The entire Government and Business world runs of Business Rules Engines (BREs) that are stipulated either by Policy or Law.
Everyone thinks that the next big feature in Bitcoin is going to be some little thing like a security feature. But if there were coins with entire Business Rules Engines attached to Cryptocurrencies, or a tool that allowed you to create your own Business Rules Engines within a wallet. Or it could be part of the coin, but maintained as a website, like Bitshares is. Bitshares and Steemit are also probably a good place to start, they might even have Business Rules Engines.
But the Business Rules Engines should be geared toward the community, not just making the coin work, but it should actually effect the community, and if people don't like a certain coin and its rules, they could just go to another one (Ex of a Controversial Rules type would be Income Redistribution or something).
This would actually allow Cryptocurrencies to become Decentralized Democratic Structures, coins could be made where people submit new Rules to a website, and they are voted on by the Community, maybe each wallet gets 1 vote, votes could even be done in the wallet.
Anyways. Business Rules Engines could really change the way people outside the Bitcointalk forums view coins.
https://learn.octaneai.com/introducing-octane-ai-the-easiest-way-to-create-a-bot-1b5b9615405#.z8dn7bc2nBot Development
http://chatbotfriends.altervista.org/Download.htmlhttps://www.chatbots.org/platform/download/https://docs.botframework.com/en-us/downloads/https://github.com/Microsoft/BotFramework-Emulatorhttps://dev.botframework.com/https://www.nowassistant.com/digital-assistant/bots-and-integrationshttps://www.technologyreview.com/s/603383/new-uk-surveillance-law-will-have-worldwide-implications/https://slack.com/apps/category/At0MQP5BEF-botshttp://www.cleverscript.com/demos/virtual-assistant-demo/https://www.forbes.com/sites/parmyolson/2016/05/09/could-chat-bots-replace-human-jobs-facebook/#6c447f9f7564http://www.softwebsolutions.com/resources/5-jobs-where-bots-will-replace-humans.htmlhttp://www.news18.com/news/tech/humans-vs-bots-will-bots-replace-human-labour-soon-1346001.htmlhttp://www.theverge.com/2016/4/7/11380470/amy-personal-digital-assistant-bot-ai-conversationalIt was like needing to bike across town with a blindfold on you had a general sense of what direction you needed to go, but the only way to progress was by hitting a wall.
Expert Systems
http://ccscjournal.willmitchell.info/Vol7-91/No5/Bin%20Cong.pdfMYCIN
http://psy.haifa.ac.il/~ep/Lecture%20Files/AI/Secure/Download/Introduction%20to%20expert%20systems%20-%20MYCIN.pdfInference Engine
https://en.wikipedia.org/wiki/Inference_engineRule1: Human(x) => Mortal(x)
Bayesian Statistics
https://en.wikipedia.org/wiki/Bayesian_statisticsBayesian Network
https://en.wikipedia.org/wiki/Bayesian_networkKnowledge Representation
https://en.wikipedia.org/wiki/Knowledge_representation_and_reasoninghttps://www.cse.buffalo.edu/~shapiro/Courses/CSE563/Slides/krrSlides.pdfhttps://web.stanford.edu/class/cs227/Lectures/lec01.pdfhttp://dai.fmph.uniba.sk/~sefranek/kri/handbook/handbook_of_kr.pdfhttp://stpk.cs.rtu.lv/sites/all/files/stpk/lecture_7.pdfKnowledge Engineering
