Telariust
Jr. Member

 Offline Offline
Activity: 38
Merit: 18

|
 |
September 16, 2019, 06:58:06 PM
Last edit: October 09, 2019, 12:41:46 PM by Telariust |
|
it very slow for 1core C/C++ openssl/secp256k1, it should be more!
talk less, work more... my C99 prototype ready! everything is exactly as I described above 1core i7-6820, win7x64 // MODE: J + A -> J, xJ->xA ; 0.23Mk/s; secp256k1_gej_add_ge_var(), convert only X jacobian to affine C:\cygwin64\home\User\pollard-kangaroo>pollard-kangaroo.exe
[###########################################################]
[# Pollard-kangaroo PrivKey Recovery Tool #]
[# C99, bitcoin-core/secp256k1 library #]
[# singlecore #]
[# ver 0.1 #]
[###########################################################]
[DATE(utc)] 16 Sep 2019 18:23:53
[~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~]
[pow2bits] 2^40
[range] 2^39..2^40 ; W = U - L = 0x0000008000000000 (2^39)
[maxDP] 1024 (max elements in hashtable)
[DPmodule] 0x0000000000040000
[pow2Jmax] 23
[~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~]
--> TEST MODE
[pubkey(tests)] 03A2EFA402FD5268400C77C20E574BA86409EDEDEE7C4020E4B9F0EDBEE53DE0D4
--> pubkey valid!
[~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~]
[+] Sp-table of pow2 points - ready
[~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~]
[+] T1+W1 herds - ready
--> [0y 0m 0d 00:00:06s] [0.23Mk/s] [0y 0m 0d 00:00:11s]
[~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~]
[i] 1700051j; DP T+W=4+3=7; dp/kgr=3.5;
[prvkey#40] 000000000000000000000000000000000000000000000000000000E9AE4933D6
[#############################; passtime: 0y 0m 0d 00:00:06s]
[####################################; precision: 6s 38ms]
[~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~]
[DATE(utc)] 16 Sep 2019 18:23:59
[~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~]
[x] EXIT
40bits, w=39bit, 2w^(1/2) at 17sec // MODE: 1*J+k*G->J, xJ->xA ; 0.09Mk/s; secp256k1_ecmult(), convert only X jacobian to affine --> [0y 0m 0d 00:00:16s] [0.09Mk/s] [0y 0m 0d 00:00:27s]
[~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~]
[i] 1700051j; DP T+W=4+3=7; dp/kgr=3.5;
[prvkey#40] 000000000000000000000000000000000000000000000000000000E9AE4933D6
[####################################; precision: 17s 18ms]
40bits, w=39bit, 2w^(1/2) at 43sec // MODE: k*G->J, J+J->J, xJ->xA; 0.03Mk/s; secp256k1_ecmult_gen() + secp256k1_gej_add_var() , convert only X jacobian to affine --> [0y 0m 0d 00:00:48s] [0.03Mk/s] [0y 0m 0d 00:01:19s]
[~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~]
[i] 1700051j; DP T+W=4+3=7; dp/kgr=3.5;
[prvkey#40] 000000000000000000000000000000000000000000000000000000E9AE4933D6
[####################################; precision: 51s 595ms]
40bits, w=39bit, 2w^(1/2) at 127sec ################# so as not to create possible problems for you, I will publish the source code only after you.
We are doing this to learn. It would be no problem for us if you publish your source code. We already have the published python source code and have looked at it in order to improve our program. You do not need to wait for us to publish. The science fair is not until next year so we have a lot of time to get everything just right and then move the code on to a GPU. Ok! I will publish a little later, need to tidy the code.github.com/Telariust/pollard-kangaroo-c99/releases/ Enjoy!  ################# At this time, I will try to write addition in affine coordinates, which is the fastest way, +30% expected speed-up.
in ideal - need write new functions:
A+A->A (1I, 2M, 1S) - best choice, because in the end we need X in affine for unique representation each point to adding in storage hashtable..
after which do not need to spend 8M,3S, only nearly 20M to each 1I, it +35% speed-up
Affinity A + A-> A ready. Real growth was about 6-8% (probably 20M per 1I from the article is overpriced) runing test, task is 50 1core i7-6820, win7x64 [pow2bits] 2^50
[range] 2^49..2^50 ; W = U - L = 0x0002000000000000 (2^49)
[algo#1] J + A -> J, xJ->xA ; secp256k1_gej_add_ge_var() --> [0y 0m 0d 00:09:16s] [0.27Mk/s] [0y 0m 0d 00:00:00s]
[i] 152944440j; DP T+W=4+6=10; dp/kgr=5.0;
[prvkey#50] 00000000000000000000000000000000000000000000000000022BD43C2E9354
[#############################; passtime: 0y 0m 0d 00:09:16s]
[####################################; precision: 556s 699ms]
[algo#0] A + A -> A, xA ready ; the fastest! --> [0y 0m 0d 00:08:42s] [0.29Mk/s] [0y 0m 0d 00:00:00s]
[i] 152944440j; DP T+W=4+6=10; dp/kgr=5.0;
[prvkey#50] 00000000000000000000000000000000000000000000000000022BD43C2E9354
