|
Jean_Luc (OP)
|
 |
March 13, 2019, 08:44:36 AM |
|
Thanks  |
|
|
|
|
|
|
|
|
|
|
|
Unlike traditional banking where clients have only a few account numbers, with Bitcoin people can create an unlimited number of accounts (addresses). This can be used to easily track payments, and it improves anonymity.
|
|
|
Advertised sites are not endorsed by the Bitcoin Forum. They may be unsafe, untrustworthy, or illegal in your jurisdiction.
|
|
|
arulbero
Legendary

 Offline Offline
Activity: 1914
Merit: 2071

|
|
March 13, 2019, 09:25:33 AM |
|
propability -> probability perfrom -> perform Lotery -> Lottery precission -> precision |
|
|
|
|
|
Jean_Luc (OP)
|
|
March 13, 2019, 09:37:59 AM |
|
Thanks Hope I will be less disturbed by dreamers ! |
|
|
|
|
arulbero
Legendary
Offline
Activity: 1914
Merit: 2071
|
|
March 13, 2019, 10:13:47 AM |
|
to 2160/m, the probabilty -> probability the probabilty of finding -> probability Thanks Hope I will be less disturbed by dreamers ! It would be nice (but requires a completely different program --> https://github.com/basil00/pairgen) to exploit the birthday paradox to find 2 addresses with the same very long prefix. To find 2 private keys (and then 2 public keys) related to the same address, it takes about 2^80 steps. But you can't pick wich address will be. To find 2 private keys that generate 2 public keys with the same first 100 bits, it takes 2^50 steps. https://www.reddit.com/r/Bitcoin/comments/34hjph/generating_partial_address_collisions_using_the/ |
|
|
|
|
|
Jean_Luc (OP)
|
|
March 13, 2019, 11:46:06 AM |
|
Thanks again for the typo, the automatic corrector doesn't work when editing the README.md  Yes it can be fun, with GPU optimization we can win few base58 caracter, but 2^80 is still high to find a complete collision. |
|
|
|
|
arulbero
Legendary
Offline
Activity: 1914
Merit: 2071
|
|
March 13, 2019, 12:47:17 PM |
|
With some mod of your code, I could try another project, a vanity pubkey instead of an address pubkey: https://crypto.stackexchange.com/questions/60239/elliptic-curve-and-vanity-public-keysThe "best" pubkey I have found with my onw cpu code so far is: 02000000000000aeea7a7a5c04504f6e4e45452940431c9a264011686f3b746f92
Without sha256 + ripemd160 + base58 encode, I guess I could achieve a very impressive key rate. |
|
|
|
|
|
Jean_Luc (OP)
|
|
March 13, 2019, 01:16:25 PM
Last edit: March 13, 2019, 03:02:27 PM by Jean_Luc |
|