http://ai.uom.gr/dsklavakis/en/mathesis/journals/The%20MATHESIS%20Meta-Knowledge%20Engineering%20Framework.pdfhttps://pdfs.semanticscholar.org/47c9/c4ea22d4d4a286e74ed1f8b8f62d9bea54fb.pdfhttp://infolab.stanford.edu/~stefan/paper/2000/ios_2000.pdfhttp://icaps07-satellite.icaps-conference.org/ickeps/OWL-ICKEPS07_CamRdy.pdfhttp://liris.cnrs.fr/robert.laurini/text/1-s2.0-S1045926X13000669-main.pdfhttp://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.278.7295&rep=rep1&type=pdfhttp://ceur-ws.org/Vol-1070/kese9-procs.pdfhttp://dai.fmph.uniba.sk/~sefranek/kri/handbook/chapter25.pdfhttp://www.aiai.ed.ac.uk/project/ix/project/kingston/phdjkk.pdfRule Based Expert Systems
https://github.com/akhilnair95/RuleBasedSystemhttps://github.com/Sorosliu1029/Rule-based_Expert_Systemhttps://github.com/dniwrallets/RuleBasedExpertSystemhttps://github.com/philipbrown/rule-based-expert-system-rubyhttps://github.com/TheRusskiy/ExpertSystemhttps://github.com/laimonassutkus/RuleBasedExpertSystemsWithCLIPShttps://github.com/levu48/rulemodhttps://github.com/rmoswela/ExpertSystemhttps://github.com/ubarkai/ruluhttps://github.com/grkpranaykumar/Mobile-Phone-recommendation-expert-systemExpert Systems
http://www.exsys.com/online.htmlhttps://www.diagnose-me.com/http://www.openlearningworld.com/books/Expert%20Systems/Expert%20Systems/http://www.openlearningworld.com/innerpages/Expert%20Systems.htmhttps://www.quora.com/Is-there-a-website-that-lets-you-create-an-expert-system-online-for-freehttp://naimath.sourceforge.net/https://en.wikipedia.org/wiki/List_of_computer-assisted_organic_synthesis_softwarehttps://pdfs.semanticscholar.org/8705/78736d52b65b00a97b983d8759f4b2a46cd7.pdfhttp://www.springer.com/us/book/9783642840500http://www.springer.com/us/book/9781461284055https://www.quora.com/What-is-a-good-open-source-expert-systemMycin
Inline image 1
Rule Based Expert Systems
http://www.softcomputing.net/fuzzy_chapter.pdfhttp://i.stanford.edu/pub/cstr/reports/cs/tr/82/926/CS-TR-82-926.pdfhttp://ftp.it.murdoch.edu.au/units/ICT219/Lectures/03B219Lect_Week05.pdfhttp://www.theimpactinstitute.org/Teaching/CS4725/rbs.pdfhttp://staff.informatics.buu.ac.th/~krisana/975352/handout/Lecture02.pdfhttps://pdfs.semanticscholar.org/c848/fea059184c3f0edc2e1f3534a34465f9737e.pdfhttps://pdfs.semanticscholar.org/d0ea/2a37ebfb1323e11e809cf407904db0d4680a.pdfhttps://pdfs.semanticscholar.org/85c3/7c3cd9322cf388d6b79bb9717ef1e219a39f.pdfhttp://csd.ijs.si/papa/courses/08_LopezPartitioning.pdfhttps://www.cs.ru.nl/P.Lucas/hep2bel.pdfhttp://file.scirp.org/pdf/TI20120200008_45341734.pdfhttp://williamdurand.fr/papers/Inferring%20models%20with%20rule-based%20expert%20systems.pdfhttp://nptel.ac.in/courses/106105078/pdf/Lesson%2018.pdfBRE
https://github.com/ddossot/NxBREhttps://github.com/nara/RulesEnginehttps://github.com/runxc1/MicroRuleEnginehttps://github.com/rsamec/business-rules-enginehttps://github.com/azach/ruleshttps://github.com/kislayverma/Rulettehttps://github.com/mallond/ruleshttps://github.com/CacheControl/json-rules-enginehttps://github.com/hoaproject/Rulerhttps://github.com/jruizgit/ruleshttp://it.nv.gov/uploadedFiles/ITnvgov/Content/Sections/IT-Investments/Lifecycle/BABOKV1_6.pdfhttp://agilityconsulting.com/resources/Strategic%20Agility%20Institute/OracleBusiness%20Rules.pdfhttp://www.equifax.com/pdfs/corp/Celent_Case_Study_0.pdfhttp://www.jaqm.ro/issues/volume-4,issue-3/pdfs/mircea_andreescu.pdfhttp://ipma-wa.com/prof_dev/2011/Gladys_Lam_Ten_Mistakes.pdfhttp://subs.emis.de/LNI/Proceedings/Proceedings91/GI-Proceedings-91-3.pdfhttp://www.bcs.org/upload/pdf/business-analysis-techniques.pdfhttp://www.kathleenhass.com/Whitepapers/The_Business_Analyst.pdfhttp://www.ogcio.gov.hk/en/infrastructure/methodology/system_development/doc/Best_Practices_for_Business_Analyst.pdfhttp://www.hau.gr/resources/toolip/doc/2016/02/03/business-analysis_2016.pdfhttps://www.iiba.org/Learning-Development/Webinars/Public-Archive/2011/How-to-Become-a-Business-Analyst-2011-pdf.aspxhttps://www.iiba.org/Learning-Development/Webinars/Public-Archive/2013/Exploring-the-BABOK-Episode-4-PDF.aspxhttp://docs.sbs.co.za/F1_Larson_Wood.pdfhttp://www.buildingbusinesscapability.com/presentations/2014/1601.pdfDiagrams