[#############################; passtime: 0y 0m 0d 00:08:42s]
[####################################; precision: 522s 492ms]
runtime: 556/522 = x0.065 (+6,5%) hashrate: 0.29/0.27 = x0.074 (+7,4%) miserable improvement, less statistical error... certainly better than nothing; but checked the hypothesis A+A->A; Short compare algoritms: 1core i7-6820, win7x64 // 0: A + A -> A, xA ready ; 0.291Mk/s; the fastest
// 1: J + A -> J, xJ->xA ; 0.274Mk/s; secp256k1_gej_add_ge_var()
// 2: J + A -> J, xJ->xA ; 0.267Mk/s; secp256k1_gej_add_ge()
// 3: 0*P0+k*G->J, xJ->xA ; 0.091Mk/s; secp256k1_ecmult()
// 4: k*G->J, J+J->J, xJ->xA; 0.031Mk/s; secp256k1_ecmult_gen() + secp256k1_gej_add_var()
ready-made, if someone needs it. Affine points addition, custom functions, C99, bitcoin-core/secp256k1 2A -> A (1I, 2M, 2S) A + A -> A (1I, 2M, 1S) // 2A -> A (1I, 2M, 2S)
void secp256k1_ge_double_var(secp256k1_ge *r, const secp256k1_ge *a){
secp256k1_fe rX, rY;
secp256k1_fe tmp1, tmp2;
tmp1 = a->y;
if ( (a->infinity == 1) || secp256k1_fe_normalizes_to_zero_var(&tmp1) ) {
secp256k1_ge_set_infinity(r);
return;
}
// s = (3x^2 + A)/(2y) # 1I 2M 1S
// A=0 B=7 (secp256k1)
secp256k1_fe_sqr(&tmp2, &a->x);//1S
tmp1 = tmp2;
secp256k1_fe_add(&tmp1, &tmp2);
secp256k1_fe_add(&tmp1, &tmp2);
secp256k1_fe_normalize_weak(&tmp1);
tmp2 = a->y;
secp256k1_fe_add(&tmp2, &a->y);
secp256k1_fe_normalize_weak(&tmp2);
secp256k1_fe_inv_var(&tmp2, &tmp2);//1I
secp256k1_fe_mul(&tmp1, &tmp1, &tmp2);//1M
// x' = s^2-2x # 1S
secp256k1_fe_sqr(&rX, &tmp1);//1S
tmp2 = a->x;
secp256k1_fe_add(&tmp2, &a->x);
secp256k1_fe_negate(&tmp2, &tmp2, 1);
secp256k1_fe_add(&rX, &tmp2);
secp256k1_fe_normalize_weak(&rX);
// y' = s(x-x')-y # 1M
secp256k1_fe_negate(&tmp2, &rX, 1);
rY = a->x;
secp256k1_fe_add(&rY, &tmp2);
secp256k1_fe_normalize_weak(&rY);
secp256k1_fe_mul(&rY, &rY, &tmp1);//1M
secp256k1_fe_negate(&tmp2, &a->y, 1);
secp256k1_fe_add(&rY, &tmp2);
secp256k1_fe_normalize_weak(&rY);
r->x = rX;
r->y = rY;
}
// A + A -> A (1I, 2M, 1S)
void secp256k1_ge_add_ge_var(secp256k1_ge *r, const secp256k1_ge *a, const secp256k1_ge *b){
if ( (a->infinity == 1) || (b->infinity == 1) ) {
if ( (a->infinity == 1) ^ (b->infinity == 1) ) {
if (a->infinity == 1) { r->x = b->x; r->y = b->y; return; }
if (b->infinity == 1) { r->x = a->x; r->y = a->y; return; }
}else{
secp256k1_ge_set_infinity(r);
return;
}
}
secp256k1_fe rX, rY;
secp256k1_fe tmp1, tmp2;
secp256k1_fe aXneg;
secp256k1_fe_negate(&aXneg, &a->x, 1);
secp256k1_fe aYneg;
secp256k1_fe_negate(&aYneg, &a->y, 1);
//dx = B.x - A.x
tmp1 = b->x;
secp256k1_fe_add(&tmp1, &aXneg);
//dy = B.y - A.y
tmp2 = b->y;
secp256k1_fe_add(&tmp2, &aYneg);
if (secp256k1_fe_normalizes_to_zero_var(&tmp1)) {
if (secp256k1_fe_normalizes_to_zero_var(&tmp2)) {
secp256k1_ge_double_var(r, a);
return;
}else{
secp256k1_ge_set_infinity(r);
return;
}
}
secp256k1_fe_normalize_weak(&tmp1);
secp256k1_fe_normalize_weak(&tmp2);
secp256k1_fe_inv_var(&tmp1, &tmp1);//1I
//c = dy * invert(dx, p) % p # 1I,1M
secp256k1_fe c;
secp256k1_fe_mul(&tmp2, &tmp2, &tmp1);//1M
//R.x = (c**2 - A.x - B.x) % p # 1S
secp256k1_fe_sqr(&rX, &tmp2);//1S
secp256k1_fe_add(&rX, &aXneg);
secp256k1_fe_negate(&tmp1, &b->x, 1);
secp256k1_fe_add(&rX, &tmp1);
secp256k1_fe_normalize_weak(&rX);
//R.y = (c*(A.x - R.x) - A.y) % p # 1M
rY = a->x;
secp256k1_fe_negate(&tmp1, &rX, 1);
secp256k1_fe_add(&rY, &tmp1);
secp256k1_fe_normalize_weak(&rY);
secp256k1_fe_mul(&rY, &rY, &tmp2);//1M
secp256k1_fe_add(&rY, &aYneg);
secp256k1_fe_normalize_weak(&rY);
r->x = rX;
r->y = rY;
}
From https://www.nayuki.io/page/elliptic-curve-point-addition-in-projective-coordinates################# ..Tests with C++ (VS2013) leads to x2..x3 faster calculations only (single-thread), but much more complicated code..
..because this is the limit of computation on the cpu and now we have the answer ver0.1 C99, win7x64, algo A+A->A 1core i7-6820 0.291Mk/s 1core i5-2540 0.219Mk/s ver0.9 python37x64+gmpy2, win7x64, algo A+A->A 1core i7-6820 174.3K j/s; 1core i5-2540 99.7K j/s; |
|
|
|
|
|
|
|
The grue lurks in the darkest places of the earth. Its favorite diet is adventurers, but its insatiable appetite is tempered by its fear of light. No grue has ever been seen by the light of day, and few have survived its fearsome jaws to tell the tale.
|
|
|
Advertised sites are not endorsed by the Bitcoin Forum. They may be unsafe, untrustworthy, or illegal in your jurisdiction.
|
|
|
|
|
|
|
BurtW (OP)
Legendary
 Offline
Offline
Activity: 2646
Merit: 1130
All paid signature campaigns should be banned.