Yes and there is also a CUDA intrinsic that search for the number of starting zero __ffsll which could be used to speed up the checking of public key. CPU profiles of the last release: (using compressed address) 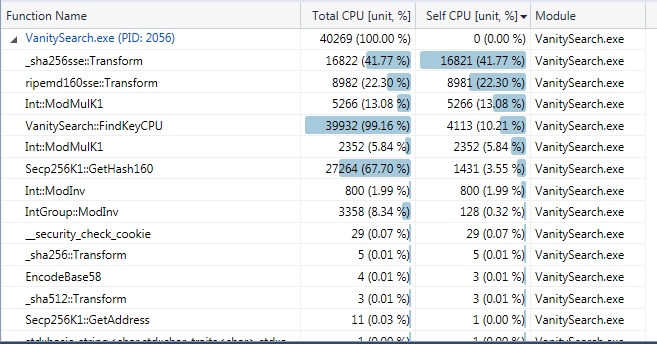 (using uncompressed address) 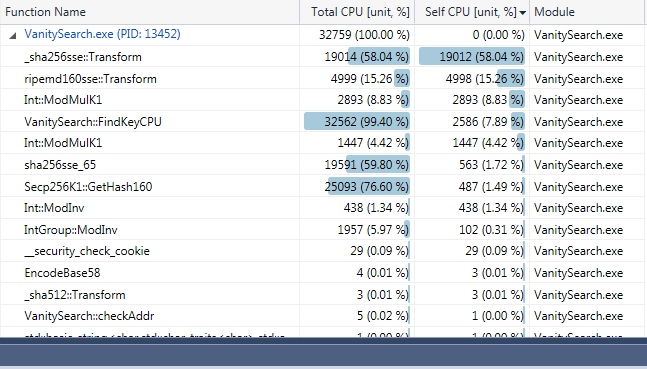 EDIT: FindKey include, mainly, lookup table, ecc arithmetic (ModAdd and ModSub) ModMulK1 is the SecpK1 modular mult, there are 2 ModMulK1 signatures for this method. Added the 2 profiles for compressed and uncompressed. |
|
|
|
|
Lolo54
Member
 Offline
Offline
Activity: 117
Merit: 32
|
|
March 13, 2019, 09:04:35 PM |
|
to 2160/m, the probabilty -> probability the probabilty of finding -> probability Thanks Hope I will be less disturbed by dreamers ! It would be nice (but requires a completely different program --> https://github.com/basil00/pairgen) to exploit the birthday paradox to find 2 addresses with the same very long prefix. To find 2 private keys (and then 2 public keys) related to the same address, it takes about 2^80 steps. But you can't pick wich address will be. To find 2 private keys that generate 2 public keys with the same first 100 bits, it takes 2^50 steps. https://www.reddit.com/r/Bitcoin/comments/34hjph/generating_partial_address_collisions_using_the/pairgen as cubitrack are totally different from vanitysearch or vanytigen they have absolutely not the same goal! Pairgen would actually be the fastest and most efficient program (faster than cubitrack). Using the Birthday Paradox is very effective but it should be optimized much more because currently it only works on CPUs even if it is very fast, make it usable on GPU would give amazing results and optimize its functions like being able to choose an input file -i (several prefixes which one could choose) and a file of exit -o (for each collision found since -i ) and a -continue function or -stop ..... In the current state it is possible to find a prefix of 12 characters without problem see 14 but actually it is not possible to choose the address |
|
|
|
|
arulbero
Legendary
Offline
Activity: 1914
Merit: 2071
|
|
March 13, 2019, 09:23:46 PM |
|
Yes and there is also a CUDA intrinsic that search for the number of starting zero __ffsll which could be used to speed up the checking of public key.
Thanks for the information. CPU profiles of the last release:
...
A note: ModInv <-> ModMulK1 6% <-> 13% (uncompressed) 10,3% <-> 18,9% (compressed) it seems to me that ModInv should be much lower than 50% of ModMulk1, are you sure you don't take significative advantage from using more than 256 elements for each batch? Why don't try with 1024 or 4096? |
|
|
|
|
OgNasty
Donator
Legendary
 Offline
Offline
Activity: 4718
Merit: 4218
Leading Crypto Sports Betting & Casino Platform

|
|
March 14, 2019, 12:54:49 AM
Last edit: March 14, 2019, 10:34:39 PM by OgNasty |
|
