|
482
|
Bitcoin / Development & Technical Discussion / Re: VanitySearch (Yet another address prefix finder)
|
on: March 16, 2019, 02:12:55 PM
|
Ok Could you try to noiline to 2 ModMult, also in GPU/GPUEngine.cu: Line 510: __device__ __noinline__ void _ModMult(uint64_t *r, uint64_t *a, uint64_t *b) {
Line 560: __device__ __noinline__ void _ModMult(uint64_t *r, uint64_t *a) {
It seems that I reached a limit with CUDA.... I had similar problem with the last release... And no warning at all ! |
|
|
|
|
488
|
Bitcoin / Development & Technical Discussion / Re: VanitySearch (Yet another address prefix finder)
|
on: March 15, 2019, 07:05:08 AM
|
Hello, I ended the implementation of endomorphisms and their symmetrics (CPU only). The code is committed to GitHub for those who want to test. On my hardware, I observe a ~20% speed increase (compressed addresses), the hash functions (SSE) takes now 76% of the CPU. GPU implementation is coming... Many thanks again to arulbero for these precious tips concerning symmetries and to all for you for helping to make this software better  |
|
|
|
|
489
|
Bitcoin / Development & Technical Discussion / Re: VanitySearch (Yet another address prefix finder)
|
on: March 14, 2019, 06:19:22 AM
|
it seems to me that ModInv should be much lower than 50% of ModMulk1, are you sure you don't take significative advantage from using more than 256 elements for each batch? Why don't try with 1024 or 4096?
May be there is a confusion between IntGroup::ModInv(256*3 ModMulK1) and Int::ModInv (The true ModInv). Look only a the column on the right (Self CPU). ModInv is taking ~2% (using compressed address) so if I multiply by 2 the group size I can expect a ~1% speed increase for the CPU release. I did the test on 1 core and as expected, the key rate goes from 3.4MKey/s to 3.44MKey/s. Of course for other applications where you do not need to hash, you can expect a more significant speed increase. I attach a new CPU profile with SSE disabled (-nosse option) and using compressed address, this profile should be close enough to the GPU profile, there is no SIMD instruction on GPU to speed up hash functions. 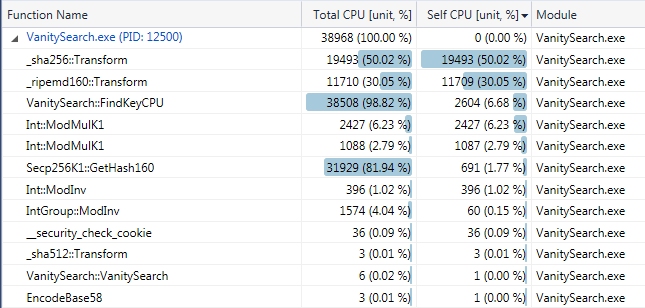 Here the ModInv fall to 1%. For VanitySearch, having a smaller group size is better (This is a reason why I worked a lot on this DRS62 ModInv implementation). I can double the size of the group (I will definitely do it) but not more. The GPU kernel performs one group per thread and send back hash160 to the CPU. If the group size is too large, memory transfer and allocation become a problem. Divide and rule It's amazing how much progress is being made on this software so quickly. Great work!