|
|
September 16, 2019, 10:47:22 PM |
|
Thanks for all of your help! We have been very carefully implementing all the best suggestions. The latest test results using my laptop computer are as follows. Average h/s over all runs from test 0 through test 49: 80,028Max h/s reached was: 194,547We have updated the run results in the OP. test hps
---- -------
0 2,420
1 1,211
2 2,197
3 13,367
4 11,451
5 9,942
6 23,740
7 18,849
8 22,703
9 48,497
10 49,485
11 51,391
12 55,693
13 66,687
14 44,872
15 50,782
16 44,037
17 31,128
18 62,800
19 24,245
20 27,484
21 27,204
22 30,454
23 97,422
24 62,548
25 97,612
26 90,048
27 110,399
28 63,970
29 163,713
30 147,993
31 194,547
32 167,280
33 132,836
34 58,530
35 163,698
36 173,776
37 128,880
38 138,391
39 121,995
40 83,115
41 140,884
42 123,750
43 95,156
44 105,499
45 121,877
46 79,010
47 139,557
48 138,639
49 139,645
|
Our family was terrorized by Homeland Security. Read all about it here: http://www.jmwagner.com/ and http://www.burtw.com/ Any donations to help us recover from the $300,000 in legal fees and forced donations to the Federal Asset Forfeiture slush fund are greatly appreciated! |
|
|
brainless
Member
Offline
Activity: 316
Merit: 34
|
|
September 17, 2019, 06:05:16 AM |
|
Telariust, Could you do us a favor and run our version of the secp256k1_ecmult_gen function through your same benchmarks and let us know what you get? This way we can compare apples to apples on hop rates. static inline void secp256k1_ecmult_gen(const secp256k1_ecmult_gen_context *ctx, secp256k1_gej *r, const secp256k1_scalar *gn)
{
/* Computing (n+b)G - bG instead of nG directly, no gain by changing this. */
secp256k1_scalar gnb;
secp256k1_scalar_add(&gnb, gn, &ctx->blind);
*r = ctx->initial;
for (int j = 0; j < 64; j++) {
secp256k1_ge add;
const int bits = secp256k1_scalar_get_bits(&gnb, j * 4, 4);
secp256k1_ge_from_storage(&add, &(*ctx->prec)[j][bits]);
secp256k1_gej_add_ge_var(r, r, &add, NULL);
}
}
Test#2, multiplication, pseudo random points, calculation 1million pubkeys in loop: for(uint64_t i = 1; i<1000000 ; ++i){
secp256k1_scalar_set_uint64(&scalarK, TestGej.x.n[0]); // pseudo random points
MULT_FUNCTION_HERE(&context, point_jacobian, &scalarK)
}
origin secp256k1_ecmult_gen() 1M at 26sec 699msec; 0.037 Mk/s custom BurtW secp256k1_ecmult_gen() 1M at 22sec 498msec; 0.044 Mk/s my processor 13-6100 ddr4 8gb tel-kangro-0.83 speed [~] 384.0K j/s; 14.1Mj 0.0%; dp/kgr=0.0; [ 0d 00:00:36s lost_TIME_left 750y 6m 8d 07:20:44s ] |
13sXkWqtivcMtNGQpskD78iqsgVy9hcHLF
|
|
|
BurtW (OP)
Legendary
Offline
Activity: 2646
Merit: 1130
All paid signature campaigns should be banned.
|
|
September 17, 2019, 12:37:39 PM
Last edit: September 17, 2019, 03:45:46 PM by BurtW |
|
We have a new record for our little program: 57 bit private key in 1.73 hours averaging 153,791 hops per second using only 310,784 bytes of dynamically allocated memory. We still have not yet implemented all of the great ideas in this thread that will improve the hop rate and implementation/algorithm. ver = 186, sizeof(unsigned) 4, 128 bit integers, scalar 4x64, field 5x52, 8 processors, 8 available
test = 56
seed = none (default value)
b = 2 ^ 57 = 0x0200000000000000
a = 2 ^ 56 = 0x0100000000000000
P = 0x02A521A07E98F78B03FC1E039BC3A51408CD73119B5EB116E583FE57DC8DB07AEA (33 bytes)
k0000 = 0x2DCF462904B478D8
s = 0x01EB25C90795D61C
s*G = 0x02A521A07E98F78B03FC1E039BC3A51408CD73119B5EB116E583FE57DC8DB07AEA (33 bytes)
numt = 0x8 (8)
mem = 0x4BE00 (310784) bytes
cmps = 0x34C9808B (885620875)
hops = 0x39144058 (957628504)
hps = 153790.653757
time = 1.7297 hours (6226831609100 nsecs)
so as not to create possible problems for you, I will publish the source code only after you.
At this time, I will try to write addition in affine coordinates, which is the fastest way, +30% expected speed-up.
We are doing this to learn. It would be no problem for us if you publish your source code. We already have the published python source code and have looked at it in order to improve our program. You do not need to wait for us to publish. The science fair is not until next year so we have a lot of time to get everything just right and then move the code on to a GPU. Statistics from our most recent run: test time hps hops compares mem(bytes) total time
---- -------------- ------- ---------- ------------ ---------- --------------
0 0.8564 msecs 1167 1 3 1232 856400
1 0.7479 msecs 1337 1 3 1232 747900
2 0.6127 msecs 1632 1 3 1232 612700
3 8.6445 msecs 925 8 10 1232 8644500
4 1.6279 msecs 6757 11 13 1232 1627900
5 1.9472 msecs 7703 15 17 1232 1947200
6 12.3022 msecs 4226 52 54 1232 12302200
7 2.0009 msecs 15992 32 34 1232 2000900
8 3.2746 msecs 13742 45 47 1232 3274600
9 10.7214 msecs 47568 510 512 1232 10721400
10 18.3054 msecs 48783 893 895 1232 18305400
11 26.3645 msecs 53594 1413 1415 1232 26364500
12 78.4207 msecs 37949 2976 2978 1232 78420700
13 13.5507 msecs 61841 838 338 21888 13550700
14 15.4483 msecs 45441 702 38 23360 15448300
15 22.4275 msecs 48378 1085 143 26304 22427500
16 25.1679 msecs 36355 915 305 32192 25167900
17 31.0598 msecs 24050 747 141 43968 31059800
18 44.3618 msecs 60975 2705 2132 67520 44361800
19 63.4771 msecs 23866 1515 949 114624 63477100
20 120.1801 msecs 32010 3847 3128 208832 120180100
21 200.2294 msecs 26854 5377 5145 397248 200229400
22 397.8554 msecs 30810 12258 11740 774080 397855400
23 91.7390 msecs 97635 8957 5788 40896 91739000
24 64.6165 msecs 60897 3935 770 42368 64616500
25 130.9894 msecs 108573 14222 10071 45312 130989400
26 105.1900 msecs 92489 9729 6966 51200 105190000
27 152.1824 msecs 115979 17650 13956 62976 152182400
28 103.3762 msecs 76613 7920 4563 86528 103376200
29 1.3121 secs 190967 250564 245502 133632 1312076400
30 860.7668 msecs 175329 150918 146792 227840 860766800
31 6.7634 secs 194092 1312726 1302011 416256 6763397900