It's amazing how much progress is being made on this software so quickly. Great work!
|
| ..Stake.com.. | | | ▄████████████████████████████████████▄
██ ▄▄▄▄▄▄▄▄▄▄ ▄▄▄▄▄▄▄▄▄▄ ██ ▄████▄
██ ▀▀▀▀▀▀▀▀▀▀ ██████████ ▀▀▀▀▀▀▀▀▀▀ ██ ██████
██ ██████████ ██ ██ ██████████ ██ ▀██▀
██ ██ ██ ██████ ██ ██ ██ ██ ██
██ ██████ ██ █████ ███ ██████ ██ ████▄ ██
██ █████ ███ ████ ████ █████ ███ ████████
██ ████ ████ ██████████ ████ ████ ████▀
██ ██████████ ▄▄▄▄▄▄▄▄▄▄ ██████████ ██
██ ▀▀▀▀▀▀▀▀▀▀ ██
▀█████████▀ ▄████████████▄ ▀█████████▀
▄▄▄▄▄▄▄▄▄▄▄▄███ ██ ██ ███▄▄▄▄▄▄▄▄▄▄▄▄
██████████████████████████████████████████ | | | | | | ▄▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▀▄
█ ▄▀▄ █▀▀█▀▄▄
█ █▀█ █ ▐ ▐▌
█ ▄██▄ █ ▌ █
█ ▄██████▄ █ ▌ ▐▌
█ ██████████ █ ▐ █
█ ▐██████████▌ █ ▐ ▐▌
█ ▀▀██████▀▀ █ ▌ █
█ ▄▄▄██▄▄▄ █ ▌▐▌
█ █▐ █
█ █▐▐▌
█ █▐█
▀▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▀█ | | | | | | ▄▄█████████▄▄
▄██▀▀▀▀█████▀▀▀▀██▄
▄█▀ ▐█▌ ▀█▄
██ ▐█▌ ██
████▄ ▄█████▄ ▄████
████████▄███████████▄████████
███▀ █████████████ ▀███
██ ███████████ ██
▀█▄ █████████ ▄█▀
▀█▄ ▄██▀▀▀▀▀▀▀██▄ ▄▄▄█▀
▀███████ ███████▀
▀█████▄ ▄█████▀
▀▀▀███▄▄▄███▀▀▀ | | | ..PLAY NOW.. |
|
|
|
|
Jean_Luc (OP)
|
|
March 14, 2019, 06:19:22 AM
Last edit: March 14, 2019, 11:47:46 AM by Jean_Luc |
|
it seems to me that ModInv should be much lower than 50% of ModMulk1, are you sure you don't take significative advantage from using more than 256 elements for each batch? Why don't try with 1024 or 4096?
May be there is a confusion between IntGroup::ModInv(256*3 ModMulK1) and Int::ModInv (The true ModInv). Look only a the column on the right (Self CPU). ModInv is taking ~2% (using compressed address) so if I multiply by 2 the group size I can expect a ~1% speed increase for the CPU release. I did the test on 1 core and as expected, the key rate goes from 3.4MKey/s to 3.44MKey/s. Of course for other applications where you do not need to hash, you can expect a more significant speed increase. I attach a new CPU profile with SSE disabled (-nosse option) and using compressed address, this profile should be close enough to the GPU profile, there is no SIMD instruction on GPU to speed up hash functions. 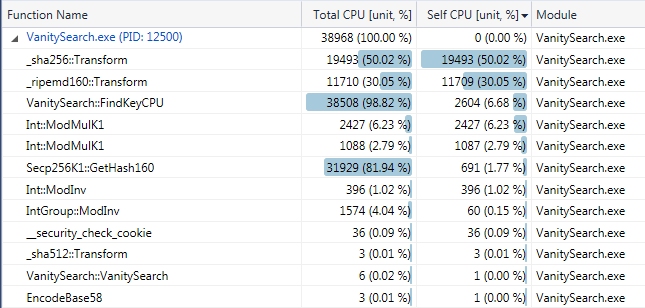 Here the ModInv fall to 1%. For VanitySearch, having a smaller group size is better (This is a reason why I worked a lot on this DRS62 ModInv implementation). I can double the size of the group (I will definitely do it) but not more. The GPU kernel performs one group per thread and send back hash160 to the CPU. If the group size is too large, memory transfer and allocation become a problem. Divide and rule It's amazing how much progress is being made on this software so quickly. Great work!
