odolvlobo
Legendary

 Offline Offline
Activity: 4298
Merit: 3214

|
 |
April 11, 2020, 06:22:23 PM |
|
@odolvlobo i have a question.
You gave me public keys whose private keys are in the range 8000000000000000:ffffffffffffffff
So those you previously brute force this range.
if you have all keys in this range why you do not take transaction #63 from bitcoin pazle?
I didn't brute-force the private keys. I generated them randomly and gave you their public keys. |
Join an anti-signature campaign: Click ignore on the members of signature campaigns.
PGP Fingerprint: 6B6BC26599EC24EF7E29A405EAF050539D0B2925 Signing address: 13GAVJo8YaAuenj6keiEykwxWUZ7jMoSLt
|
|
|
|
|
|
|
|
You get merit points when someone likes your post enough to give you some. And for every 2 merit points you receive, you can send 1 merit point to someone else!
|
|
|
Advertised sites are not endorsed by the Bitcoin Forum. They may be unsafe, untrustworthy, or illegal in your jurisdiction.
|
|
|
|
Jean_Luc
|
|
April 11, 2020, 07:53:52 PM |
|
So BSGS can`t be launched with n=0xfffffffffffffffffffffffffffffffebaaedce6af48a03bbfd25e8cd0364141
You can use this algorithm with the memory you want. Of course, if you want to use it on the full range, you won't be able to get running time in O(sqrt(n)) because you won't have enough memory. BSGS is a simple time memory/tradeoff, if you have enough memory you can get the best complexity in O(sqrt(n)), if you don't have memory (you don't use a lookup table) then the algorithm get a complexity in O(n). For the basic BSGS, If x is the size of the lookup table, and n the search space size, the total number of needed group operations is x (to fill the memory) + n/x (to solve the key) and the minimum of this function is obtained when x = sqrt(n), then the total number of group operation is 2*sqrt(n). We neglect here the time spent by the search (or the insertion) in the lookup table which can be done very efficiently by combining hash table and binary search. Ex: for n=2^64, we see that the minimum is well at x=2^32 (~4.295E9) 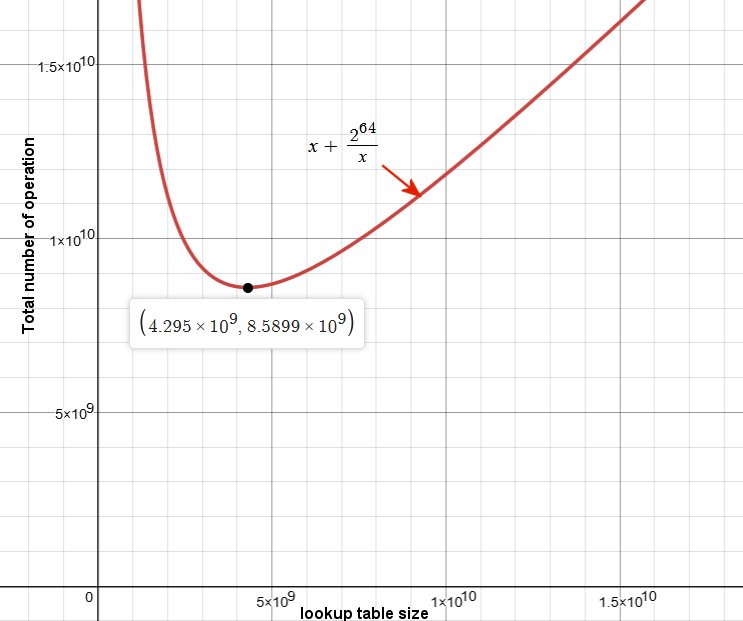 |
|
|
|
|
|
Etar (OP)
|
|
April 11, 2020, 08:52:54 PM
Last edit: April 11, 2020, 09:11:24 PM by Etar |
|
ok, thanks for answers.
but BSGS moves back from a known public key. This algorithm, as I understand it, subtracts mP from Q. That is why it is called "meet in the middle"
It is not the same..
if public key for example >2^254 than you will wait many-many time while mP will be in the table and you cant influence it in any way.
