kano (OP)
Legendary

 Offline Offline
Activity: 4466
Merit: 1798
Linux since 1997 RedHat 4

|
 |
June 02, 2019, 07:22:17 AM |
|
Sigh - who came up with Erlay??? https://www.ccn.com/bitcoin-devs-propose-stronger-faster-blockchain-erlayGotta wonder about bitcoin's future when google finds me a post about slowing down transaction propagation, backed by 3 or 4 of the main core developers ... Yes we know they hate miners, but do they have to make it so obvious? Seriously, who can we blame for this idea if it gets implemented? My first thought was it was someone, with an RPi trying to run bitcoin on a slow tor network, that was trying to influence core ... There's a VERY simple fix to the problem of a large amount of data on a home connection. Reset your DHCP IP address once a day.If you keep the same IP address for a number of days, you end up being well known on the bitcoin network and then people will be downloading the whole blockchain off you regularly. Once a day reset/IP change works fine ... from experience. |
|
|
|
|
|
|
|
|
|
|
|
|
Bitcoin addresses contain a checksum, so it is very unlikely that mistyping an address will cause you to lose money.
|
|
|
Advertised sites are not endorsed by the Bitcoin Forum. They may be unsafe, untrustworthy, or illegal in your jurisdiction.
|
|
|
|
|
|
|
gmaxwell
Moderator
Legendary

 Offline
Offline
Activity: 4158
Merit: 8382

|
|
June 02, 2019, 07:48:57 AM |
|
Kano, you haven't explained your thinking so I cannot respond except in generalities. Why do you believe it hurts miners? By making it possible for the network in general to use higher connection counts while wasting less total bandwidth on relay overheads it should make the network (and individual miners) much more robust against attack, and potentially enjoy even lower orphan rates. As a result I expect it to be helpful to miners. Would people who "hated miners" work so diligently to knock orphan rates down to almost nothing? 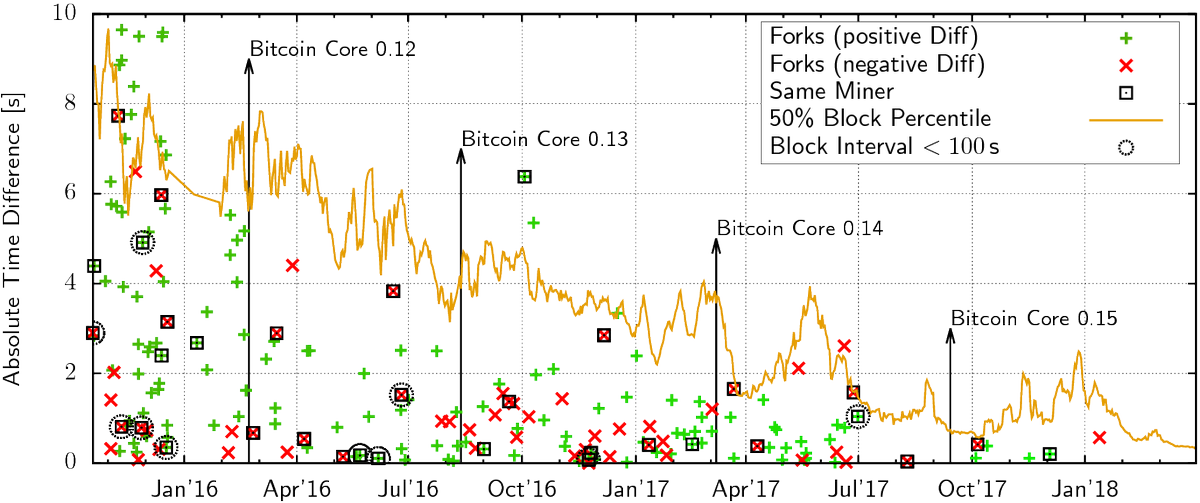 The article you linked is a bit confused, Alex Leishman's tweets are more informative: https://twitter.com/Leishman/status/1133404078413713408 |
|
|
|
|
kano (OP)
Legendary
Offline
Activity: 4466
Merit: 1798
Linux since 1997 RedHat 4
|
|
June 02, 2019, 08:03:13 AM |
|
Kano, you haven't explained your thinking so I cannot respond except in generalities.