Thanks |
|
|
|
|
|
Jean_Luc (OP)
|
|
March 15, 2019, 07:05:08 AM |
|
Hello, I ended the implementation of endomorphisms and their symmetrics (CPU only). The code is committed to GitHub for those who want to test. On my hardware, I observe a ~20% speed increase (compressed addresses), the hash functions (SSE) takes now 76% of the CPU. GPU implementation is coming... Many thanks again to arulbero for these precious tips concerning symmetries and to all for you for helping to make this software better |
|
|
|
|
Lolo54
Member
Offline
Activity: 117
Merit: 32
|
|
March 15, 2019, 11:07:21 AM |
|
versions 1.2 to 1.3 looked on my old CPU 1.8 MK / s For version 1.6 it was already a nice increase in speed, a nice optimization Jean_Luc nice! Tested Jean_Luc nice, on my old gear the improvement is 65% CPU .... for the GPU I can not enjoy it for the moment CUDA 8.0
Start Wed Mar 6 15:55:46 2019
Search: 1testr
Difficulty: 15318045009
Base Key:5D48B5A686EF3CCD828F2B23DBD365564D4193F3DC5EA98EB696641F8C8CFC17
Number of CPU thread: 4
3.016 MK/s (GPU 0.000 MK/s) (2^28.15) [P 1.92%][50.00% in 00:57:02][0]
With this version 1.7 the increase of the speed on my old material is still impressive + 30% result version 1.7 Start Mon Mar 11 13:38:57 2019 Difficulty: 15318045009Search: 1testr Base Key:EF61AC731BD4EAA239646EC88F3F3538D39BBA9B2A8C580276CB9AFAE849ECFE Number of CPU thread: 4 4.395 MK/s (GPU 0.000 MK/s) (2^26.09) [P 0.47%][50.00% in 00:45:09][0] The i option works very well at home ... I dream of compatibility with CUDA 8.0 to enjoy my old GPU GT520M  Start Mon Mar 11 13:53:03 2019 Ignoring prefix "1CPuID" (0, I, O and l not allowed) Search: 3 prefixes (Lookup size 3) Base Key:C24307039526A5A5EA9DA60EB6C67A3E9F60BC32BA44E8337171A53751AA3A12 Number of CPU thread: 4 4.192 MK/s (GPU 0.000 MK/s) (2^26.91) [P 37.96%][50.00% in 00:00:14][0] on the other hand I do not know what I'm doing wrong it only records the results of the first pattern good job Jean_Luc  Good Job Jean_Luc but this time I dont get a raise on my equipment its the same Start Fri Mar 15 12:03:33 2019 Difficulty: 15318045009Search: 1testr Base Key:EABBFA78AB6FB34A0D274DF6A909167A0CC8A231DE815525743C84097A632B86 Number of CPU thread: 4 4.290 MK/s (GPU 0.000 MK/s) (2^25.94) [P 0.42%][50.00% in 00:44:45][0] |
|
|
|
|
|
Jean_Luc (OP)
|
|
March 15, 2019, 11:18:16 AM |
|
Good Job Jean_Luc
but this time I dont get a raise on my equipment its the same
I didn't published yet the release as executable downlaod, if you want to test it you have to clone the git repository and compile by yourself. The new release is coming, I'm currently working on GPU code |
|
|
|
|
Lolo54
Member
Offline
Activity: 117
Merit: 32
|
|
March 15, 2019, 11:22:28 AM |
|
Good Job Jean_Luc
but this time I dont get a raise on my equipment its the same
I didn't published yet the release as executable downlaod, if you want to test it you have to clone the git repository and compile by yourself. The new release is coming, I'm currently working on GPU code Ok actually I was thinking its weird too |
|
|
|
|
arulbero
Legendary
Offline
Activity: 1914
Merit: 2071
|
|
March 15, 2019, 05:47:29 PM |
|
I ended the implementation of endomorphisms and their symmetrics (CPU only).
The code is committed to GitHub for those who want to test.
On my hardware, I observe a ~20% speed increase (compressed addresses), the hash functions (SSE) takes now 76% of the CPU.
GPU implementation is coming...
A 20% speed increase on my cpu too, from 13.7 to 16.4 MKeys/s. On GPU from 130 to 132 MKeys/s. |
|
|
|
|
|
|
Lolo54
Member
Offline
Activity: 117
Merit: 32
|
|
March 16, 2019, 10:45:07 AM |
|