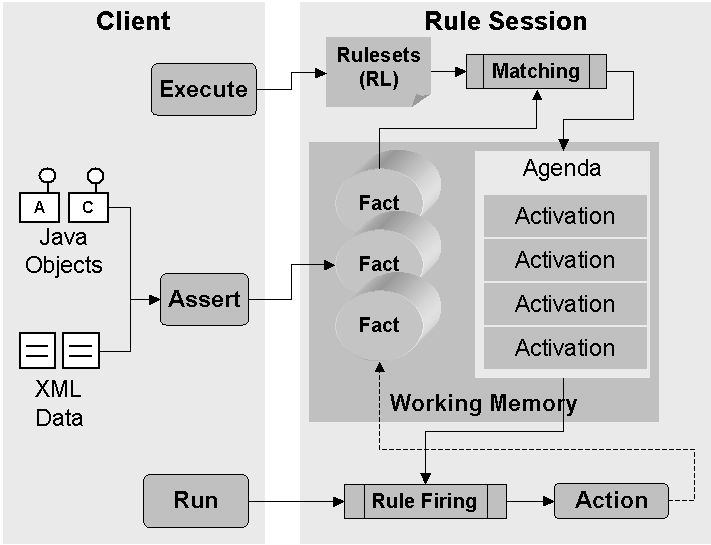
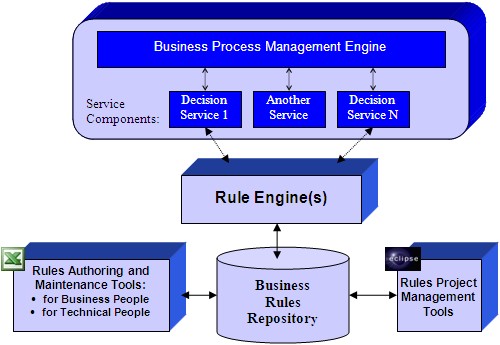
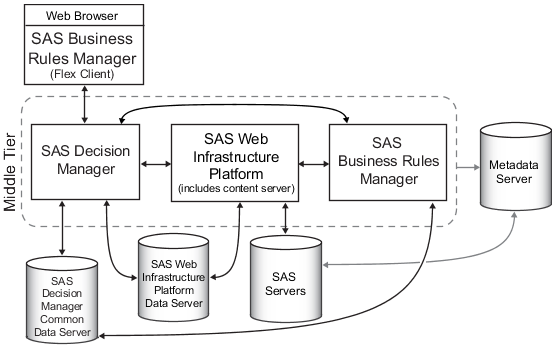
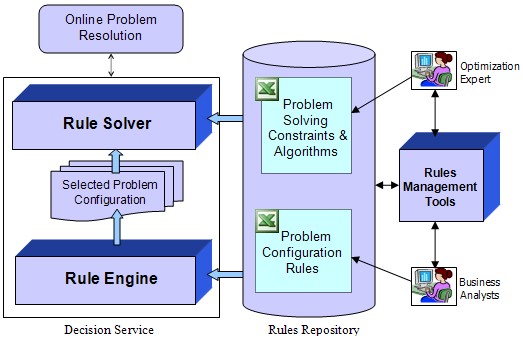
http://epf.eclipse.org/wikis/abrd/practice.tech.abrd.base/guidances/practices/resources/legacy2bre.JPGhttps://i-msdn.sec.s-msft.com/dynimg/IC19023.jpeghttp://docs.oracle.com/cd/E36909_01/user.1111/e10228/img/rulesession.gifhttps://wiki.kuali.org/download/attachments/307464583/krms-architecture.png?version=16&modificationDate=1321303971000&api=v2https://wiki.kuali.org/download/attachments/307464583/KRMS%20-%20Architecture%20-%20Draft%201.png?version=16&modificationDate=1289547751000&api=v2http://openrules.com/Site/images/RuleSOA.jpghttp://support.sas.com/documentation/cdl/en/brsag/67259/HTML/default/images/architectversion21brmanddcm.pnghttp://openrules.com/images/RuleSolver2.jpghttp://www.ibm.com/support/knowledgecenter/de/SS6MTS_7.1.1/com.ibm.websphere.ilog.jrules.doc/Content/Business_Rules/Documentation/_diagrams/JRules_Product_overview/_media/architecture_default.pngHistory of Bots and Microsoft Tay
http://politicalbots.org/wp-content/uploads/2016/10/NeffNagy.pdfDialog System
https://en.wikipedia.org/wiki/Dialog_systemhttp://www.cs.cmu.edu/~stef/thesis/thesis.pdfhttps://www.speech.kth.se/~gabriel/thesis/chapter2.pdfhttps://www.cis.upenn.edu/~mkearns/papers/cobotDS.pdfhttps://en.wikipedia.org/wiki/Verbothttps://en.wikipedia.org/wiki/ELIZAhttps://en.wikipedia.org/wiki/AIMLhttps://en.wikipedia.org/wiki/Artificial_Linguistic_Internet_Computer_Entityhttps://en.wikipedia.org/wiki/Jabberwackyhttps://en.wikipedia.org/wiki/Evolutionary_algorithmhttps://en.wikipedia.org/wiki/Automated_online_assistanthttps://en.wikipedia.org/wiki/Markov_chainhttps://en.wikipedia.org/wiki/SitePalhttps://en.wikipedia.org/wiki/XiaoiceVisual Basic could be used for the implementation while Microsoft Access could be used for creating the database. (Others: VB.NET, Jess, C, C++, Lisp, PROLOG)
A production system may be viewed as consisting of three basic components: a set of rules, a data base, and an interpreter for the rules. In the simplest design a rule is an ordered pair of symbol strings, with a left-hand side and a right-hand side (LHS and RHS). The rule set has a predetermined, total ordering, and the data base is simply a collection of symbols. The interpreter in this simple design operates by scanning the LHS of each rule until one is found that can be successfully matched against the data base. At that point the symbols matched in the data base are replaced with those found in the RHS of the rule and scanning either continues with the next rule or begins again with the first. A rule can also be viewed as a simple conditional statement, and the invocation of rules as a sequence of actions chained by modus ponens.
Replication of expertise -- providing many (electronic) copies of an experts knowledge so it can be consulted even when the expert is not personally available. Geographic distance and retirement are two important reasons for unavailability.