Why do you believe it hurts miners?
As I already said, it slows down transaction propagation. It means an increase in the expected number of times a node receiving a block header will request transactions = an expected average slow down. By making it possible for the network in general to use higher connection counts while wasting less total bandwidth on relay overheads it should make the network (and individual miners) much more robust against attack, and potentially enjoy even lower orphan rates. As a result I expect it to be helpful to miners.
As I said, simply reset your IP once a day as I used to do until I changed my internet a few months ago and found the problem you are trying to address ... Would people who "hated miners" work so diligently to knock orphan rates down to almost nothing?
...
That was only Blue Matt that should take any credit for that. In general, the fixes are well known and obvious but took forever to be implemented ... you may remember a Bitcoin issue I raised that bashed you guys severely about that ... And FYI I told Gavin 'my original idea' of changing block propagation to only the header+coinbase back in 2011 ... yeah how long did that take to get implemented? -- P.S. I wouldn't go near twitter, facebook or other similar social networking garbage even if my life depended upon it. |
|
|
|
gmaxwell
Moderator
Legendary
Offline
Activity: 4158
Merit: 8382
|
|
June 02, 2019, 08:28:39 AM
Last edit: June 02, 2019, 09:47:45 AM by gmaxwell |
|
As I already said, it slows down transaction propagation.
Not in a way that aversely impacts mining: See figure 16 in the paper. Most of the change in tx propagation behaviour is for the first hop because the first hop is always performed via reconciliation instead of flooding. So this change ends up with nodes (including miners) receiving the transactions with a similar amount of simultaneity. Erlay itself doesn't slow down propagation, but it benefits from different trade-offs in batching than plain flooding does-- so for our figures in the paper we chose batching intervals that gave a better bandwidth usage trade-off. But in any case, what matters for propagation is tx simultaneity and not total delay. But it's a great question that you ask, and we should cover the simultaneity impact more directly, as it's another consideration in choosing one parameter set over another. Also, FWIW, even if that weren't the case, the existing mining process delays essentially hide tx propagation now; which is why txn are requested very infrequently except for unpropagated txn ( 2.7% of blocks, currently, on my node at home; mostly from miners that include zero fee payout txn). Unpropagated transactions are also not an issue for FIBRE, and there is also a on-hold PR for Bitcoin Core that makes mining more intelligent about including low fee potentially not well propagated txn, but at the moment its on hold because it largely seemed unnecessary. BIP152 also has the prefilled transactions mechanism which is unused except for coinbase transactions, though its a pretty weak mechenism compared to FIBRE. I think it would be really cool to get FIBRE into Bitcoin Core, but Matt isn't interested at this time, and it would likely take a pretty extensive rewrite to make a simplified and cut down version suitable for inclusion. As I said, simply reset your IP once a day as I used to do until I changed my internet a few months ago and found the problem you are trying to address ...