While my algorithm has a start public key. Of course, if it starts with private key at 0x01, then the residence time will be the same for both algorithms.
But if I start with key 0x1000000000000000000000000000000000000000000000000000000000000000, for example, then I will quickly find the key
|
|
|
|
|
|
Jean_Luc
|
|
April 11, 2020, 09:14:32 PM
Last edit: April 11, 2020, 09:40:22 PM by Jean_Luc |
|
"meet in the middle" is a generic term to design attack algorithm that makes time/memory tradeoff to reduce time complexity of basic brute force attack.
In that case, the best tradeoff brings O(sqrt(n)).
The algorithm that I show you on the power point, is a basic one, lots of variants exist... since more than 50 years...
|
|
|
|
|
gmaxwell
Moderator
Legendary

 Offline
Offline
Activity: 4158
Merit: 8411

|
|
April 12, 2020, 07:28:55 AM |
|
One thing to keep in mind for these TMTO approaches is that the pre-computation size can be amortized across multiple problems. So, for example, on a 2TB ram (plus a few TB of disk) host you can build up a 2^38 ish-sized table and reuse it against multiple problems... and solve each additional 64-bit search with 2^25 operations each.
The optimizations to get low memory don't work quite as well for amortizing multiple problems, or at least are much harder to implement.
|
|
|
|
|
|
Jean_Luc
|
Just curious, I made a small program that does this. I used a 24bits hash table (no binary search) and a table of 2^30 point (~9GB), the hash table is not well optimized for insertion in order to save memory and to avoid fragmentation (not constant speed). It is obviously possible to make further optimizations to speed it up. I ran this program on an old Xeon X5647 2.93GHz with 12GB of RAM. It takes 9min to fill the 2^30 baby step table and ~32min to browse the full 2^64 range so it can solve the 16 keys of odolvlobo in ~9h00 (max). I published the code: https://github.com/JeanLucPons/BSGSHere the key #10 and #11 of the odolvlobo set (expressed in compressed format) BSGS v1.0
BabyStep:0x40000000
Start:49DCCFD96DC5DF56487436F5A1B18C4F5D34F65DDB48CB5E0000000000000000
Stop :49DCCFD96DC5DF56487436F5A1B18C4F5D34F65DDB48CB5EFFFFFFFFFFFFFFFF
Keys :7
Number of CPU thread: 8
BabyStep Thread 2: 0x10000001 -> 0x18000000
BabyStep Thread 4: 0x20000001 -> 0x28000000
BabyStep Thread 1: 0x8000001 -> 0x10000000
BabyStep Thread 0: 0x1 -> 0x8000000
BabyStep Thread 5: 0x28000001 -> 0x30000000
BabyStep Thread 3: 0x18000001 -> 0x20000000
BabyStep Thread 6: 0x30000001 -> 0x38000000
BabyStep Thread 7: 0x38000001 -> 0x40000000
[1.82 MKs][Cnt 2^30.00][09:03][8575.9MB]
GiantStep Thread 1: 49DCCFD96DC5DF56487436F5A1B18C4F5D34F65DDB48CB5E2000000000000000
GiantStep Thread 0: 49DCCFD96DC5DF56487436F5A1B18C4F5D34F65DDB48CB5E0000000000000000
GiantStep Thread 2: 49DCCFD96DC5DF56487436F5A1B18C4F5D34F65DDB48CB5E4000000000000000
GiantStep Thread 3: 49DCCFD96DC5DF56487436F5A1B18C4F5D34F65DDB48CB5E6000000000000000
GiantStep Thread 4: 49DCCFD96DC5DF56487436F5A1B18C4F5D34F65DDB48CB5E8000000000000000
GiantStep Thread 5: 49DCCFD96DC5DF56487436F5A1B18C4F5D34F65DDB48CB5EA000000000000000