32 8.2153 secs 195437 1605582 1592230 793088 8215338900
33 2.5348 secs 136228 345314 276375 78336 2534806300
34 1.2517 secs 62445 78166 8225 79808 1251746900
35 4.6382 secs 163879 760109 689150 82752 4638222000
36 38.0879 secs 187772 7151877 6987945 89152 38087934000
37 18.5839 secs 182235 3386646 3302690 100416 18583879400
38 25.5975 secs 183080 4686411 4596034 123968 25597487500
39 46.6920 secs 160988 7516894 8474293 171072 46691996800
40 1.7609 secs 95305 167826 98613 265280 1760925900
41 3.6092 mins 163432 35391791 40060843 453696 216552401100
42 23.0696 mins 181027 250574243 249647494 830528 1384178187200
43 58.8688 secs 113200 6663978 4542748 152544 58868821100
44 1.8608 mins 148273 16554034 14381807 154016 111645595700
45 2.2344 mins 154316 20688475 18479327 156960 134065352000
46 46.5020 secs 83000 3859681 1996004 162848 46501976100
47 48.5642 mins 176154 513288902 505356026 175136 2913854013900
48 17.2490 mins 174174 180259712 176439508 198176 1034938770000
49 23.4304 mins 175194 246292149 242207587 245280 1405822811400
50 18.4636 mins 151963 168347310 188535204 339488 1107817430400
51 58.0994 mins 153719 535862165 606643869 527904 3485962802800
52 34.3880 mins 153038 315762297 357149197 904736 2063282714200
53 40.2602 mins 120565 291240607 223324940 300480 2415611495500
54 41.4377 mins 121698 302574766 234686603 301952 2486260671300
55 54.7941 mins 135532 445582526 376662553 304896 3287646391600
56 1.7297 hours 153790 957628504 885620875 310784 6226831609100
|
Our family was terrorized by Homeland Security. Read all about it here: http://www.jmwagner.com/ and http://www.burtw.com/ Any donations to help us recover from the $300,000 in legal fees and forced donations to the Federal Asset Forfeiture slush fund are greatly appreciated! |
|
|
racminer
Member
Offline
Activity: 242
Merit: 17
|
|
September 17, 2019, 06:43:41 PM
Last edit: September 17, 2019, 07:10:00 PM by racminer |
|
I mentioned that there is no need to compare T and W lists at every hop because comparing lists is time consuming. You may insert an if ( hops % cycle ==0) { compare ...} where cycle can be 100 000 or even 1 000 000 especially for higher cases. for example, case 56 , you have 957 628 504 hops and 885 620 875 compares, take cycle=1 000 000, I am pretty sure that timing will be down to 15 min. In other words, you don't need to check for collisions at every hop  Three points: 1) Our code is very different from the published python code with many modification for speed and to get it ready to move to a GPU. We do not do list comparisons like the python code does. 2) The number we are displaying is the actual total number of point to point comparisons and is not the same as the number of list comparisons in the python code. 3) To get an equivalent number from the python code that uses the list compare function you would have to count up the actual number of point to point comparisons that are hidden down in the list comparison function. OK 1) Our code is very different from the published python code with many modification for speed and to get it ready to move to a GPU. We do not do list comparisons like the python code does. >>> Pollard-kangaroo is Pollard-kangaroo as far as I know 2) The number we are displaying is the actual total number of point to point comparisons and is not the same as the number of list comparisons in the python code. >>> up to case 63, the lists are quite small in size (rarely more than 200), so brute force point to point is around 200x200 = 40000 still small. 3) To get an equivalent number from the python code that uses the list compare function you would have to count up the actual number of point to point comparisons that are hidden down in the list comparison function. >>> I did count, the number of hops is around 20 times bigger that point to point comparison in case 63. But why is yours so slow as compared to the simple python code ? Case # time (sec)
50 148.46
51 120.88
52 189.33
53 204.99
54 674.51
55 441.58
56 945.33
57 1509.22
58 2685.02
59 2300.80
60 4389.98
61 2958.66
62 7802.91
63 10239.27
whatever your code is (which we have not seen as yet  ), basically at some point you are comparing, all what I'm suggesting to you is to try defer comparing as much as possible. Thanks. |
|
|
|
|
|
dextronomous
|
|
September 19, 2019, 12:02:26 AM |
|
Hey guys, especially Telariust, Racminer, BurtW, really impressed by you'r calculation skills, math skills. Who's going to release the exe file first, reading he want's to wait you'r release first, then again, could you guys ellaborate a bit on when this might or will happen thanks in advance, will be waiting for the software. What to do in the meantime, can't do nothing then. Learn some python then.  just almost forgetting another question, when is the tested gpu version there for us readers to review. cheers |
|
|
|
|
racminer
Member
Offline
Activity: 242
Merit: 17
|
|
September 23, 2019, 11:07:58 AM |
|
#105 found !
|
|
|
|
|
ZafotheNinja
Jr. Member
Offline
Activity: 30
Merit: 1
|
|
September 25, 2019, 03:12:34 AM |
|
This seems like a noobish question but, with the scp256k1 curve, what is the formula for calculating the Galois field?
The bitcoin wiki gives the paramaters for the curve, but I haven't been able to find a formula for how the parameters interact.
Any extra reading materials would also be helpful.
|
|
|
|
|
BurtW (OP)
Legendary
Offline
Activity: 2646
Merit: 1130
All paid signature campaigns should be banned.
|
|
September 25, 2019, 12:47:43 PM |
|
This seems like a noobish question but, with the secp256k1 curve, what is the formula for calculating the Galois field?
The bitcoin wiki gives the parameters for the curve, but I haven't been able to find a formula for how the parameters interact.
Any extra reading materials would also be helpful.