Actually, what you're describing there does essentially nothing against the issue Erlay addresses: relay overhead. But for what resetting your IP actually achieves-- making your node unavailable for new nodes to sync off you-- you'd be much better off setting an upload limit ( -maxuploadtarget), decreasing your peer count ( -maxconnections) or just disabling inbound connections entirely ( -nolisten). Not only would those work better for you (and not require changing your IP, which not everyone can do) but they'd waste less time for other nodes by not leaving them uselessly attempting connections to your old IP. That was only Blue Matt that should take any credit for that. Sorry, that is just entirely untrue. Matt did a tremendous amount of implementation work, improvement, measurement, deployment experience, etc... contributions which cannot be overstated but the designs of both compact blocks and fibre were both created by myself, as were many of the fundamental research behind them. Many other people helped as well (e.g. Pieter)-- Matt did not do that work alone. In general, the fixes are well known and obvious but took forever to be implemented
They were neither known nor at all obvious, and still today even with them widely deployed people still struggle to understand how they work because of how mind-blowing they are (particularly FIBRE, which people consistently misunderstand even after its carefully explained to them because they don't believe that what it does is actually possible, so they continually misunderstand it). The vague handwave "Make block propagation faster" is obvious, but doing so in a way that works under diverse loads doesn't create attack vectors or bad incentives and which actually works is something else entirely. |
|
|
|
|
kano (OP)
Legendary
Offline
Activity: 4466
Merit: 1798
Linux since 1997 RedHat 4
|
|
June 02, 2019, 08:43:36 AM
Last edit: June 02, 2019, 08:57:36 AM by kano |
|
I've no idea where you got those numbers in your graph ... but my pool has never been 10 seconds to get block changes, and it's been running since Sep 2014. You might wanna discuss that with James Hilliard who ran a web site, that the data back then, clearly shows your numbers are false. 2 seconds maybe back then and faster since due to propagation changes in bitcoin ... I suspect your numbers are completely non-pool related. In general, the fixes are well known and obvious but took forever to be implemented
They were neither known nor at all obvious, and still today even with them widely deployed people still struggle to understand how they work because of how mind-blowing they are (particularly FIBRE, which people consistently misunderstand even after its carefully explained to them because they don't believe that what it does is actually possible, so they continually misunderstand it). The vague handwave "Make block propagation faster" is obvious, but doing so in a way that works under diverse loads doesn't create attack vectors or bad incentives and which actually works is something else entirely. You do realise that a vast majority of the people involved in Bitcoin are not very smart right? I am of course referring to anyone who would deal with code and know what they are talking about. P.S. no you are not some code Einstein  Also, FWIW, even if that weren't the case, the existing mining process delays essentially hide tx propagation now; which is why txn are requested very infrequently except for unpropagated txn (E.g. from miners that include zero fee payout txn). Unpropagated txn are also not an issue for FIBRE, and there is also a on-hold PR for Bitcoin Core that makes mining more intelligent about including low fee potentially not well propagated txn, but at the moment its on hold because it largely seemed unnecessary. BIP152 also has the prefilled transactions mechanism which is unused except for coinbase transactions, though its a pretty weak mechenism compared to FIBRE. I think it would be really cool to get FIBRE into Bitcoin Core, but Matt isn't interested at this time, and it would likely take a pretty extensive rewrite to make a simplified and cut down version suitable for inclusion. I currently don't run any special software to talk to FIBRE - just bitcoin core. Yes he is able to get txns from one FIBRE node to another fast, but it's the fact that all pools talk to it that matters. It is in fact simply centralisation at work ... successfully. Which it really should not be, but it does work. The same (or better) effect could be achieved if all pools main bitcoin nodes talked directly to each other ... however that's another can of worms |
|
|
|
gmaxwell
Moderator
Legendary
Offline
Activity: 4158
Merit: 8382
|
|
June 02, 2019, 08:59:13 AM
Last edit: June 02, 2019, 09:17:30 AM by gmaxwell |
|
I've no idea where you got those numbers in your graph ... but my pool has never been 10 seconds to get block changes, and it's been running since Sep 2014.
The graph is from Till Neudecker's excellent observational paper on block propagation in Bitcoin: https://dsn.tm.kit.edu/bitcoin/forks/ The 10 second number you are mentioning is the time that it took for blocks to be accepted and advertised by 50% of the reachable nodes in the network. That line is interesting, but it's not the part of the graph I was referring to: What I was referring to was the all the coloured X marks, which are the creations of orphans. (The median time line does however strongly indicate that the reduction in orphans is due to improved propagation, rather than e.g. miners further centralizing) I suspect your numbers are completely non-pool related.
The reduction in orphans is very much pool related. You do realise that a vast majority of the people involved in Bitcoin are not very smart right?