Thanks |
|
|
|
|
490
|
Bitcoin / Development & Technical Discussion / Re: VanitySearch (Yet another address prefix finder)
|
on: March 13, 2019, 01:16:25 PM
|
Yes and there is also a CUDA intrinsic that search for the number of starting zero __ffsll which could be used to speed up the checking of public key. CPU profiles of the last release: (using compressed address) 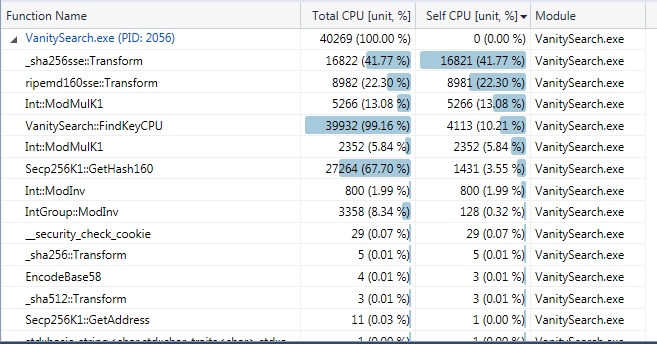 (using uncompressed address) 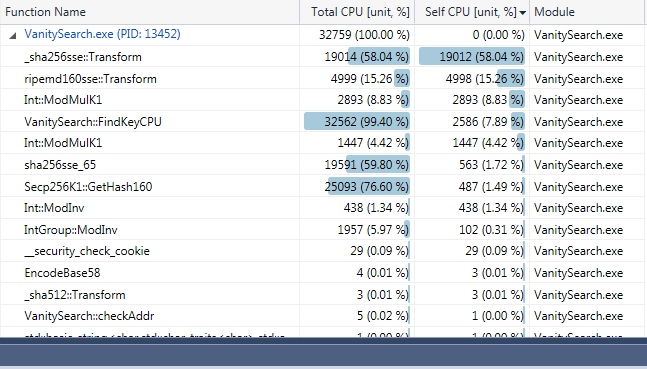 EDIT: FindKey include, mainly, lookup table, ecc arithmetic (ModAdd and ModSub) ModMulK1 is the SecpK1 modular mult, there are 2 ModMulK1 signatures for this method. Added the 2 profiles for compressed and uncompressed. |
|
|
|
|
497
|
Bitcoin / Development & Technical Discussion / Re: VanitySearch (Yet another address prefix finder)
|
on: March 12, 2019, 05:37:29 PM
|
You compute the probability this way?
I compute the difficulty as vanitygen (number are not exactly equal because I use double calculation but you can see they are very near) then simply a Bernoulli trial as vanitygen also. Attacking 1 billion of addresses (I know there is much less with funds) is like having a key rate 1 billion time faster. I just would like a simple text to explain that birthday paradox cannot be used here and that having a big input file does not improve enough the odds to find a collision and it is still infeasible. |
|
|
|
|
498
|
Bitcoin / Development & Technical Discussion / Re: VanitySearch (Yet another address prefix finder)
|
on: March 12, 2019, 04:41:12 PM
|
Hello, I added a note in the readme about attacking full address. It may be not clear. I would like a simple and understandable text about his. Thanks to help me to make it clear. Please don't use VanitySearch to attack a list of complete addresses. It is very unlikely that you find a collision. The time displayed indicates the time needed to reach the displayed probability of the most probable prefix in the list. In case of having n complete addresses in the input file, simply divide this time by the number of entries to get an aproximative idea of the time needed to reach the displayed probability (in fact it is longer). Even with a file containing 1 billion of addresses, using a very competitive hardware, the time needed to reach a probability of 50% will be much longer than the age of the universe. Note that the birthday paradox cannot be applied here as we look for fixed addresses and there is no trick possible (as for Pollard rho method on points coordinates) to simulate random walks because addresses are hashed.
|
|
|
|
|
499
|
Bitcoin / Development & Technical Discussion / Re: VanitySearch (Yet another address prefix finder)
|
on: March 12, 2019, 01:49:49 PM
|
Next Step:
- Optimize CPU/GPU exchange
- Add missing ECC optimizations (some symmetries and endomorphism)
- Add support for GPU funnel shift that should speed up SHA (but I need to find a board with compute capability >3.5, mine is 3.0).
Did you implement already all the steps 1, 2, 3 or there is still space to further improvements? - Support for funnel shift no yet done. - p-iG/p+iG done. - k.(x,y)/-k.(x,-y) done. - Endomorphism is in progress. - CPU/GPU exchange done but still need improvement (difficult to find good compromises with multi prefixes search) |
|
|
|
|