Not sure exactly what you are asking here. First of all the points on the elliptical curve for a group, not a field. Here is a pretty good primer on the defined addition operation for the group. https://hackernoon.com/what-is-the-math-behind-elliptic-curve-cryptography-f61b25253da3 |
Our family was terrorized by Homeland Security. Read all about it here: http://www.jmwagner.com/ and http://www.burtw.com/ Any donations to help us recover from the $300,000 in legal fees and forced donations to the Federal Asset Forfeiture slush fund are greatly appreciated! |
|
|
pooya87
Legendary
Offline
Activity: 3430
Merit: 10497
|
|
September 27, 2019, 07:02:14 AM |
|
What I'm trying to figure out is, how to express this point addition/multiplication in algebraic terms.
did you look at the pictures in that article with the curves and the lines? if you haven't first do that and then come back and read on. mainly this: 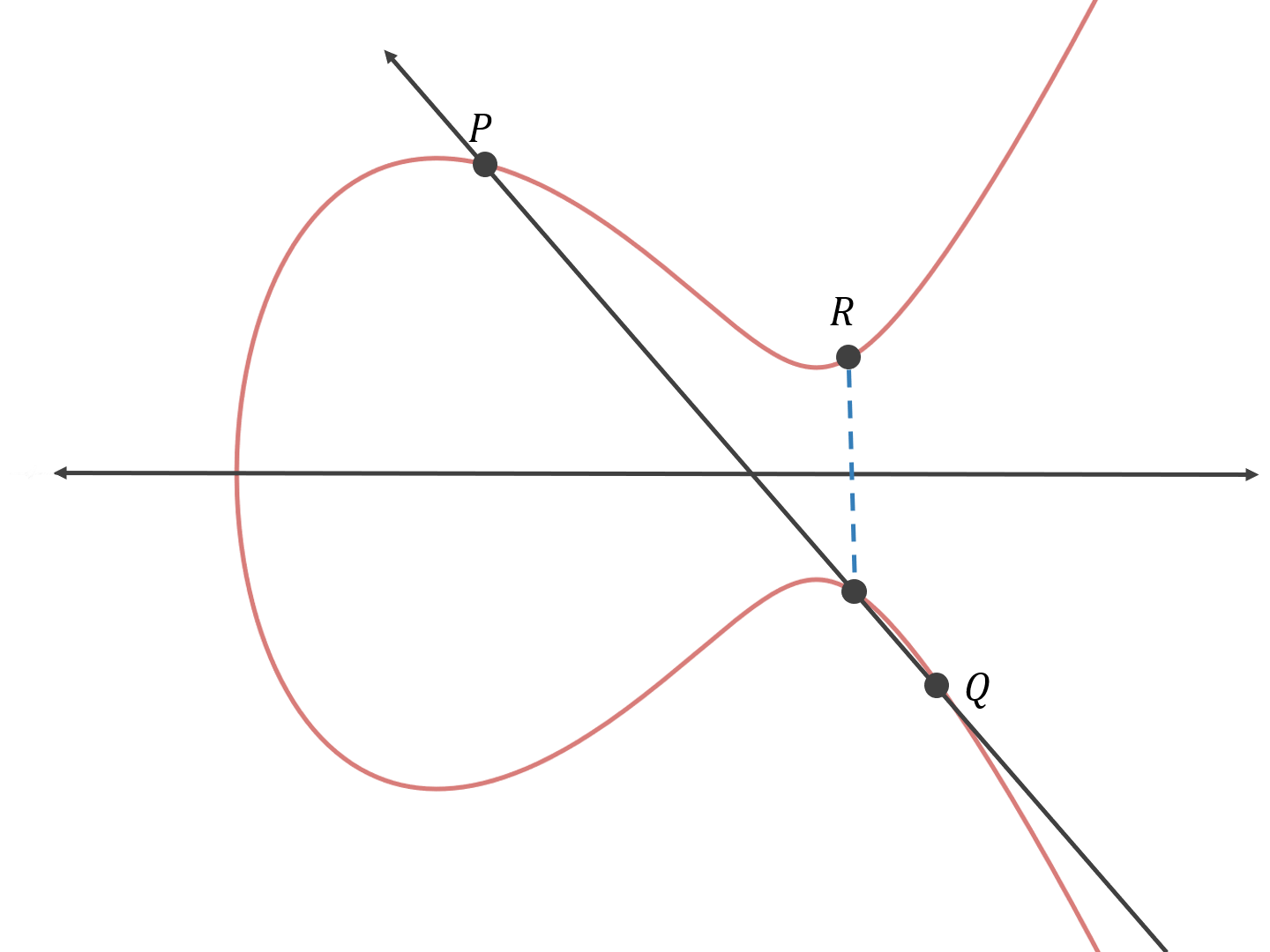 the point addition is basically defined as drawing a line between the two points, finding the third point (there is always a third point "intersection" when the other 2 points are on the curve) on the curve and negating that. we call the point without a name S on this picture, and first have to find S then find R from that. first a line between the two points and find the "formula" for that line. since the line is straight the formula is y = mx + a where m is the slope also known as λ. λ = (y q-y p)/(x q-x p) and y = y p + λ(x-x p) is that formula using point P (we can use any of the other 3 points too). if we put it in the elliptic curve formula (y 2 = x 3 + ax + b) we get: x 3 − λ 2x 2 + a+2λ 2x p −2λy px + (b−(λx p−y p) 2) = 0 we know thanks to Vieta that in a quadratic equation ax 3 + bx 2 + cx + d =0 that the sum of roots r 1, r 2 and r 3 is equal to -b/a so in our case sum of three values for x which are the coordinates of the 3 points on the straight line is equal to -(-λ 2/1)= λ 2hence we can calculate the x coordinate of point S: x p+x q+x s=λ 2 => x s=λ 2−x p−x q. and since x s=x r we have found the x coordinate of our point R which is here: https://en.wikipedia.org/wiki/Elliptic_curve_point_multiplication#Point_additionto find its y coordinate of S we simply use the line's formula and since y r=-y s we just have to flip the sign hence the y r formula in wikipedia link 2 additional things to note: 1. point doubling aka adding a point to itself is the same math with only one difference: x and y coordinate of P and Q are the same. 2. all the math here is modular (mod curve's prime) |
.