GiantStep Thread 6: 49DCCFD96DC5DF56487436F5A1B18C4F5D34F65DDB48CB5EC000000000000000
GiantStep Thread 7: 49DCCFD96DC5DF56487436F5A1B18C4F5D34F65DDB48CB5EE000000000000000
[8.57 MKs][Cnt 2^33.37][21:38][8575.9MB]
Key# 10 Pub: 0x02332A02CA42C481EAADB7ADB97DF89033B23EA291FDA809BEA3CE5C3B73B20C49
Priv: 0x49DCCFD96DC5DF56487436F5A1B18C4F5D34F65DDB48CB5E54CAD3CFBC2A9C2B
[8.58 MKs][Cnt 2^32.74][13:53][8575.9MB]
Key# 11 Pub: 0x02513981849DE1A1327DEF34B51F5011C5070603CA22E6D868263CB7C908525F0C
Priv: 0x49DCCFD96DC5DF56487436F5A1B18C4F5D34F65DDB48CB5E0D5ECCC38D0230E6
|
|
|
|
|
odolvlobo
Legendary
Offline
Activity: 4298
Merit: 3214
|
|
April 15, 2020, 05:39:07 PM |
|
I have to say that this thread has been enlightening. I honestly had no idea how powerful these algorithms can be. BurtW posted last summer about how he and his daughter were looking at the Pollard Kangaroo algorithm. The results they reported did not seem impressive, so I lost interest. https://bitcointalk.org/index.php?topic=5173445.0 |
Join an anti-signature campaign: Click ignore on the members of signature campaigns.
PGP Fingerprint: 6B6BC26599EC24EF7E29A405EAF050539D0B2925 Signing address: 13GAVJo8YaAuenj6keiEykwxWUZ7jMoSLt
|
|
|
|
Etar (OP)
|
|
April 15, 2020, 07:53:59 PM |
|
Much harder with the GPU.
Implementing binary search on a GPU is nearly impossible in the right way.
For example my GPU can do 1.2G operation per second. I mean add point operation.
But as soon as the BSGS algorithm is added and a search is made in the sorted table, the main hashrate drops sharply.
Look at results..
GPU #0 1240MKey/s x1
GPU #0 499MKey/s x1048576
GPU #0 360MKey/s x4194304
GPU #0 113MKey/s x16777216
GPU #0 70MKey/s x33554422
Even 70 million giant steps multiplied by 32 million babyss looks quite sad against the background of the CPU.
When calculating on the CPU, the table size almost does not affect the main hashrate.
Because the number of samples from the sorting table is Log2 of the size of the table.
But with the GPU this does not work out.
|
|
|
|
|
|
Jean_Luc
|
|
April 15, 2020, 08:56:59 PM |
|
How did you implement the binary search on the GPU ? Iterative or recursive ?
I already implemented binary searches on GPU without having such an issue.
|
|
|
|
|
MikeJ_NpC
Member
 Offline
Offline
Activity: 107
Merit: 10
if you want to lie *cough*use your data; not mine.
|
|
April 16, 2020, 05:26:23 AM |
|
I think its rather interesting to say the least despite the non hashing attribute.
Furthermore, i have a nightmare with all the data applicable to solve, more than the basic set people tout, PK ranges Key-space, Nonce, etc etc in dec.
So you want a puzzle you can do one that i need to resolve. I am at a impasse with my own attempts and have had a company with QC ability attempt which they came up short for a few reasons internally not in reference to my wallet. Hence, if Etar or Greg would like to take a look or anyone who can resolve this (requires experience) i would be god dam thankful... been years and im frankly fed up and heard it all. Send a PM..
If there is a need to solve a problem and validate this model, mine would be it... not going to have more data sets than this....