I am of course referring to anyone who would deal with code and know what they are talking about. Many of the things needed to achieve block propagation speeds that we've achieved are not just unobvious to expert engineers, they're so unobvious that it takes considerable time to explain them. Not all of the things, but many of them. Even the ones that are obvious to you have subtle implications: For example, forwarding a block before verifying it is an obvious improvement to someone with a bit of background, but doing it without creating a massive DOS vector with nodes willing to forward around garbage data, requires some subtle considerations. I currently don't run any special software to talk to FIBRE - just bitcoin core.
Indeed, by design. BIP152 is basically optimized for the (hopefully) low latency hop between you and a FIBRE speaker. For low delay links, e.g. <10ms FIBRE doesn't have a huge advantage over BIP152, because when the link is short there is usually almost no packet loss and multiple round trips are cheap. But it would be better if standard node software could speak the FIBRE protocol too since the network can't consist of only <10ms links, it just hasn't been worth the engineering resources and attack surface trade-offs yet... (or at least hasn't been the lowest hanging fruit, esp since there is the option to run FIBRE externally) Yes he is able to get txns from one FIBRE node to another fast, but it's the fact that all pools talk to it that matters.
It is in fact simply centralisation at work ... successfully.
Thanks for making my point that you totally don't understand what's going on there. FIBRE is a protocol for getting blocks around the world with essentially the lowest delay possible all the time even if it has unknown transactions, even across high latency links, and even if the links lose packets. There isn't anything centralized about FIBRE. FIBRE is an alternative to BIP152 which uses all the more complicated techniques that get really low propagation delay that we left out of BIP152. Matt has a public network of nodes that use FIBRE themselves, some miners run their own FIBRE-using nodes. Matt's public network is a centralized thing, which has its own advantages (e.g. DOS mitigation, getting almost everyone connected without a bunch of additional hops in the way), but those advantages are largely independent of and in addition to the FIBRE protocol advantages. |
|
|
|
|
kano (OP)
Legendary
Offline
Activity: 4466
Merit: 1798
Linux since 1997 RedHat 4
|
|
June 02, 2019, 09:47:10 AM |
|
I've no idea where you got those numbers in your graph ... but my pool has never been 10 seconds to get block changes, and it's been running since Sep 2014.
The graph is from Till Neudecker's excellent observational paper on block propagation in Bitcoin: https://dsn.tm.kit.edu/bitcoin/forks/ The 10 second number you are mentioning is the time that it took for blocks to be accepted and advertised by 50% of the reachable nodes in the network. That line is interesting, but it's not the part of the graph I was referring to: What I was referring to was the all the coloured X marks, which are the creations of orphans. (The median time line does however strongly indicate that the reduction in orphans is due to improved propagation, rather than e.g. miners further centralizing) I suspect your numbers are completely non-pool related.
The reduction in orphans is very much pool related. Nope. It's most likely due to the increase in SPV mining. Almost ALL large pools do SPV mining - i.e. most of the Bitcoin network. It's easy to see that, by simply finding which pools produce empty blocks - that's pretty much certainly an indicator of SPV mining - even if they don't find as many empty blocks any more. While it's not obvious (to some?) why that is the case, it's easy to explain: if you reduce the time between when you first send out an empty block and when you send out a work update, you will reduce the number of empty blocks you produce ... and if the time before was 30-60s and it's now 3-6s ... it's now 10 times fewer empty blocks ... My comment about the centralisation of FIBRE increasing performance, only affects non-SPV pools, which is a minority of the network - like me You can't take credit for SPV mining I'll blatantly say, you've taken credit here where credit is only due for small pools like me who don't do SPV mining and use the FIBRE network. You do realise that a vast majority of the people involved in Bitcoin are not very smart right?