Union of Expertise -- providing in one place the union of what several different experts know about different specialties. This has been realized to some extent in PROSPECTOR [Reboh81] and CASNET [Weiss7b>] which show the potential benefits of achieving such a superset of knowledge bases.
Documentation -- providing a clear record of the best knowledge available for handling a specific problem. An important use of this record is for training, although this possibility is just beginning to be exploited. [Brown82, Clancey79].
Rule-based expert systems evolved from a more general class of computational models known as production systems [Newell73]. Instead of viewing computation as a prespecified sequence of operations, production systems view computation as the process of applying transformation rules in a sequence determined by the data. Where some rule-based systems [McDermott80] employ the production-system formalism very strictly, others such as MYCIN have taken great liberties with it.2 However, the. production system framework provides concepts that are of great use in understanding all rule-based systems. A classical production system has three major components: (1) a global database that contains facts or assertions about the particular problem being solved, (2) a rulebase that contains the general knowledge about the problem domain, and (3) a rule interpreter that carries out the problem solving process.
The facts in the global database can be represented in any convenient formalism, such as arrays, strings of symbols, or list structures. The rules have the form
IF <condition> THEN <action>
IF the traffic light is green THEN the action is go
IF the traffic light is red THEN the action is stop
IF <antecedent 1> IF <antecedent 1>
AND <antecedent 2> OR <antecedent 2>
. .
. .
AND <antecedent n> OR <antecedent n>
THEN <consequent> THEN <consequent>
The antecedent of a rule incorporates two parts: an object (linguistic object) and its value. The object and its value are linked by an operator. The operator identifies the object and assigns the value. Operators such as is, are, is not, are not are used to assign a symbolic value to a linguistic object. Expert systems can also used mathematical operators to define an object as numerical and assign it to the numerical value.
facts are associative triples, that is, attribute-object-value triples, with an associated degree of certainty
The <attribute> of <object> is <value> with certainty <CD
The basic EMYCIN syntax for a rule is:
PREMISE: ($AND (<clause1>
<clause-n>))
ACTION: (CONCLUDE <new-fact> <CF>)
There are five members of the development team:
1. domain expert
2. knowledge engineer
3. programmer
4. project manager
5. end-user
We can regard the modularity of a program as the degree of separation of its functional units into isolatable pieces. A program is highly modular if any functional unit can be changed (added, deleted, or replaced) with no unanticipated change to other functional units. Thus program modularity is inversely related to the strength of coupling between its functional units.
A rule-based system consists of if-then rules, a bunch of facts, and an interpreter controlling the application of the rules, given the facts. These if-then rule statements are used to formulate the conditional statements that comprise the complete knowledge base. A single if-then rule assumes the form if x is A then y is B and the if-part of the rule x is A is called the antecedent or premise, while the then-part of the rule y is B is called the consequent or conclusion. There are two broad kinds of inference engines used in rule-based systems: forward chaining and backward chaining systems. In a forward chaining system, the initial facts are processed first, and keep using the rules to draw new conclusions given those facts. In a backward chaining system, the hypothesis (or solution/goal) we are trying to reach is processed first, and keep looking for rules that would allow to conclude that hypothesis. As the processing progresses, new subgoals are also set for validation. Forward chaining systems are primarily data-driven, while backward chaining systems are goal-driven. Consider an example with the following set of if-then rules
Rule 1: If A and C then Y
Rule 2: If A and X then Z
Rule 3: If B then X
Rule 4: If Z then D
If the task is to prove that D is true, given A and B are true. According to forward chaining, start with Rule 1 and go on downward till a rule that fires is found. Rule 3 is the only one that fires in the first iteration. After the first iteration, it can be concluded that A, B, and X are true. The second iteration uses this valuable information. After the second iteration, Rule 2 fires adding Z is true, which in turn helps Rule 4 to fire, proving that D is true. Forward chaining strategy is especially appropriate in situations where data are expensive to collect, but few in quantity. However, special care is to be taken when these rules are constructed, with the preconditions specifying as precisely as possible when different rules should fire. In the backward chaining method, processing starts with the desired goal, and then attempts to find evidence for proving the goal. Returning to the same example, the task to prove that D is true would be initiated by first finding a rule that proves D. Rule 4 does so, which also provides a subgoal to prove that Z is true. Now Rule 2 comes into play, and as it is already known that A is true, the new subgoal is to show that X is true. Rule 3 provides the next subgoal of proving that B is true. But that B is true is one of the given assertions. Therefore, it could be concluded that X is true, which implies that Z is true, which in turn also implies that D is true. Backward chaining is useful in situations where the quantity of data is potentially very large and where some specific characteristic of the system under consideration is of interest. If there is not much knowledge what the conclusion might be, or there is some specific hypothesis to test, forward chaining systems may be inefficient. In principle, we can use the same set of rules for both forward and backward chaining. In the case of backward chaining, since the main concern is with matching the conclusion of a rule against some goal that is to be proved, the then (consequent) part of the rule is usually not expressed as an action to take but merely as a state, which will be true if the antecedent part(s) are true (Donald, 1986).
heuristic -- i.e., it reasons with judgmental knowledge as well as with formal knowledge of established theories; 0
transparent -- i.e., it provides explanations of its line of reasoning and answers to queries about its . knowledge; l
flexible -- i.e., it integrates new knowledge incrementally into its existing store of knowledge..