BUT this approach is one i haven't seen ... despite the rumblings from the elders ... i do concur more needs to be disclosed but not to the point where he ruins his time put into the model.
anyways cheers...
|
If Karma is a bitch, then god is a woman. I ask to know, not to be screwed or hear trite excuses (after the fact) which a 3rd grader could do better on. If you give your word, keep it atleast..
|
|
|
|
Etar (OP)
|
|
April 16, 2020, 05:43:08 AM |
|
How did you implement the binary search on the GPU ? Iterative or recursive ?
I already implemented binary searches on GPU without having such an issue.
I tried in different ways. Here is an example where the counter variable is used, which is responsible for the number of iterations over the sorted table. This is so that there are no branches. It should be the log2 of the size of the table. if table have size 2^20 than counter=20 With this approach, the key search is always the same in time and equal to the sampling time multiplied by counter.func (.reg .b32 eq, .reg .b32 pos) FOUNDINSORT(.reg .b32 a0, .reg .b32 a1, .reg .b32 a2, .reg .b32 a3, .reg .b32 a4, .reg .b32 a5, .reg .b32 a6, .reg .b32 a7, .reg .b64 _arr, .reg .b32 beginrange, .reg .b32 endrange)
{
.reg .pred p, k;
.reg .b32 temp, iseq, center, counter;
.reg .b64 _Pointarray;
mov.u32 counter,20;
xor.b32 eq,eq;
xor.b32 pos,pos;
$FFFOUNDINSORTmain:
setp.hi.u32 p,counter,0;
@!p bra.uni $FFFOUNDINSORTexit;
//main loop
//center= beginrange+(endrange-beginrange)/2
sub.u32 center,endrange,beginrange;
shr.b32 center,center,1;
add.u32 center,center,beginrange;
mul.wide.u32 _Pointarray,center,32;
add.u64 _Pointarray,_Pointarray,_arr;
call.uni (iseq), EQUILLESSMOREHALF, (a0, a1, a2, a3, a4, a5, a6, a7, _Pointarray);
setp.eq.u32 p,iseq,2; // findkey >Pointarray[center]
add.u32 temp,center,1;
setp.lo.u32 k,center,endrange;
selp.u32 temp,temp,endrange,k;
selp.u32 beginrange,temp,beginrange,p;
setp.eq.u32 p,iseq,1; //findkey <Pointarray[center]
sub.u32 temp,center,1;
//check if center is not zero
setp.hi.u32 k,center,0;
selp.u32 temp,temp,beginrange,k;
setp.hs.u32 k,temp,beginrange;
selp.u32 temp,temp,beginrange,k;
selp.u32 endrange,temp,endrange,p;
setp.eq.u32 p,iseq,0;// findkey =Pointarray[center]
selp.u32 eq,1,0,p;
selp.u32 pos,center,0,p;
sub.u32 counter,counter,1;
bra.uni $FFFOUNDINSORTmain;
$FFFOUNDINSORTexit:
ret.uni;
}
|
|
|
|
|
|
Jean_Luc
|
|
April 16, 2020, 06:11:04 AM |
|
There is an horrible call in your loop. Try to remove it and implement the comparison locally.
|
|
|
|
|
|
Etar (OP)
|
|
April 16, 2020, 06:20:37 AM
Last edit: April 16, 2020, 06:40:48 AM by Etar |
|
There is an horrible call in your loop. Try to remove it and implement the comparison locally.