I am of course referring to anyone who would deal with code and know what they are talking about. Many of the things needed to achieve block propagation speeds that we've achieved are not just unobvious to expert engineers, they're so unobvious that it takes considerable time to explain them. Not all of the things, but many of them. Even the ones that are obvious to you have subtle implications: For example, forwarding a block before verifying it is an obvious improvement to someone with a bit of background, but doing it without creating a massive DOS vector with nodes willing to forward around garbage data, requires some subtle considerations. If I remember correctly when I brought that up - my request was to be able to choose who I accepted them from. The OBVIOUS reason being that in that discussion you DIRECTLY implied that I would need to run multiple bitcoinds even on my main node ... ... and I would like to be able to use that option to choose my own bitcoinds to accept such blocks from my (many) other bitcoinds ... I currently don't run any special software to talk to FIBRE - just bitcoin core.
Indeed, by design. BIP152 is basically optimized for the (hopefully) low latency hop between you and a FIBRE speaker. For low delay links, e.g. <10ms FIBRE doesn't have a huge advantage over BIP152, because when the link is short there is usually almost no packet loss and multiple round trips are cheap. But it would be better if standard node software could speak the FIBRE protocol too since the network can't consist of only <10ms links, it just hasn't been worth the engineering resources and attack surface trade-offs yet... (or at least hasn't been the lowest hanging fruit, esp since there is the option to run FIBRE externally) Hmm - no pool in their right mind, not doing SPV mining, wouldn't have at least one node less than 10ms from at least one of Matt's FIBRE nodes. My best is under 1ms Yes he is able to get txns from one FIBRE node to another fast, but it's the fact that all pools talk to it that matters.
It is in fact simply centralisation at work ... successfully.
Thanks for making my point that you totally don't understand what's going on there. FIBRE is a protocol for getting blocks around the world with essentially the lowest delay possible all the time even if it has unknown transactions, even across high latency links, and even if the links lose packets. There isn't anything centralized about FIBRE. FIBRE is an alternative to BIP152 which uses all the more complicated techniques that get really low propagation delay that we left out of BIP152. Matt has a public network of nodes that use FIBRE themselves, some miners run their own FIBRE-using nodes. Matt's public network is a centralized thing, which has its own advantages (e.g. DOS mitigation, getting almost everyone connected without a bunch of additional hops in the way), but those advantages are largely independent of and in addition to the FIBRE protocol advantages. FIBRE as it stands is centralised - since the only one out that that many pools point to is Matt's. What it does is use UDP to send data between the FIBRE nodes, to avoid the wait-for-reply necessary on TCP. But each of the 'pools' talking to FIBRE must use TCP, thus it's a 3 step issue: 1) POOL-TCP->FIBRE 2) FIBRE->UDP->FIBRE 3) FIBRE->TCP-POOL vs 1) POOL-TCP->POOL-TCP and that advantage in that triple connection vs single connection (which wont be very large - i.e. not even 500ms in most of the world) will only be relevant to non-SPV pools. |
|
|
|
gmaxwell
Moderator
Legendary
Offline
Activity: 4158
Merit: 8382
|
|
June 02, 2019, 09:56:17 AM
Last edit: June 02, 2019, 10:45:45 AM by gmaxwell |
|
It's most likely due to the increase in SPV mining.
The chart shows the dramatic speedups in block propagation. SPY mining was ubiquitous (more than half the network hashrate using it, as observed by miners following invalid block forks) before the starting point on that graph. Almost ALL large pools do SPV mining - i.e. most of the Bitcoin network.
It's easy to see that, by simply finding which pools produce empty blocks - that's pretty much certainly an indicator of SPV mining - even if they don't find as many empty blocks any more.
Go look at the rate of empty blocks on the network, there are very few now. In the last 10000 blocks there were 63 coinbase-only blocks. For blocks 384000-394000 (Around January 2016, the start of that chart) there were 414. And yet there were many more orphans back then. I'll blatantly say, you've taken credit here where credit is only due for small pools like me who don't do SPV mining and use the FIBRE network. Block propagation is now so fast that there is little reason to implement spy mining anymore, but even so-- now miners spend much less time using it, which is good for Bitcoin security. I wouldn't be shocked if spy mining now causes miners to lose money and not only from following invalid chains: the loss of transaction fees for spy mined blocks can cost more than the amount saved from a small decrease in orphaning risk. Although there have been a number of invalid blocks mined in the last couple years, there has been no evidence of other miners following these invalid block forks as they did in the past due to SPY mining. If I remember correctly when I brought that up - my request was to be able to choose who I accepted them from.