MYCIN [Davis77b] [Shortliffe, 1976]. analyzes medical data about a patient with a severe infection, PROSPECTOR [Duda79] analyzes geological data to aid in mineral exploration, and PUFF [Kunz78] analyzes the medical condition of a person with respiratory problems. In order to provide such analyses, these systems need very specific rules containing the necessary textbook and judgmental knowledge about their domains.
The first expert systems, DENDRAL [Lindsay801 and MACSYMA [Moses71], emphasized performance, the former in organic chemistry and the latter in symbolic integration. These systems were built in the mid-1960s, and were nearly unique in AI because of their focus on real-world problems and on specialized knowledge. In the 1970s, work on expert systems began to flower, especially in medical problem areas (see, for example [P0ple77, Shortliffc76, Szolovits78, Weiss79bl). The issues of making the system understandable through explanations [Scott77, Swartout811 and of making the system flexible enough to acquire new knowledge [Davis79, Mitchell791 were emphasized in these and later systems.
Very often people express knowledge as natural language (spoken language), or using letters or symbolic terms. There exist several methods to extract human knowledge. Cognitive Work Analysis (CWA) and the Cognitive Task Analysis (CTA) provide frameworks to extract knowledge. The CWA is a technique to analyze, design, and evaluate the human computer interactive systems (Vicente, 1999). The CTA is a method to identify cognitive skill, mental demands, and needs to perform task proficiency (Militallo and Hutton, 1998). This focuses on describing the representation of the cognitive elements that defines goal generation and decision-making. It is a reliable method for extracting human knowledge because it is based on the observations or an interview.
A representation is a set of conventions for describing the world. In the parlance of AI, the representation of knowledge is the commitment to a vocabulary, data structures, and programs that allow knowledge of a domain to be acquired and used. This has long been a central research topic in AI (see [Amarel81, Barr81, Brachman80, Cohen82] for reviews of relevant work).
The interpreter is the source of much of the variation found among different systems, but it may be seen in the simplest terms as a select-execute loop in which one rule applicable to the current state of the data base is chosen and then executed. Its action results in a modified data base, and the select phase begins again. Given that the selection is often a process of choosing the first rule that matches the current data base, it is clear why this cycle is often referred to as a recognize-act, or situation-action, loop.
EMYCIN [vanMelle80] [Bennet81a] ROSIE [Fain81], KAS [Reboh81], EXPERT [peiss79a], and OPS [Forgy77] OPS Carnegie-Mellon University [Forgy77] EMYCIN Stanford University [vanMelle80] AL/X University of Edinburgh EXPERT Rutgers University [Weiss79a] KAS SRI International [Reboh81] RAINBOW IBM Scientific Center (Palo Alto) [Hollander79]
One of the most popular shells widely used throughout the government, industry, and academia is the CLIPS (CLIPS, 2004). CLIPS is an expert system tool that provides a complete environment for the construction of rule- and/or object-based expert systems. CLIPS provides a cohesive tool for handling a wide variety of knowledge with support for three different programming paradigms: rule-based, object-oriented, and procedural. CLIPS is written in C for portability and speed and has been installed on many different operating systems without code changes.
There are alternatives to representing task-specific knowledge in rules. Naturally, it is sometimes advantageous to build a new system in PASCAL, FORTRAN, APL, BASIC, LISP, or other language, using a variety of data structures and inference procedures, as needed for the problem. Coding a new system from scratch, however, does not allow concentrating primarily on the knowledge required for high performance. Rather, one tends to spend more time on debugging the procedures that access and manipulate the knowledge.
Evolutionary Computation (EC) is a population based adaptive method, which may be used to solve optimization problems, based on the genetic processes of biological organisms (Michalewicz and Fogel, 1999). Over many generations, natural populations evolve according to the principles of natural selection and survival of the fittest, first clearly stated by Charles Darwin in On the Origin of Species. By mimicking this process, EC could evolve solutions to real-world problems, if they have been suitably encoded (problem representation is called chromosome). Automatic adaptation of membership functions is popularly known as self tuning and the chromosome encodes parameters of trapezoidal, triangle, logistic, hyperbolic-tangent, Gaussian membership functions, and so on. Evolutionary search of fuzzy rules can be carried out using three approaches. In the first method (Michigan approach), the fuzzy knowledge base is adapted as a result of antagonistic roles of competition and cooperation of fuzzy rules.
The second method (Pittsburgh approach), evolves a population of knowledge bases rather than individual fuzzy rules. Reproduction operators serve to provide a new combination of rules and new rules.
The third method (iterative rule learning approach), is very much similar to the first method with each chromosome representing a single rule, but contrary to the Michigan approach, only the best individual is considered to form part of the solution, discarding the remaining chromosomes of the population. The evolutionary learning process builds up the complete rule base through an iterative learning process (Cordon´ et al., 2001).
