlist you are planning to merge into BIP39. It saves you from hours and days of manual verification of words. It is currently limited to validating Latin-based languages. I'll think about adding support for non-Latin languages in the future. It needs about 200MB to run comfortably. Inside a Jupyter Notebook however, it could use up to 700MB (I don't know why, it is definitely a problem with Jupyter). You can run it like this: bip39validator FILE_OR_URL
Newest version is 1.0.7 (https://pypi.org/project/bip39validator/1.0.7/). 1.0.0 to .3 had various bugs or issues getting on PyPI so I had to skip to 1.0.3. You need Python 3.6 or newer to run it. Source code: Source code is available at https://github.com/ZenulAbidin/bip39validator. Installation: Code: pip install bip39validator Or: Code: git clone https://github.com/ZenulAbidin/bip39validator.git Command-line options: Code: usage: bip39validator [-h] [-d LEV_DIST] [-u INIT_UNIQ] [-l MAX_LENGTH] [-D] [-U] [-L] [-o OUTPUT] [-a] [-q] [--debug] [--pycharm-debug] [-v] input View and experiment with a demo on Google Colab. No installation needed! (https://colab.research.google.com/drive/1nJQl25XhjtUNzF3MY_MdH0AotwgdlwOz?usp=sharing) Features: - A Levenshtein distance check - A unique prefix check - A maximum length check - Supports wordlists from local files and plain text remote URLs - Powerful statistical classes for analyzing the results and drawing conclusions from wordlists Planned features: - Spawn self hosted webpage that can validate an uploaded wordlist - Make fourth test for checking that there are no similar words in other languages' wordlists Documentation: Available at Read the docs: https://bip39validator.readthedocs.io/en/latest/index.html Changelog (https://github.com/ZenulAbidin/bip39validator/blob/master/CHANGELOG.md) Known bugs and issues: Local rule: Use this thread for discussion of bip39validator and BIP39 in general. Off-topic posts are alright (within reason). Thanks to @bitmover for the initial idea. Title: Re: BIP39 Validator: Validate wordlists before submission Post by: pooya87 on November 27, 2020, 05:20:40 AM You should post topics like this in Project development board.
Title: Re: BIP39 Validator: Validate wordlists before submission Post by: NotATether on November 27, 2020, 06:21:54 AM You should post topics like this in Project development board. I know but as a program that's intended to be run before submitting a new wordlist PR and that this is directly related to BIP39, it will benefit from more insightful comments by the people who frequent this board. This enables me to get better feedback. Title: Re: BIP39 Validator: Validate wordlists before submission Post by: ABCbits on November 27, 2020, 10:57:53 AM Is it a bug? When i try the tools, both "INFO: Unique initial characters test succeeded" and "ERROR: Unique initial characters test failed" are printed to the terminal.
Code: Reading wordlist file english.txt Additional information, * Linux * Python 3.7 * bip39validator-1.0.4 * Input file https://raw.githubusercontent.com/bitcoin/bips/master/bip-0039/english.txt (https://raw.githubusercontent.com/bitcoin/bips/master/bip-0039/english.txt) * Command used Code: bip39validator english.txt -d 1 Title: Re: BIP39 Validator: Validate wordlists before submission Post by: NotATether on November 27, 2020, 11:35:15 AM Is it a bug? When i try the tools, both "INFO: Unique initial characters test succeeded" and "ERROR: Unique initial characters test failed" are printed to the terminal. With that configuration, all those tests are supposed to succeed so definitely a bug. I'll try to get it fixed later today. By the way, you can use the -o option to send the console output to a file, it is formatted nicer for uploading on the web. Title: Re: BIP39 Validator: Validate wordlists before submission Post by: bitmover on November 27, 2020, 02:48:34 PM Congrats on releasing your new tool. Great work!!