The OBVIOUS reason being that in that discussion you DIRECTLY implied that I would need to run multiple bitcoinds even on my main node ...
It turns out that we can get essentially the same performance without you having to add "trusted nodes" which have the security and maintenance problems of SPY mining, and we did. But it was not at all "obvious". Now every node gets the benefit of relaying ahead of validation all the time, without risk to the network, and without problematic configuration. FIBRE as it stands is centralised - since the only one out that that many pools point to is Matt's.
Again you are confused. Matt's public relay network is centralized (because, duh, it's matt's network). FIBRE is just a P2P protocol, you are confusing the two. Other parties run the FIBRE protocol, most just don't invite you to connect to them (better for DOS resistance). Another one that many people do connect to is the blockstream satellite broadcast, however. If you recall how we got on this tangent above: I suggested it would be nice to integrate it so more nodes could use it without the trouble of running a patched version, and you disagreed. What it does is use UDP to send data between the FIBRE nodes, to avoid the wait-for-reply necessary on TCP. It does that but that isn't where the performance comes from, its simply a necessary component. FIBRE performance comes from not needing to get any reply to reconstruct a block in all cases, even if there are unknown transactions, while only needing to receive as much data as was unknown, without the sender having any idea what data was unknown... and even doing this if there is packet loss (1-3% is typical on long international links). So if you are missing a couple packets worth of data from anywhere in the block, FIBER will recover the block after you've received a couple packets-- even if many of the packets that were sent got lost along the way. Your knowledge of already relayed transactions is fully exploited, but if a few are missing they don't cause a significant slowdown or require a round-trip. It needs to use UDP so TCP doesn't undermine this property, but if all it did was use UDP it would still need roundtrips, the magic is in the stuff that makes it never need roundtrips. |
|
|
|
|
kano (OP)
Legendary
Offline
Activity: 4466
Merit: 1798
Linux since 1997 RedHat 4
|
|
June 02, 2019, 10:24:32 AM |
|
...
Block propagation is now so fast that there is little reason to implement spy mining anymore, but even so-- now miners spend much less time using it, which is good for Bitcoin security.
Oh rubbish. Most of the bitcoin network does SPV (SPY) ... which, as I said, means that bitcoin core cannot actually make anything more than a minor claim to the lower orphans. If I remember correctly when I brought that up - my request was to be able to choose who I accepted them from.
The OBVIOUS reason being that in that discussion you DIRECTLY implied that I would need to run multiple bitcoinds even on my main node ...
It turns out that we can get essentially the same performance without you having to add "trusted nodes" which have the security and maintenance problems of SPY mining, and we did. But it was not at all "obvious". False, the request was to have the node that gets the block first (and all others later) to pass on the block before verifying it. Thus it's slower by the amount of time it takes to verify it. For internal networks, that makes 100% sense. Again, it's simple to create a list ... but your excuse was that even experts aren't smart enough and will get it wrong ... though I do agree of the general stupidity as I stated further above. I'll quote you on that https://github.com/bitcoin/bitcoin/issues/7049#issuecomment-157569702In general our experience suggests that trust settings are black magic that cannot be configured correctly even by experts-- |
|
|
|
gmaxwell
Moderator
Legendary
Offline
Activity: 4158
Merit: 8382
|
|
June 02, 2019, 10:33:52 AM
Last edit: June 02, 2019, 10:55:39 AM by gmaxwell |
|
Most of the bitcoin network does SPV (SPY) ... which, as I said, means that bitcoin core cannot actually make anything more than a minor claim to the lower orphans.