I think that PTX compiler unroll function, but any way i unroll EQUILLESSMOREHALF function to main loop. Result the same as early.. I think that this issues in cuda driver api (specifically in their library cuda.lib). Because random access to memory is happening here. And I have already encountered this before (when the miner wrote for the ethereum. On Windows 7, the miner gave 24Mx with 1063 cards, and on Windows 10 only 4mx  ). On windows 7, random access to memory worked fine on windows 10 no. I then could not defeat it then. .func (.reg .b32 eq, .reg .b32 pos) FOUNDINSORT(.reg .b32 a0, .reg .b32 a1, .reg .b32 a2, .reg .b32 a3, .reg .b32 a4, .reg .b32 a5, .reg .b32 a6, .reg .b32 a7, .reg .b64 _arr, .reg .b32 beginrange, .reg .b32 endrange)
{
.reg .pred p, k;
.reg .b32 temp, iseq, center, counter;
.reg .b64 _Pointarray;
.reg .b32 f0, f1, f2;
.reg .b32 %b<4>;
mov.u32 counter,20;
xor.b32 eq,eq;
xor.b32 pos,pos;
$FFFOUNDINSORTmain:
setp.hi.u32 p,counter,0;
@!p bra.uni $FFFOUNDINSORTexit;
//main loop
//center= beginrange+(endrange-beginrange)/2
sub.u32 center,endrange,beginrange;
shr.b32 center,center,1;
add.u32 center,center,beginrange;
mul.wide.u32 _Pointarray,center,32;
add.u64 _Pointarray,_Pointarray,_arr;
//call.uni (iseq), EQUILLESSMOREHALF, (a0, a1, a2, a3, a4, a5, a6, a7, _Pointarray);
// try to use cmp localy
mov.u32 f0,0x00; //equil
mov.u32 f1,0x01; //less
mov.u32 f2,0x02; //more
ld.global.v4.u32 {%b0, %b1, %b2, %b3},[_Pointarray];
setp.hi.u32 p,a0,%b0;
selp.u32 f1,f2,f1,p;
setp.eq.u32 p,a0,%b0;
selp.u32 f0,f0,f1,p;
selp.u32 f2,f2,f1,p;
setp.hi.u32 p,a1,%b1;
selp.u32 f1,f2,f1,p;
setp.eq.u32 p,a1,%b1;
selp.u32 f0,f0,f1,p;
selp.u32 f2,f2,f1,p;
setp.hi.u32 p,a2,%b2;
selp.u32 f1,f2,f1,p;
setp.eq.u32 p,a2,%b2;
selp.u32 f0,f0,f1,p;
selp.u32 f2,f2,f1,p;
setp.hi.u32 p,a3,%b3;
selp.u32 f1,f2,f1,p;
setp.eq.u32 p,a3,%b3;
selp.u32 iseq,f0,f1,p;
//cmp localy end
setp.eq.u32 p,iseq,2; // findkey >Pointarray[center]
add.u32 temp,center,1;
setp.lo.u32 k,center,endrange;
selp.u32 temp,temp,endrange,k;
selp.u32 beginrange,temp,beginrange,p;
setp.eq.u32 p,iseq,1; //findkey <Pointarray[center]
sub.u32 temp,center,1;
//check if center is not zero
setp.hi.u32 k,center,0;
selp.u32 temp,temp,beginrange,k;
setp.hs.u32 k,temp,beginrange;
selp.u32 temp,temp,beginrange,k;
selp.u32 endrange,temp,endrange,p;
setp.eq.u32 p,iseq,0;// findkey =Pointarray[center]
selp.u32 eq,1,0,p;
selp.u32 pos,center,0,p;
sub.u32 counter,counter,1;
bra.uni $FFFOUNDINSORTmain;
$FFFOUNDINSORTexit:
ret.uni;
}
Report to moderator
|
|
|
|
|
|
Jean_Luc
|
|
April 16, 2020, 06:37:09 AM |
|
I passed my hashtable to a hash size of 25bit (always 2^30 points inside), i win 20% of speed for a 500MB overhead.
Edit:
Concerning GPU the access to global memory is slower than local memory but I'm surprised that it is so slow in your case.
For other programs, i implemented binary search on global memory (millions of items) with very good performances.
In that case a hashtable is better than binary search.
|
|
|
|
|
|
Etar (OP)
|
|
April 16, 2020, 06:43:10 AM
Last edit: April 16, 2020, 07:06:49 AM by Etar |
|
I passed my hashtable to a hash size of 25bit (always 2^30 points inside), i win 20% of speed for a 500MB overhead.