.BLACKJACK ♠ FUN. | | | ███▄██████
██████████████▀
████████████
█████████████████
████████████████▄▄
░█████████████▀░▀▀
██████████████████
░██████████████
█████████████████▄
░██████████████▀
████████████
███████████████░██
██████████ | | CRYPTO CASINO &
SPORTS BETTING | | │ | | │ | ▄▄███████▄▄
▄███████████████▄
███████████████████
█████████████████████
███████████████████████
█████████████████████████
█████████████████████████
█████████████████████████
███████████████████████
█████████████████████
███████████████████
▀███████████████▀
███████████████████ | | .
|
|
|
|
BurtW (OP)
Legendary
Offline
Activity: 2646
Merit: 1130
All paid signature campaigns should be banned.
|
|
September 27, 2019, 11:21:56 AM |
|
Ah, thanks for the link, it definitely helped clear a few things up.
I understand the formula y^2 = x^3+7 generates the secp256k1 curve, and that bitcoin specifies a point on that curve as a generator/base point.
As far as I've found, this base point is added with itself x times, where x is your private key, to get the public key. What I'm trying to figure out is, how to express this point addition/multiplication in algebraic terms.
Thanks pooya87 for your very detailed answer. Also, if you like to look at code instead of mathematical equations we just wrote the code for point addition using the secp256k1 library and posted it. Here is that post repeated here. You can read through the code and see that this code implements exactly the mathematical equations that pooya87 detailed in their post. We have our first pass of our A+A->A implementation which we did from scratch using only the wikipedia page for the formula. It runs and is faster but we have not finish optimizing it - we just got through the bugs and got it to run. Since Telariust shared his implementation we will share ours. I am very surprised this function is not already a standard function in the secp256k1 library. We are still running tests and optimizing our entire system. I will post the results in the OP when the runs finish and we will see how much faster it is in our implementation. static void secp256k1_add_ge_var(secp256k1_ge * const r, const secp256k1_ge * const P, const secp256k1_ge * const Q)
{
// From https://en.wikipedia.org/wiki/Elliptic_curve_point_multiplication
//
// P + Q, P not equal to Q:
// l = (Qy - Py) / (Qx - Px)
// Rx = l² - Px - Qx
// Ry = l(Px - Rx) - Py
//
// P + Q, P equal to Q:
// l = (3Px² + a) / 2Py, but for secp256k1: y² = x³ + 7 so a = 0 and
// l = 3Px² / 2Py
// Rx = l² - Px - Qx
// Ry = l(Px - Rx) - Py
//
// Rewritten in terms of the available secp256k1_fe operations:
//
// r = -a static void secp256k1_fe_negate(secp256k1_fe *r, const secp256k1_fe *a, int m);
// Set a field element equal to the additive inverse of another.
// Takes a maximum magnitude of the input as an argument.
// The magnitude of the output is one higher.
//
// r += a static void secp256k1_fe_add(secp256k1_fe *r, const secp256k1_fe *a);
// Adds a field element to another.
// The result has the sum of the inputs' magnitudes as magnitude.
//
// r = inv(a) static void secp256k1_fe_inv_var(secp256k1_fe *r, const secp256k1_fe *a);
// Sets a field element to be the (modular) inverse of another.
// Requires the input's magnitude to be at most 8.
// The output magnitude is 1 (but not guaranteed to be normalized).
// Potentially faster version of secp256k1_fe_inv, without constant-time guarantee.
//
// r = a * b static void secp256k1_fe_mul(secp256k1_fe *r, const secp256k1_fe *a, const secp256k1_fe * SECP256K1_RESTRICT b);
// Sets a field element to be the product of two others.
// Requires the inputs' magnitudes to be at most 8.
// The output magnitude is 1 (but not guaranteed to be normalized).
// NOTE: r != b, a != b
//
// r *= n static void secp256k1_fe_mul_int(secp256k1_fe *r, int n);
// Multiplies the passed field element with a small integer constant.
// Multiplies the magnitude by that small integer.
//
// r = a * a static void secp256k1_fe_sqr(secp256k1_fe *r, const secp256k1_fe *a);
// Sets a field element to be the square of another.
// Requires the input's magnitude to be at most 8.
// The output magnitude is 1 (but not guaranteed to be normalized).
//
// r %= p static void secp256k1_fe_normalize_var(secp256k1_fe *r);
// Normalize a field element, without constant-time guarantee.
//
// Px, Py, Qx and Qy all start out normalized
// In other words: m(Px), m(Py), m(Qx) and m(Qy) all equal 1
//
// if (P == Q) {
// l = 3Px² / 2Py
// } else {
// l = (Qy - Py) / (Qx - Px)
// }
// Rx = l² - Px - Qx
// Ry = l(Px - Rx) - Py
//
// Common/Reused terms are -Px, -Py and -Qx
//
// nPx = -Px // m(nPx) = 1 + 1 = 2
// nPy = -Py // m(nPy) = 1 + 1 = 2
// nQx = -Qx // m(nQx) = 1 + 1 = 2
//
// if (P == Q) {
//
// // l = 3Px² / 2Py = n / d
//
// n = Px² // m(n) = 1
// n *= 3 // m(n) = 1 * 3 = 3
//
// d = Py // m(d) = 1
// d *= 2 // m(d) = 1 * 2 = 2
//
// } else {
//
// // l = (Qy - Py) / (Qx - Px) = n / d
//
// n = Qy // m(n) = 1
// n += nPy // m(n) = 1 + 2 = 3
//
// d = Qx // m(d) = 1
// d += nPx // m(d) = 1 + 2 = 3
// }
//
// // l = n / d = n * (1 / d)
//
// l = inv(d) // m(l) = 1
// l = n * l // m(l) = 1
//
// // Rx = l² - Px - Qx
//
// Rx = l² // m(Rx) = 1
// Rx += nPx // m(Rx) = 1 + 2 = 3
// Rx += nQx // m(Rx) = 3 + 2 = 5
//
// // Ry = l(Px - Rx) - Py