It needs about 200MB to run comfortably. Inside a Jupyter Notebook however, it could use up to 700MB (I don't know why, it is definitely a problem with Jupyter). This is the main problem with python. It is very hard to distribute any software. Your code problably has less than 100k, but due to all dependencies and libraries it uses more than 200mb... I had this problem as well with very small apps that I made. Probably the best way to use it is using Google Colab (which is not ideal) Quote Features: - A Levenshtein distance check - A unique prefix check - A maximum length check - Supports wordlists from local files and plain text remote URLs - Powerful statistical classes for analyzing the results and drawing conclusions from wordlists Planned features: - Spawn self hosted webpage that can validate an uploaded wordlist - Make fourth test for checking that there are no similar words in other languages' wordlists I think the best solution would be to move it all to JS, then anyone could just run it with less than 500kb (at most). JS has a very similar syntax, but it lacks pandas. You will probably need to deal with json format instead of pandas dataframes... I don't know exactly how to do it, especially Levenshtein distance check, but all other checks are simple and probably easily done in JS. It would be nice if someone could just upload a TXT file and have the results in an HTML page. As I did a very similar code to create the Portuguese Wordlist (https://bitcointalk.org/index.php?topic=5272106.0), I miss an important feature in your code. If there is a word in a list, such as "mamá" and in other list the word "mama", you will miss that duplicated words in your code (I guess). I made a dictionary to solve this problem. I just replaced all previous list especial characters with this dictionary, and then I run the checks. Code: repl_dict = {Then I just replaced all lists using Code: italian=italian.replace(repl_dict, regex=True) Edit: I just run https://github.com/sabotag3x/bips/raw/master/bip-0039/portuguese.txt using your tool. Very fast! I liked it very much. No need to move it to JS. Google Colab is very good, I was impressed. I just miss a final conclusion in the end. Something like this: "You passed all checks, no problems." Or "Your list has 3 similar words to spanish, 1 from italian. You also have 3 words with distance >1." soemthing like that. Overall, good job! Title: Re: BIP39 Validator: Validate wordlists before submission Post by: pooya87 on November 27, 2020, 03:12:29 PM I made a dictionary to solve this problem. I just replaced all previous list especial characters with this dictionary, and then I run the checks. You could just Normalize the input using form D (full canonical decomposition) which should have a code in Javascript too (in C# it is a string extension method called Normalize) then replace any character that is "non spacing mark" (mn) (again in C# we have System.Globalization.CharUnicodeInfo that helps).Title: Re: BIP39 Validator: Validate wordlists before submission Post by: NotATether on November 27, 2020, 03:52:47 PM There was a power outage so I couldn't start working on the fix. It just got restored so I will start working on it now. In my haste I forgot to upload the Changelog file, and make bip39validator tell a URL input from a file. I got a long list of TODOs tonight.
It needs about 200MB to run comfortably. Inside a Jupyter Notebook however, it could use up to 700MB (I don't know why, it is definitely a problem with Jupyter). This is the main problem with python. It is very hard to distribute any software. Your code problably has less than 100k, but due to all dependencies and libraries it uses more than 200mb... I had this problem as well with very small apps that I made. Probably the best way to use it is using Google Colab (which is not ideal) On the contrary, the large footprint comes from my own code :D I did a few memory profiles of bip39validator using mprof, and it turns out that the majority of my own code, and of the functions I use from my dependencies, use no more than 50MB. Requests and rich almost have no memory footprint, same with jellyfish.levenshtein_distance (as it just takes two strings as input and returns a number, it's not taking a whole array like I am doing). The large memory usage is coming from the code in my Levenshtein distance results class. As that tests runs, the program builds an array of Levenshtein distances across all words. This takes O(N^2) space but I was able to reduce the space by a factor of 12 by serializing this intermediate array as a string. After the distances are serialized like this, the string is loaded directly into the LevDistResult class. I used to store the intermediate results of the distances as a list of dictionaries with keys and values, but this took 2.4GB (!) to run the Levenshtein distance test. Replacing that with a string array where fields and entries are separated by commas and dashes brought it down to 1.4GB. Finally I rewrote the LevDistResult class to not carelessly create more intermediate representations of the array, to bring its memory usage to where it is today. I could also split the string array into pieces and compress each of them with LZMA compression, but honestly that runs for so long that I abandoned the idea. To be honest, I have no idea what Jupyter is importing to triple bip39validator's memory usage. Vanilla python doesn't have this problem, just only use that and you should be fine, regular end users don't use Jupyter anyway :) I'm surprised however, that I get normal memory usage when it's running inside Anaconda without any Jupyter libraries imported. (In fact, the sample run shown in the GIF was ran in a virtualenv within Anaconda) Quote Features: - A Levenshtein distance check - A unique prefix check - A maximum length check - Supports wordlists from local files and plain