Most of the network did it in Jan '16.. So would you care to explain how observable SPY mined 1-txn blocks decreased 6-fold while orphan rates decreased something like more than ten fold, following the median block propagation times as improvements rolled out in new releases? You argued that the reduction in orphaning is because increased spy mining, if that were the case you'd expect to see more empty blocks but now we see almost no empty blocks-- less than half a percent. ... Not just why there are fewer empty blocks, but why there are vastly fewer orphans when spy mining was already ubiquitous in Jan 16, and why the number of orphans (and the delay times when they were created) decreased along with block propagation with new releases? False, the request was to have the node that gets the block first (and all others later) to pass on the block before verifying it.
Thus it's slower by the amount of time it takes to verify it.
And today, instead, every node can propagate ahead of validation, without any special casing the first, and without any configuration. CK is obviously no idiot, and yet CK has mined invalid blocks. Idiot proof behaviour isn't just for idiots, mistakes happen to everyone. |
|
|
|
|
kano (OP)
Legendary
Offline
Activity: 4466
Merit: 1798
Linux since 1997 RedHat 4
|
|
June 02, 2019, 10:50:19 AM |
|
which, as I said, means that bitcoin core cannot actually make anything more than a minor claim to the lower orphans.
Then would you care to explain how observable SPY mined 1-txn blocks decreased 6-fold while orphan rates decreased something like more than ten fold, following the median block propagation times as improvements rolled out in new releases? You argued that the reduction in orphaning is because increased spy mining, if that were the case you'd expect to see more empty blocks but now we see almost no empty blocks-- less than half a percent. I did explain it quite clearly already ... but I'll re-quote that large piece of text: Almost ALL large pools do SPV mining - i.e. most of the Bitcoin network.
It's easy to see that, by simply finding which pools produce empty blocks - that's pretty much certainly an indicator of SPV mining - even if they don't find as many empty blocks any more.
While it's not obvious (to some?) why that is the case, it's easy to explain:
if you reduce the time between when you first send out an empty block and when you send out a work update, you will reduce the number of empty blocks you produce ... and if the time before was 30-60s and it's now 3-6s ... it's now 10 times fewer empty blocks ...
FYI the last empty block was by BTC.com a few hours ago. False, the request was to have the node that gets the block first (and all others later) to pass on the block before verifying it.
Thus it's slower by the amount of time it takes to verify it.
And today, instead, every node can propagate ahead of validation, without any special casing the first, and without any configuration. CK is obviously no idiot, and yet CK has mined invalid blocks. Idiot proof behaviour isn't just for idiots, mistakes happen to everyone. CK is an idiot  ... and due to his terribly poor coding practices I've also made it quite clear to many that he's a hack who should not be trusted. However, he has not mined any invalid blocks related to lack of bitcoin verification. His failures include code that created an invalid block template but never testing the part of the code that did that before putting it live Also, of course, making git commits without ever testing or using the code. |
|
|
|
|
DaCryptoRaccoon
|
|
June 02, 2019, 04:40:33 PM |
|
So let me get this straight the idea basically instead of announcing every transaction to to all the peers on the network the transaction are only sent directly over a small number of connections as periodic time-frames?
If transactions are only being broadcast to a small number of peers then relayed on later on is this not just another bottle neck waiting to happen?
It's like saying lets not open all the door's to let everyone in at once lets just open the side door and let "select" nodes in.
From where it stands now bitcoin really is moving quickly towards this central system that seems to be benefiting the few rather than the whole. (just sayin)
|
Raccoon Stuff
|
|
|
gmaxwell
Moderator
Legendary
Offline
Activity: 4158
Merit: 8382
|
|
June 02, 2019, 05:17:41 PM |
|
If transactions are only being broadcast to a small number of peers then relayed on later on is this not just another bottle neck waiting to happen?
Transactions are sent to all peers in erlay. The paper even specifically shows that the behaviour holds up under varying tx rates. |
|
|
|
|
server
Legendary
Offline
Activity: 892
Merit: 1002
1 BTC =1 BTC
|
|
June 02, 2019, 07:43:04 PM |
|
|
|
|
|
|