Modus ponens is the . primary rule of inference by which a system adds new facts to a growing data base:
IF B IS TRUE B B
AND B IMPLIES C, OR B --> C
THEN C IS TRUE. --------
C
First, some follow-on research to MYCIN addresses the human engineering problems directly, for example, by integrating high quality graphics with user-oriented forms and charts for input and output [Shortliffe81]. Second, some MYCIN-like programs finesse many human engineering problems by collecting data from on-line instruments rather than from users [Kunz78]. Exportability can be gained by rewriting [Carhart79, Kunz78] or by designing for export initially [Weiss79a].
Extendability -- the data structures and access programs must be flexible enough to allow extensions to the knowledge base without forcing substantial revisions. The knowledge base will contain heuristics that are built out of experts experience. Not only do the experts fail to remember all relevant heuristics they use, but their experience gives them new heuristics and forces modifications to the old ones. New cases require new distinctions. Moreover, the most effective way we have found for building a knowledge base is by incremental improvement. Experts cannot define a complete knowledge base all at once for interesting problem areas, but they can define a subset and then refine it over many weeks or months of examining its consequences. All this argues for treating the knowledge base of an expert system asean open-ended set of facts and relations, and keeping the items of knowledge as modular as possible.
Simplicity -- We have all seen data structures that were so baroque as to be incomprehensible, and thus unchangeable. The flexibility WC argued for above requires conceptual simplicity and uniformity so that access routines can be written (and themselves modified occasionally as needed). Once the syntax of the knowledge base is fixed, the access routines can be fixed to a large extent. Knowledge acquisition, for example, can take place with the expert insulated from the data structures by access routines that make the knowledge base appear simple, whether it is or not. However, new reasons will appear for accessing the knowledge base as in explanation of the contents of the knowledge base, analysis of the links among items, display, or tutoring. With each of these reasons, simple data structures pay large benefits. From the designers point of vi& there are two ways of maintaining conceptual simplicity: keeping the form of knowledge as homogeneous as possible or writing special access functions for non-uniform representations.
Explicitness -- The point of representing much of an experts knowledge is to give the system a rich enough knowledge base for high-performance problem solving. But because a knowledge base must be built incrementally, it is necessary to provide means for inspecting and debugging it easily. With items of knowledge represented explicitly, in relatively simple terms, the experts who are building knowledge bases can determine what items are present and (by inference) which are absent.
Semantic Completeness of the knowledge base for a problem area is also desirable. Because of the nature of the knowledge base and the way it is built, however, it will almost certainly fail to cover some interesting (sometimes important) possibilities. In a very narrow problem area, for example, there may be 100 attributes of interest, with an average of 4 important values for each attribute. (Only in extreme cases will all attributes be binary.) Thus there would be 79,800 possible rules relating two facts (400 items taken two at a time), over 10 million possible rules relating three facts, and so on. While most are semantically implausible, e.g., because of mutually exclusive values, the cost of checking all combinations for completeness is prohibitive. Checking the inferences made by a system in the context of carefully chosen test cases is currently the best way to check the completeness of coverage of the rules
If there is only one applicable rule, the obvious thing to do is to apply it. Its application will enter new facts in the database. While that may either enable or disable previously inapplicable rules, by our assumption it will never disable a previously applicable rule. If there is more than one applicable rule, we have the problem of deciding which one to apply. Procedure 21 Select-Rule has the responsibility for making this decision. Different data-driven strategies differ greatly in the amount of problem-solving effort they devote to rule selection. A simple and inexpensive strategy is to select the first rule that is encountered in the scan for S -- doing the first thing that comes to mind. Unfortunately, unless the rules are favorably ordered, this can result in many useless steps. Elaborations intended to overcome such shortcomings can make data-driven control arbitrarily complex.
Methods used for conflict resolution
1 Use the rule with the highest priority. In simple applications, the priority can be established by placing the rules in an appropriate order in the knowledge base. Usually this strategy works well for expert systems with around 100 rules.
2 Use the most specific rule. This method is also known as the longest matching strategy. It is based on the assumption that a specific rule processes more information than a general one.
3 Use the rule that uses the data most recently entered in the database. This method relies on time tags attached to each fact in the database. In the conflict set, the expert system first fires the rule whose antecedent uses the data most recently added to the database.
Uncertainty can be expressed numerically as certainty/confidence factor (cf) or measure of belief (mb)
cf usually is a real number in a particular range, eg, 0 to 1 or -1 to 1
Combining certainties of propositions and rules
Let P1 and P2 be two propositions and cf(P1) and cf(P2) denote their certainties
Then
cf(P1 and P2) = min(cf(P1), cf(P2))
cf(P1 or P2) = max(cf(P1), cf(P2))
given the rule
if P1 then P2: cf = C
then certainty of P2 is given by
cf(P2) = cf(P1) * C
place the responsibility on the knowledge engineer to see that the rules are properly structured. Many problems caused by interactions can be solved by employing a hierarchical structure, with several levels of assertions between the direct observations and the final conclusions. The goal is to localize and limit tic interactions, and to have a rclativcly small number of clauses in a condition and a relatively small number of rules sharing a common conclusion. Note that this limitation on the number of rules does not reduce the amount of evidence considered in reaching a conclusion, but rather controls the ways in which the observations are allowed to interact. A hierarchical structure is typically employed by the experts themselves to reduce the complexity of a problem. Wherever the remaining interactions still prevent the assumption of local independence, the rules have to be reformulated to achieve the desired behavior. For example, in the strongly interacting situation where B, suggests A and B, suggests A, but the simultaneous presence of both B, and I33 rules out A one may have to augment the rule set
{ (B1 - - > A with weight L1)
(B2 - - > A with weight L2) }
with the rule (B1 & B2 --> A with weight-m). Thus, rather than viewing probability theory as a paradigm that prescribes how information should be processed, the knowledge engineer employs it as a tool to obtain the desired behavior.