text remote URLs - Powerful statistical classes for analyzing the results and drawing conclusions from wordlists Planned features: - Spawn self hosted webpage that can validate an uploaded wordlist - Make fourth test for checking that there are no similar words in other languages' wordlists I think the best solution would be to move it all to JS, then anyone could just run it with less than 500kb (at most). JS has a very similar syntax, but it lacks pandas. You will probably need to deal with json format instead of pandas dataframes... I don't know exactly how to do it, especially Levenshtein distance check, but all other checks are simple and probably easily done in JS. It would be nice if someone could just upload a TXT file and have the results in an HTML page. I really don't want to rewrite it in another language after I just finished it :D but for real though, the memory usage stems from an algorithmic problem, not a language problem. It'll probably still take 200MB if I wrote it in Node.js. As I did a very similar code to create the Portuguese Wordlist (https://bitcointalk.org/index.php?topic=5272106.0), I miss an important feature in your code. If there is a word in a list, such as "mamá" and in other list the word "mama", you will miss that in your code (I guess). I made a dictionary to solve this problem. I just replaced all previous list especial characters with this dictionary, and then I run the checks. ~snip Then I just replaced all lists using Code: italian=italian.replace(repl_dict, regex=True) I actually already have that feature, see rmdiacritics in internal/util.py https://github.com/ZenulAbidin/bip39validator/blob/04fdb443fae7c614d544d7fbc2434ec28a31548b/bip39validator/internal/util.py#L50-L67 (https://github.com/ZenulAbidin/bip39validator/blob/04fdb443fae7c614d544d7fbc2434ec28a31548b/bip39validator/internal/util.py#L50-L67). I look up the Unicode name of the character, such as "LATIN CAPITAL LETTER A WITH CIRCUMFLEX" for Â, and I remove everything after WITH, until I'm left with "LATIN CAPITAL LETTER A" and I transform unicode name back into a character. It's not normalization per se because someone could type a capital A followed by a diacritic for the circumflex and cause the sanity check test (the very first test) to fail. This is also a bug I have to fix. I tried to test your Portuguese wordlist with this but it simultaneously outputs success and failure, the bug reported by @ETFbitcoin, and no word pairs are printed. So either your wordlist is flawless, or it's doing something wrong. I am leaning on your wordlist being flawless as I'm sure the part of the program that prints the words is debugged fully. Title: Re: BIP39 Validator: Validate wordlists before submission Post by: NotATether on November 29, 2020, 10:29:23 PM BIP39 Validator 1.0.5 released! (https://github.com/ZenulAbidin/bip39validator/releases/tag/v1.0.5pypi4)
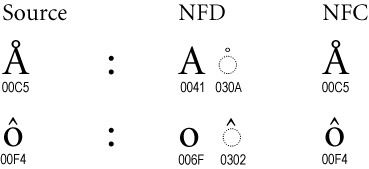
All the above bugs have been fixed, see the Github release page for a complete list of changes in this release. Added - New method InitUniqResult.groups_length(n) Changed -NFC normalization is now done on all words in wordlists after reading them Fixed - bip39validator no longer printing erroneous test failures - GIF in README.rst shows the expected output for the bip39validator command - Plain text URLs as the first positional argument of bip39validator are now recognized, in addition to filenames - Diacritics removal being silently ignored, causing non-english wordlists to fail lowercase characters test I made a dictionary to solve this problem. I just replaced all previous list especial characters with this dictionary, and then I run the checks. You could just Normalize the input using form D (full canonical decomposition) which should have a code in Javascript too (in C# it is a string extension method called Normalize) then replace any character that is "non spacing mark" (mn) (again in C# we have System.Globalization.CharUnicodeInfo that helps).In my case I had to normalize to form C in order to squish the character and diacritics into one letter. It wasn't too difficult to carry out, in Python we have a function called unicodedata.normalize("NFC", string_data) that does the equivalent of those functions. Title: Re: BIP39 Validator: Validate wordlists before submission Post by: pooya87 on November 30, 2020, 06:01:39 AM In my case I had to normalize to form C in order to squish the character and diacritics into one letter. It wasn't too difficult to carry out, in Python we have a function called unicodedata.normalize("NFC", string_data) that does the equivalent of those functions. That's the same function I was talking about but I don't think form C is what you want though. You see in Form D it basically splits the accented letter into a normal letter and the accent which you can then remove. See the following picture to understand what I mean (NFD is normalization form D and NFC form C):https://unicode.org/reports/tr15/images/UAX15-NormFig4.jpg https://unicode.org/reports/tr15/ Title: Re: BIP39 Validator: Validate wordlists before submission Post by: NotATether on November 30, 2020, 11:49:03 AM I don't know how pypi/pip works in detail, but did you forget to include validators as required library on pypi? I updated to 1.0.5 and tried same command on above posts & got this error. Code: ModuleNotFoundError: No module named 'validators' I'll push a bugfix later today. Update: done, please upgrade to Bip39 Validator 1.0.6. Title: Re: BIP39 Validator: Validate wordlists before submission Post by: NotATether on December 13, 2020, 09:35:39 AM How should I normalize CJK characters since they combine several letters into one large ideological character? If I make BIP39 Validator pass the letters through as-is, they will break the assumption that one character represents one letter and cause all my tests to fail.