//
// Ry = -Rx // m(Ry) = 5 + 1 = 6
// Ry += Px // m(Ry) = 6 + 1 = 7
// Ry = l * Ry // m(Ry) = 1
// Ry += nPy // m(Ry) = 1 + 2 = 3
//
// Rx %= p // m(Rx) = 1 and normalized
// Ry %= p // m(Ry) = 1 and normalized
//
// Implement:
secp256k1_ge RR; // Place to temporarily store the result in the case (R == P)
secp256k1_ge * const R = &RR; //
RR.infinity = 0; //
#define secp256k1_fe_cpy(d, s) *d = *s // Dump_fe only turned on for debug
const secp256k1_fe * const Px = &P->x; Dump_fe("Px", Px);
const secp256k1_fe * const Py = &P->y; Dump_fe("Py", Py);
const secp256k1_fe * const Qx = &Q->x; Dump_fe("Qx", Qx);
const secp256k1_fe * const Qy = &Q->y; Dump_fe("Qy", Qy);
secp256k1_fe * const Rx = &R->x;
secp256k1_fe * const Ry = &R->y;
// nPx = -Px // m(nPx) = 1 + 1 = 2
// nPy = -Py // m(nPy) = 1 + 1 = 2
// nQx = -Qx // m(nQx) = 1 + 1 = 2
secp256k1_fe npx;
secp256k1_fe npy;
secp256k1_fe nqx;
secp256k1_fe * const nPx = &npx;
secp256k1_fe * const nPy = &npy;
secp256k1_fe * const nQx = &nqx;
secp256k1_fe_negate(nPx, Px, 1); Dump_fe("nPx", nPx);
secp256k1_fe_negate(nPy, Py, 1); Dump_fe("nPy", nPy);
secp256k1_fe_negate(nQx, Qx, 1); Dump_fe("nQx", nQx);
secp256k1_fe N;
secp256k1_fe D;
secp256k1_fe L;
secp256k1_fe * const n = &N;
secp256k1_fe * const d = &D;
secp256k1_fe * const l = &L;
++cmps;
if (memcmp(P, Q, sizeof(secp256k1_ge)) == 0) {
// // l = 3Px² / 2Py = n / d
//
// n = Px² // m(n) = 1
// n *= 3 // m(n) = 1 * 3 = 3
secp256k1_fe_sqr(n, Px); Dump_fe("n", n);
secp256k1_fe_mul_int(n, 3); Dump_fe("n", n);
// d = Py // m(d) = 1
// d *= 2 // m(d) = 1 * 2 = 2
secp256k1_fe_cpy(d, Py); Dump_fe("d", d);
secp256k1_fe_mul_int(d, 2); Dump_fe("d", d);
} else {
// // l = (Qy - Py) / (Qx - Px) = n / d
//
// n = Qy // m(n) = 1
// n += nPy // m(n) = 1 + 2 = 3
secp256k1_fe_cpy(n, Qy); Dump_fe("n", n);
secp256k1_fe_add(n, nPy); Dump_fe("n", n);
//
// d = Qx // m(d) = 1
// d += nPx // m(d) = 1 + 2 = 3
secp256k1_fe_cpy(d, Qx); Dump_fe("d", d);
secp256k1_fe_add(d, nPx); Dump_fe("d", d);
}
//
// // l = n / d = n * (1 / d)
//
// l = inv(d) // m(l) = 1
// l = n * l // m(l) = 1
secp256k1_fe_inv_var(l, d); Dump_fe("l", l);
secp256k1_fe_mul(l, l, n); Dump_fe("l", l);
// // Rx = l² - Px - Qx
//
// Rx = l² // m(Rx) = 1
// Rx += nPx // m(Rx) = 1 + 2 = 3
// Rx += nQx // m(Rx) = 3 + 2 = 5
//
secp256k1_fe_sqr(Rx, l); Dump_fe("Rx", Rx);
secp256k1_fe_add(Rx, nPx); Dump_fe("Rx", Rx);
secp256k1_fe_add(Rx, nQx); Dump_fe("Rx", Rx);
// // Ry = l(Px - Rx) - Py
//
// Ry = -Rx // m(Ry) = 5 + 1 = 6
// Ry += Px // m(Ry) = 6 + 1 = 7
// Ry = l * Ry // m(Ry) = 1
// Ry += nPy // m(Ry) = 1 + 2 = 3
secp256k1_fe_negate(Ry, Rx, 5); Dump_fe("Ry", Ry);
secp256k1_fe_add(Ry, Px); Dump_fe("Ry", Ry);
secp256k1_fe_mul(Ry, Ry, l); Dump_fe("Ry", Ry);
secp256k1_fe_add(Ry, nPy); Dump_fe("Ry", Ry);
// Rx %= p // m(Rx) = 1 and normalized
// Ry %= p // m(Ry) = 1 and normalized
secp256k1_fe_normalize_var(Rx); Dump_fe("Rx", Rx);
secp256k1_fe_normalize_var(Ry); Dump_fe("Ry", Ry);
// secp256k1_ge * const r is passed in
// secp256k1_ge * const R = &RR where
// secp256k1_ge RR is on the stack
//
// r->x = R->x;
// r->y = R->y;
// r->infinity = R->infinity;
*r = *R;
}
NOTE: fixed a couple of minor bugs in the above code. It should be good to go now. |
Our family was terrorized by Homeland Security. Read all about it here: http://www.jmwagner.com/ and http://www.burtw.com/ Any donations to help us recover from the $300,000 in legal fees and forced donations to the Federal Asset Forfeiture slush fund are greatly appreciated! |
|
|
usama12
Newbie
Offline
Activity: 9
Merit: 0
|
|
September 29, 2019, 07:05:50 AM |
|
Hi BurtW I have gone through whole thread and its very interesting and informative. I am interested to get listed on your list of testers.
|
|
|
|
|
|
MrFreeDragon
|
|
October 01, 2019, 11:01:05 AM |
|
In the case of the puzzle transactions a publickey should be in the space 2^(bit-1) to (2^bit)-1,
we can just calculate 2^(bit-1) + 2^(bit-2) as a point and subtract it from our known publickey.
Our new generated public key will be within the space(ORDER - 2^(bit-2)) to 2 ^(bit-2).
Now we only have to check the x values from space 0 to 2^(bit-2).
When we find the solution to the calculated publickey, the solution to our orginal publickey will be either solution or (ORDER - solution) + subtraction factor.
Can you please clarify there is the benefit in your method? You are saying that "Now we only have to check the x values from space 0 to 2^(bit-2)", so we need to check 2^(bit-2) combinations. It is just 2 times less that the brutforce of the full range. Not effective. However in Pollard method we should make only sqr (2^(bit-1)) operations, which is much much less than in your method. Example: for 110 bit key, you suggest to check 2^108 combinations, but in Pollard method we need only 2^54.5 operations. So why is your method valuable? What is the main idea and advantage? |
|
|
|
st0ffl
Newbie
Offline
Activity: 12
Merit: 0
|
|
October 01, 2019, 01:52:38 PM
Last edit: October 01, 2019, 09:18:35 PM by st0ffl |
|
Can you please clarify there is the benefit in your method? You are saying that "Now we only have to check the x values from space 0 to 2^(bit-2)", so we need to check 2^(bit-2) combinations. It is just 2 times less that the brutforce of the full range. Not effective.