In contrast with the heuristic techniques for reasoning with uncertainty employed in many rule-based expert systems, the theory of belief networks is mathematically sound, based on techniques from probability theory. The formalism of belief networks offers an intuitively appealing approach for expressing inexact causal relationships between domain concepts [7, 20]. A belief network consists of two components [3]:
A qualitative representation of the variables and relationships between the variables discerned in the domain, expressed by means of a directed acyclic graph G = (V (G),A(G)), where V (G) = {V1,V2,... ,Vn} is a set of vertices, taken as the variables, and A(G) a set of arcs (Vi,Vj), where Vi,Vj ∈ V (G), taken as the relationships between the variables.
A quantitative representation of the strengths of the relationships between the variables, expressed by means of assessment functions.
Narrow scope -- The task for the system must be carefully chosen to be narrow enough that the relevant expcrtisc can be encoded, and yet complex enough that expertise is required. This limitation is more because of the time it takes to engineer the knowlcdgc into a system including rcfmemcnt and debugging, than because space required for the knowledge base.
Existence of an expert -- Thcie are problems so new or so complex that no one rBnks as an expert in the problem area. Generally speaking, it is unwise to expect to be able to construct an expert system in areas where there are no experts.
Agreement among experts -- If current problem solving expertise in a task area leaves room for frequent and substantial disagreements among experts, then the task is not appropriate for an expert system.
Data available -- Not only must the expertise be available, but test data must be available (preferably online). Since an expert system is built incrementally, with knowledge added in response to observed difficulties, it is necessary to have several test cases to help explore the boundaries of what the system knows.
Milestones definable -- A task that can be broken into subtasks, with measurable milestones, is better than one that cannot be demonstrated until all the parts are working
Separation of task-specific knowledge from the rest of the program -- This separation is essential to maintain the flexibility and understandability required in expert systems.
Attention to detail -- Inclusion of very specific items of knowledge about the domain, as well as general facts, is the only way to capture the expertise that experience adds to textbook knowledge.
Uniform data structures-- A homogeneous representation of knowledge makes it much easier for the system builder to develop acquisition and explanation packages.
Symbolic reasoning - It is commonplace in AI, but not elsewhere, to regard symbolic, non-numeric reasoning as a powerful method for problem solving by computers. In applications areas where mathematical methods are absent or computationally intractable, symbolic reasoning offers an attractive alternative.
Combination of deductive logic and plausible reasoning -- Although deductive reasoning is the standard by which we measure correctness, not all reasoning -- even in science and mathematics -- is accomplished by deductive logic. Much of the worlds expertise is in heuristics, and programs that attempt to capture expert level knowledge need to combine methods for deductive and plausible reasoning.
Explicit problem solving strategy -- Just as it is useful to separate the domain-specific knowledge from the inference method, it is also useful to separate the problem solving strategy from both. In debugging the system it helps to remember that the same knowledge base and inference method can produce radically different behaviors with different strategies. For example, consider the difference between find the best and find the first over threshold.
Interactive user interfaces -- Drawing the user into the problem solving process is important for tasks in which the user is responsible for the actions recommended by the expert system, as in medicine. For such tasks, the inference method must support an interactive style in which the user contributes specific facts of the case and the program combines them in a coherent analysis.
Static queries of the knowledge base -- The process of constructing a large knowledge base requires understanding what is (and is not) in it at any moment. Similarly, using a system effectively depends on assessing what it does and does not know.
Dynamic queries about the line of reasoning -- As an expert system gathers data and makes intermediate conclusions, users (as well as system builders) need to be able to ask enough questions to follow the line of reasoning. Otherwise the systems advice appears as an oracle from a black box and is less likely to be acceptable.
Bandwidth -- An experts ability to communicate his/her expertise within the framework of an expert system is limited by the restrictions of the framework, the degree to which the knowledge is already well-codified, and the speed with which the expert can create and modify data structures in the knowledge base.
Knowledge engineer -- One way of providing help to experts during construction of the knowledge base is to let the expert communicate with someone who understands the syntax of the framework, the rule interpreter, the process of knowledge base construction, and the practical psychology of interacting with world-class experts. This person is called a knowledge engineer.
Level of performance -- Empirical measures of adequacy are still the best indicators of performance, even though they are not sufficient for complete validation by any means. As with testing new drugs by the pharmaceutical industry, testing expert systems may. best bc accomplished by randomized studies and double blind experiments.
Static evaluation -- Because the knowledge base may contain judgmental rules as well as axiomatic truths, logical analysis of its completeness and consistency will be inadequate. However, static checks can reveal potential problems, such as one rule subsuming another and one rule possibly contradicting another. Areas of weakness in a knowledge base can sometimes be found by analysis as well.