Edit:
Concerning GPU the access to global memory is slower than local memory but I'm surprised that it is so slow in your case.
For other programs, i implemented binary search on global memory (millions of items) with very good performances.
In that case a hashtable is better than binary search.
It is clear that if you do not check all 32 bytes, but only 16 bytes or 8 bytes in general, then the speed will be higher. it is natural. Nevertheless, this does not justify such a sharp drop in the hashrate as the table grows. Indeed, in fact, a 2-fold increase in the table adds only 1 additional sample. Edit: if I correctly understood the logic of your code. That is when the public key is calculated. You look at the first 3 bytes of the key in the hash table. If 3 bytes of key are there, then you get offset of start private key>> add offset to start private key>>compute public key>> compare public keys. But 24 bits is very small - it is a lot of collisions |
|
|
|
|
|
Jean_Luc
|
|
April 16, 2020, 07:17:15 AM
Last edit: April 16, 2020, 07:50:38 AM by Jean_Luc |
|
This problem is typically a time memory trade off problem so the goal is to find all best time memory tradeoff.
I store only 40 bits for the generator index (so 2^40 key max in my hash table) and 24 (+ 25 bits) of the x value. 64 bits per items and an array of 2^25 pointers + 2 * 2^25 short arrays.
So i get few false collisions (one every 2^(49-30) giant steps in average) that i need to check but I win lots of memory, my giant step is much larger.
I'm able to browse the 64bit range in 24min with my 9 year old Xeon (12GB)
|
|
|
|
|
|
MrFreeDragon
|
|
April 16, 2020, 12:03:15 PM |
|
-snip-
I store only 40 bits for the generator index (so 2^40 key max in my hash table) and 24 (+ 25 bits) of the x value. 64 bits per items and an array of 2^25 pointers + 2 * 2^25 short arrays.
-snip-
How and where can you store all 2^40 keys? |
|
|
|
|
Jean_Luc
|
|
April 16, 2020, 12:39:56 PM
Last edit: April 16, 2020, 12:50:52 PM by Jean_Luc |
|
How and where can you store all 2^40 keys?
I store only 49bits (25+24) per key (using a HASH_SIZE of 25 in https://github.com/JeanLucPons/BSGS/blob/master/HashTable.h). I accept to have few false collisions and to make little more calculations to handle them. Each item in the table is a 64bits item, 40 bit for the generator index and 24 bit for a part of the key. I choose this maximum of 40 bit (32+8) because more than 2^32 keys is possible but you're right 2^40 can be decreased and few bits can be used for the key and decrease the probability of false collision. This program is here to be modified and adapted... |
|
|
|
|
|
Jean_Luc
|
I did few optimizations (commited to github), I reached 13.6M giant steps of 2^30 per second on my Xeon X5647 2.93GHz with 12GB of RAM. It solves the 16 keys of the odolvlobo's set in 3:35:53 from scratch, I mean without any precomputation. If I convert to the Etar's unit: It does 14.6 PKey/s. I posted the result in the readme of my program: https://github.com/JeanLucPons/BSGS/blob/master/README.mdThanks to odolvlobo to provide this challenge. Best wishes to Etar to optimize his program and fix his issue on GPU. |
|
|
|
|
|
Etar (OP)
|
|
April 17, 2020, 07:19:45 PM |
|
I did few optimizations (commited to github), I reached 13.6M giant steps of 2^30 per second on my Xeon X5647 2.93GHz with 12GB of RAM. It solves the 16 keys of the odolvlobo's set in 3:35:53 from scratch, I mean without any precomputation. If I convert to the Etar's unit: It does 14.6 PKey/s. I posted the result in the readme of my program: https://github.com/JeanLucPons/BSGS/blob/master/README.mdThanks to odolvlobo to provide this challenge. Best wishes to Etar to optimize his program and fix his issue on GPU. it was good thread i think. I think that each of us received something instructive here. Can you make release of your program? i mean exe file for windows? |
|
|
|
|
|