Is there any algorithm that will split these letters apart to multiple characters? It's particularly important I support CJK wordlists since there are reference lists of them in BIP39. Title: Re: BIP39 Validator: Validate wordlists before submission Post by: BrewMaster on December 13, 2020, 04:18:17 PM How should I normalize CJK characters since they combine several letters into one large ideological character? If I make BIP39 Validator pass the letters through as-is, they will break the assumption that one character represents one letter and cause all my tests to fail. Is there any algorithm that will split these letters apart to multiple characters? It's particularly important I support CJK wordlists since there are reference lists of them in BIP39. i have seen people do something like this with hard coded lists. then look up each word inside that list to see if it exists then alter it based on the hard coded values that can be found there. look inside electrum source code, i remember it had some code for that when it was modifying the seeds but not sure if that's what you want. Title: Re: BIP39 Validator: Validate wordlists before submission Post by: NotATether on December 17, 2020, 07:59:37 AM Here for the Hangul (korean) alphabet system I have a list of letters taken from https://en.wikipedia.org/wiki/Hangul and three of each can be combined to form a single character.
Code: ㄱ ㄴ ㄷ ㄹ ㅁ ㅂ ㅅ ㅇ ㅈ ㅊ ㅋ ㅌ ㅍ ㅎ The next question is that since the characters representing combined CJK characters are undefined in most fonts, which font contains the most CJK characters for me to make a table out of them? Unicode is also appallingly vague about the names of all these combined characters, so I'm not sure if Form D normalization will even work with these. Here's one of their CJK code pages (https://www.unicode.org/charts/PDF/U2B820.pdf) that shows the lack of descriptive names. Title: Re: BIP39 Validator: Validate wordlists before submission Post by: bitmover on December 21, 2020, 01:09:36 PM https://github.com/spesmilo/electrum/blob/master/electrum/wordlist/portuguese.txt Tks bitmover!.... It has only 1626 words and it cannot be used in BIP39 lists like ours. I'm terrified of what I saw on that list :o This has several unusual words, with one letter of difference, with accents (removed), more than 8 letters... a very, very bad list. Hey NotATether. Can you check this wordlist with your app? Maybe you will find several errors. Is it possible to merge a BIP39 word list to electrum? Title: Re: BIP39 Validator: Validate wordlists before submission Post by: NotATether on December 21, 2020, 01:40:06 PM https://github.com/spesmilo/electrum/blob/master/electrum/wordlist/portuguese.txt Tks bitmover!.... It has only 1626 words and it cannot be used in BIP39 lists like ours. I'm terrified of what I saw on that list :o This has several unusual words, with one letter of difference, with accents (removed), more than 8 letters... a very, very bad list. Hey NotATether. Can you check this wordlist with your app? Maybe you will find several errors. Is it possible to merge a BIP39 word list to electrum? Preliminary checks show that this wordlist doesn't have exactly 2048 words (InvalidWordList), a fatal error for this program. Although it may be useful to make a command-line switch that ignores this error and proceeds to run the other tests anyway, normalizing the words as best as it can. I'll probably do that. Title: Re: BIP39 Validator: Validate wordlists before submission Post by: bitmover on December 21, 2020, 05:27:41 PM Preliminary checks show that this wordlist doesn't have exactly 2048 words (InvalidWordList), a fatal error for this program. Although it may be useful to make a command-line switch that ignores this error and proceeds to run the other tests anyway, normalizing the words as best as it can. I'll probably do that. I think it is very useful to get your program running no matter how many words you have. When we were creating our list we used to work with lists with more than 2500 words. Then we passed the checks reducing them down to 1800... then 2500 again, more checks, 2000, and so on. Title: Re: BIP39 Validator: Validate wordlists before submission Post by: NotATether on December 23, 2020, 12:20:35 AM Preliminary checks show that this wordlist doesn't have exactly 2048 words (InvalidWordList), a fatal error for this program. Although it may be useful to make a command-line switch that ignores this error and proceeds to run the other tests anyway, normalizing the words as best as it can. I'll probably do that. I think it is very useful to get your program running no matter how many words you have. When we were creating our list we used to work with lists with more than 2500 words. Then we passed the checks reducing them down to 1800... then 2500 again, more checks, 2000, and so on. It's done. Please pass the --nosane option to test that Portuguese wordlist. BIP39 Validator 1.0.7 released! Notable changes in this release: - Added - --nosane command-line argument for ignoring InvalidWordList errors - Fixed - InvalidWordList errors threw an unknown error instead of printing the specific error message for it Install it from Github (https://github.com/ZenulAbidin/bip39validator/releases/tag/v1.0.7) or PyPI (https://pypi.org/project/bip39validator/1.0.7/). Title: Re: BIP39 Validator: Validate wordlists before submission Post by: bitmover on January 04, 2021, 12:00:27 AM Hey @NotATether
I found some discussion regarding a BIP39 wordlist pull request. You might want to take a look and test your new application. It might be an interesting opportunity for you. Adding Polish wordlist to BIP39 (https://github.com/bitcoin/bips/pull/1037#issuecomment-730783224) Title: Re: BIP39 Validator: Validate wordlists before submission Post by: NotATether on April 01, 2021, 04:22:10 PM Bump
|
{kind=link}