Many applications programs that have the characteristics of expert systems have been developed for analysis problems in a diversity of areas including: chemistry [Buchanan78, Carhart79]; genetics [Stefik78]; protein crystallography [Engelmore79]; physics [Bundy79, Larkin80, Novak80,]; interpretation of oil well logs [Barstow79b, Davis81]; electronics troubleshooting [Addis80, Bennett81b, Brown82, Davis82b, Genesereth81b, Kandt81, Stallman77]; materials engineering [Basden82, Ishizuka81]; mathematics [Brown78, Moses71]; medical diagnosis [Chandrasekaran80, Fagan80, Goriy78, Heisdr78, Horn81, Kaihara78, Lindberg81, Pati181, Pople77, Reggia78, Shortliffe76, Shortliffe81, Swartout77, Szolovits78, Tsotsos81, Weiss79bl; mineral exploration [Duda79]; aircraft identification and mission planning [Engelman79]; military situation assessment [McCo1179, Nii82]; and process control [wamdani82].
analysis problems are described using many different terms, including:
l Data Interpretation
l Explanation of Empirical Data
l Understanding a Complex of Data (c.g., signal understanding)
l Classification
l Situation Assessment
l Diagnosis (of diseases, equipment failures, etc.)
l Troubleshooting
l Fault Isolation
l Debugging
l Crisis Management (diagnosis half)
Synthesis problems arise in many fields including: planning experiments in molecular genetics [Fricdland79, Stefik801, configuring the components of a computer system [McDcrmott80, McDcrrnott81]; scheduling [Fox82, Goldstein79, Lauriere78]; automatic programming [Barstow79a, McCune77]; electronics design [deKleer80, Dincbas80, Sussman78], and chemical synthesis [Gelernter77, Wipke77]. These problems have been called:
l Planning (or Constructing a Plan of Action)
l Fault Repair
l Process Specification
l Design (of complex devices or of experiments)
l Configuration
l Therapy (or therapy planning)
l Automatic Programming
l Computer-Aided Chemical Synthesis Planning
In addition to analysis and synthesis problems, expert systems have been built to provide advice on how to USC a complex system [Anderson76, Bennett79, Gencscreth78, Hewitt75, Krueger81, Rivlin80, Waterman79] or to tutor a novice in the use or understanding of a body of knowledge [Brown82, Clancey79, OShea79]. These problems arc partly analytic, since the advice or tutorial must be guided by an analysis of the context, and partly synthetic since the advice must be tailored to the user and the problem at hand.
The proficiency of an expert system is dependent on the amount of domain-specific expertise it contains. But expertise about interesting problems is not always neatly codified and waiting for transliteration into a programs internal representation. Expertise exists in many forms and in many places, and the task of knowledge engineering includes bringing together what is known about a problem as well as transforming (not merely transcribing) it into the system.
http://www.theimpactinstitute.org/Teaching/CS4725/rbs.pdfhttp://nptel.ac.in/courses/106105078/pdf/Lesson%2018.pdfhttp://www.businesssemantics.com/Resources/How_SBVR_Adds_Knowledge_Richness_to_ISO_TC_37_Terminology_Standards.pdfNote that because it is often easier to design large rule systems as a sequence of independent rulesets to be executed in some order, rule engines sometimes extend the notion of rule execution with mechanisms to orchestrate rulesets typically called ruleflows.
Another approach is to deploy rulesets in a continuous, event-driven rule engine or agent for tasks such as CEP (Complex Event Processing). Other UML constructs such as state models might be used to provide context for rule execution. Modeling the state of entities over time, and the continuous processing of events, usually requires stateful operation of the rule engine so that information is retained in the rule engine between events
For business processes represented in a BPMS (Business Process Management System), detailing decision logic within the process diagram often obfuscates the core business processes. Business processes can represent manual (workflow) or automated tasks, with the commonest form of process representation being BPMN (Business Process Modeling Notation).
The most common format2 for BPM users to represent business rules is the decision table. This provides a common set of condition and action statements, with the table providing different values representing different rules. Some systems map decision tables to a specific algorithm; others will map them to component production rules. Similar models are decision trees and decision graphs.
Note that decision models output from Predictive Analytics tools may or may not be usefully mapped to production rules. One example might be a segmentation model representing a decision tree segmenting customers for marketing offers, which maps to a decision tree and thence production rules. Alternatively a model type such as a neural net representing a face-recognition feature will not usefully map to production rules. Often such analytics tools generate models in a language called PMML (Predictive Model Markup Language)
the why column in fact drives all the other ones. Why is your data the way it is? Why do you need to know certain facts and terms (entities and relationships)? Why do you process this way and no the other? Why isnt this or that allowed? In fact all these questions have always been done. They just werent recorded appropriately in our models.
These tools are for the recording and organizing of the BR.
QSS DOORs (a requirements management tool actually) (www2.telelogic.com/doors)
Rationals Requisite PRO (idem) (
www.rational.com)
Rivertons HOW (
www.riverton.com)
Usofts Teamwork (
www.usoft.com) Business Rules Solutions BRS Ruletrack (
www.brsolutions.com)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}