However in Pollard method we should make only sqr (2^(bit-1)) operations, which is much much less than in your method.
Example: for 110 bit key, you suggest to check 2^108 combinations, but in Pollard method we need only 2^54.5 operations.
So why is your method valuable? What is the main idea and advantage?
The idea is of course to only make sqr(2^(bit-2)) operations. for #50: python pollard-kangaroo-multi.py 50 03f46f41027bbf44fafd6b059091b900dad41e6845b2241dc3254c7cdd3c5a16c6 should be equivalent to python pollard-kangaroo-multi.py 8:FFFFFFFFFFFF 02bc9d041a4839d3bef61e319cd02d3b177292ccb79ed27c1bf6043ab0ec635bfd (8 is by default minimum bit using pollard-kangaroo-multi.py) edit: sorry was the wrong pubkey for #50 in first place |
|
|
|
|
st0ffl
Newbie
Offline
Activity: 12
Merit: 0
|
|
October 01, 2019, 02:48:36 PM
Last edit: October 01, 2019, 03:37:14 PM by st0ffl |
|
need detail explain for this area
example to test:
from
#50 = 03f46f41027bbf44fafd6b059091b900dad41e6845b2241dc3254c7cdd3c5a16c6
to
0-48 02bc9d041a4839d3bef61e319cd02d3b177292ccb79ed27c1bf6043ab0ec635bfd
steps guide
1. Create ECPoint "p" from 03f46f41027bbf44fafd6b059091b900dad41e6845b2241dc3254c7cdd3c5a16c6 2. Calculate subtraction space "sub"= (2^(bit-1)) + (2^(bit-2)); 3. Create ECPoint from sub "subP" = G.Multiply(sub); 4. Create ECPoint new "newP" = p.Subtract(subP); 5. Create compressed publicKey string "newPK" = newP.GetEncoded(True).ToString(); 6. Calculate your "newkeySpaceU" value = (2^(bit-2))-1 7. Convert newkeySpaceU from decimal to hexadecimal string= newKeySpace.ToString("X"); 8. Use pollard-kangaroo-multi.py 8:newkeySpaceU newPubkey (Correctly keySpace L should be always 0, by default 8 is minimum) 9. Convert your result prvkey output from hexadecimal to BigInteger "res" 10.Calculate "offset1" = res + sub and calculate "offset2" = ((Order -res) + sub)%Order 11. Generate new ECPOINT "offset1P" and "offset2P" = G.Multiply(offset1) and G.Multiply(offset2) 12. Compare "offset1P" to "p" = if(p.Equals(offset1P)) offset1 is my prvkey; else offset2 is my privkey |
|
|
|
|
st0ffl
Newbie
Offline
Activity: 12
Merit: 0
|
|
October 01, 2019, 07:59:47 PM |
|
sending you PM, your need allow my id for send PM to you
i changed the settings to allow newbie messages |
|
|
|
|
st0ffl
Newbie
Offline
Activity: 12
Merit: 0
|
|
October 01, 2019, 09:52:11 PM |
|
Here is another example of #40
#40 sqr(2^(bit-1))
python pollard-kangaroo-multi.py 40
//privkey = 1003651412950
#40 sqr(2^(bit-2))
python pollard-kangaroo-multi.py 8:3FFFFFFFFF 028dfd0e801ed8d495b6a0b68b38fba4f32d7423af363c717cca6c2ebd1e11a399
//privkey = 179017692118
Addfactor: 824633720832
//result1 = 1003651412950 true
|
|
|
|
|
racminer
Member
Offline
Activity: 242
Merit: 17
|
|
October 01, 2019, 10:35:57 PM
Last edit: October 02, 2019, 03:01:29 PM by racminer |
|
-----------------------------------------------------------------
@Telariust Very nice work. I've tried your C code and it hops two times faster than 57fe python code. I can't figure out where exactly do you store the tame and wild kangaroos as it is done in the "tame.txt" and "wild.txt" files for the python code. thanks for your help |
|
|
|
|
|
MrFreeDragon
|
|
October 02, 2019, 12:12:22 AM |
|
Here is another example of #40
#40 sqr(2^(bit-1))
python pollard-kangaroo-multi.py 40
//privkey = 1003651412950
#40 sqr(2^(bit-2))
python pollard-kangaroo-multi.py 8:3FFFFFFFFF 028dfd0e801ed8d495b6a0b68b38fba4f32d7423af363c717cca6c2ebd1e11a399
//privkey = 179017692118
Addfactor: 824633720832
//result1 = 1003651412950 true
This method is not universal. It depends on the 2nd bit actually  So, for #40 it works. But for #35 for example it will not work. For #50 it will not work as well. First bit is always 1 in these transaction chalange keys. But the 2nd bit could be 1 or 0 (as any other bit). You decrease the bit power considering that the 2nd bit is 1, but it is not obligitary. It also could be 0. |
|
|
|
racminer
Member
Offline
Activity: 242
Merit: 17
|
|
October 02, 2019, 12:34:20 AM |
|
Here is another example of #40
#40 sqr(2^(bit-1))
python pollard-kangaroo-multi.py 40
//privkey = 1003651412950
#40 sqr(2^(bit-2))
python pollard-kangaroo-multi.py 8:3FFFFFFFFF 028dfd0e801ed8d495b6a0b68b38fba4f32d7423af363c717cca6c2ebd1e11a399
//privkey = 179017692118
Addfactor: 824633720832
//result1 = 1003651412950 true
824633720832 is just 0xC000000000 179017692118 is 0x29AE4933D6 1003651412950 is 0xE9AE4933D6 So 0xC000000000 is just the mid point of the normal #40 range 8000000000:FFFFFFFFFF in other words the #40 sqr(2^(bit-2)) range you are mentioning is just the position of the private key from the mid-point. You are not doing less work, you've just changed the origin. Instead of working with the tame kangaroo matching the private key solution, you are working with the corresponding wild kangaroo. |
|
|
|
|
|