versions 1.2 to 1.3 looked on my old CPU 1.8 MK / s For version 1.6 it was already a nice increase in speed, a nice optimization Jean_Luc nice! Tested Jean_Luc nice, on my old gear the improvement is 65% CPU .... for the GPU I can not enjoy it for the moment CUDA 8.0
Start Wed Mar 6 15:55:46 2019
Search: 1testr
Difficulty: 15318045009
Base Key:5D48B5A686EF3CCD828F2B23DBD365564D4193F3DC5EA98EB696641F8C8CFC17
Number of CPU thread: 4
3.016 MK/s (GPU 0.000 MK/s) (2^28.15) [P 1.92%][50.00% in 00:57:02][0]
With this version 1.7 the increase of the speed on my old material is still impressive + 30% result version 1.7 Start Mon Mar 11 13:38:57 2019 Difficulty: 15318045009Search: 1testr Base Key:EF61AC731BD4EAA239646EC88F3F3538D39BBA9B2A8C580276CB9AFAE849ECFE Number of CPU thread: 4 4.395 MK/s (GPU 0.000 MK/s) (2^26.09) [P 0.47%][50.00% in 00:45:09][0] The i option works very well at home ... I dream of compatibility with CUDA 8.0 to enjoy my old GPU GT520M Start Mon Mar 11 13:53:03 2019 Ignoring prefix "1CPuID" (0, I, O and l not allowed) Search: 3 prefixes (Lookup size 3) Base Key:C24307039526A5A5EA9DA60EB6C67A3E9F60BC32BA44E8337171A53751AA3A12 Number of CPU thread: 4 4.192 MK/s (GPU 0.000 MK/s) (2^26.91) [P 37.96%][50.00% in 00:00:14][0] on the other hand I do not know what I'm doing wrong it only records the results of the first pattern good job Jean_Luc Good Job Jean_Luc but this time I dont get a raise on my equipment its the same Start Fri Mar 15 12:03:33 2019 Difficulty: 15318045009Search: 1testr Base Key:EABBFA78AB6FB34A0D274DF6A909167A0CC8A231DE815525743C84097A632B86 Number of CPU thread: 4 4.290 MK/s (GPU 0.000 MK/s) (2^25.94) [P 0.42%][50.00% in 00:44:45][0] wow then I dont know if its normal but here on my home the new release gives a speed increase of 350%   Start Sat Mar 16 11:37:12 2019 Difficulty: 15318045009 Search: 1testr Base Key:14BD6650FC4CCE72930A6395ABCB9B716C7986E0F331C5DB14A7A8BB940B4AA0 Number of CPU thread: 4 15.273 MK/s (GPU 0.000 MK/s) (2^26.46) [P 0.60%][50.00% in 00:11:29][0] |
|
|
|
|
stivensons
Jr. Member
Offline
Activity: 82
Merit: 1
|
|
March 16, 2019, 10:45:49 AM |
|
G:\vanitysearch>vanitysearch -o done6.txt -t 0 -gpu -gpuId 0,1,2,3,4,5,6 1C3J4uW
Start Sat Mar 16 17:37:13 2019
Difficulty: 15318045009
Search: 1C3J4uW
Base Key:91DCE68637F7B992C3F0C6927E5DD81121A319C8018CE3CF8703CA9AD27ECD6B
Number of CPU thread: 0
GPU: GPU #6 GeForce GTX 1060 3GB (9x128 cores) Grid(72x128)
GPU: GPU #5 GeForce GTX 1060 6GB (10x128 cores) Grid(80x128)
GPU: GPU #4 GeForce GTX 1060 6GB (10x128 cores) Grid(80x128)
GPU: GPU #0 GeForce GTX 1060 6GB (10x128 cores) Grid(80x128)
GPU: GPU #2 GeForce GTX 1060 6GB (10x128 cores) Grid(80x128)
GPU: GPU #3 GeForce GTX 1060 6GB (10x128 cores) Grid(80x128)
GPU: GPU #1 GeForce GTX 1060 6GB (10x128 cores) Grid(80x128)
2155.100 MK/s (GPU 2155.100 MK/s) (2^38.99) [P 100.00%][99.00% in 00:00:00][32]
|
|
|
|
|
Lolo54
Member
Offline
Activity: 117
Merit: 32
|
|
March 16, 2019, 10:50:58 AM
Last edit: March 16, 2019, 11:16:15 AM by Lolo54 |
|
Beautiful increase stivensons me compared to the first version on only CPU go 10 times faster! Im not going to slow down but still amazing By comparing the respective vanitygen/ cubitcrack speeds (compressed only) / vanitysearch on my CPU only Vanitygen : Difficulty: 15318045009 [331.74 Kkey/s][total 2865408][Prob 0.0%][50% in 8.9h] cubitcrack: GeForce GT 520M 531/1024MB | 1 target 3.18 MKey/s (17,301,504 total) [00:00:03] vanitysearch: Start Sat Mar 16 12:13:44 2019 Difficulty: 15318045009 Search: 1testr Base Key:30704D4B3275DE9A2D2F8B9AD01DB22F5694E0A58F0C0A0E21D1B1A110305637 Number of CPU thread: 4 15.261 MK/s (GPU 0.000 MK/s) (2^26.12) [P 0.48%][50.00% in 00:14:34][0]
|
|
|
|
|
|


