sawa
Legendary

 Offline Offline
Activity: 1308
Merit: 1011

|
 |
April 16, 2017, 04:46:25 PM |
|
I tracked down and (in my working branch) fixed a bug that's worth mentioning. When assigning new stratum jobs to miners, p2pool will guess what difficulty to use (for pseudoshares) based on the node's hashrate. If the node just started, it doesn't know what hashrate to use, and often ends up assigning insanely low difficulty, usually around 4 GH per share. If a substantial amount of miners connect to the node quickly after starting up, the node can get flooded with thousands of shares per second, which will either saturate the CPU or (if you've got less than about 100 kB/s of bandwidth) the network. This can be avoided by making p2pool use the default share difficulty (which is based on the share chain) divided by e.g. 1000 until the node has an estimate for its own hashrate. When this bug occurs, it looks like this: 2017-04-14 21:30:07.152590 > Traceback (most recent call last):
2017-04-14 21:30:07.152619 > File "p2pool/util/variable.py", line 74, in set
2017-04-14 21:30:07.152647 > self.changed.happened(value)
2017-04-14 21:30:07.152664 > File "p2pool/util/variable.py", line 42, in happened
2017-04-14 21:30:07.152681 > func(*event)
2017-04-14 21:30:07.152698 > File "p2pool/work.py", line 130, in <lambda>
2017-04-14 21:30:07.152715 > self.node.best_share_var.changed.watch(lambda _: self.new_work_event.happened())
2017-04-14 21:30:07.152732 > File "p2pool/util/variable.py", line 42, in happened
2017-04-14 21:30:07.152759 > func(*event)
2017-04-14 21:30:07.152785 > --- <exception caught here> ---
2017-04-14 21:30:07.152801 > File "p2pool/bitcoin/stratum.py", line 38, in _send_work
2017-04-14 21:30:07.152817 > x, got_response = self.wb.get_work(*self.wb.preprocess_request('' if self.username is None else self.username))
2017-04-14 21:30:07.152835 > File "p2pool/work.py", line 212, in preprocess_request
2017-04-14 21:30:07.152852 > raise jsonrpc.Error_for_code(-12345)(u'lost contact with bitcoind')
2017-04-14 21:30:07.152868 > p2pool.util.jsonrpc.NarrowError: -12345 lost contact with bitcoind
... A similar problem occurs not only if local_hash_rate is None The same consequences will be when you mine on altcoin p2pool for a long time with a low hashrate and then add big power. And you'll see 100% CPU usage and ~100 kB/s of traffic to your miners.
As a result, the miner who entered with a big power sees a huge DOA and disconnects. http://crypto.office-on-the.net:12347/static/ |
|
|
|
|
|
|
|
|
|
|
"The nature of Bitcoin is such that once version 0.1 was released, the
core design was set in stone for the rest of its lifetime." -- Satoshi
|
|
|
Advertised sites are not endorsed by the Bitcoin Forum. They may be unsafe, untrustworthy, or illegal in your jurisdiction.
|
|
|
windpath
Legendary
Offline
Activity: 1258
Merit: 1027

|
|
April 16, 2017, 09:35:27 PM |
|
Have not seen a block party like this in a few years  |
|
|
|
|
|
tubexc
|
|
April 16, 2017, 09:44:39 PM |
|
You bet I have never encountered any blocks in person but this certainly increases my confidence in p2pool  |
|
|
|
|
|
jtoomim
|
|
April 16, 2017, 09:45:31 PM
Last edit: April 16, 2017, 11:07:24 PM by jtoomim |
|
I ran into another bug. This one could be a fatal problem to p2pool if the network hashrate ever falls abruptly and severely (e.g. more than 10x), as it did when I switched over to my new fork. The problem stems from this code: timestamp=math.clip(desired_timestamp, (
(previous_share.timestamp + net.SHARE_PERIOD) - (net.SHARE_PERIOD - 1), # = previous_share.timestamp + 1
(previous_share.timestamp + net.SHARE_PERIOD) + (net.SHARE_PERIOD - 1),
)) if previous_share is not None else desired_timestamp,
Basically, the share timestamp is allowed to increase by no more than 61 seconds per share. If the hashrate suddenly falls by more than 2x, this means that the average share will take more than 61 seconds of real time and will have its timestamps clipped. Ultimately, this can result in anomalous minimum share difficulty calculations. What happens is that you get a time backlog, and all shares have timestamps 61 seconds after the previous one regardless of how long they actually took. This means that the next share will have lower difficulty than the previous one no matter what, even if it actually took 1 second. As each share has lower difficulty, but still apparently takes 61 seconds, the estimated pool hashrate drops even further, which causes the difficulty to drop exponentially, until p2pool can no longer process shares as fast as they're submitted. Then everything goes to hell and you start getting 100 DOAs for every valid share. In my case, it seems to have resulted in share difficulties around 600 before things crashed, which meant several shares were being found every second. For comparison, the current difficulty on the legacy chain (the one you guys are all using) is around 4.8 million. Since we currently have a single miner with about 3/4 of the network hashrate, if that miner chose to leave p2pool all at once, that might be enough to trigger this bug, although probably not as severely as I did. I'll have to think a bit about how to fix this. It's probably not a trivial "Let's get rid of the clipping!" thing, since the clipping should be there to protect against malicious miners manipulating the timestamps and consequently the share difficulty. I think using something like Bitcoin's rule of not accepting shares more than 2 hours in the future could be good, but that will require that everybody have reasonably accurate clocks. Which might be worth requiring anyway. Edit: Yeah, I think the right thing to do is probably to simply remove the clipping and also to reject any shares that are timestamped more than maybe 300 seconds in the future. Anyone who has an incorrect clock setting will either see a lot of error messages from rejecting others' shares plus a high share orphan rate if their clock is slow, or simply a high orphan rate if their clock is fast. As mining is basically a timestamping operation, there's a strong case to be made that keeping accurate clocks is a miner's duty. The death spiral in graphs:   Note how the network traffic increases when the estimated hashrate hits zero, and how peers become unable to maintain a connection. In order to recover from this bug, I had to restore a backup of the share chain that I made yesterday, so I lost about a day's worth of hashing at around 700 TH/s.  |
Hosting bitcoin miners for $65 to $80/kW/month on clean, cheap hydro power. http://Toom.im |
|
|
Meuh6879
Legendary
Offline
Activity: 1512
Merit: 1011
|
|
April 17, 2017, 12:38:54 AM |
|
Have not seen a block party like this in a few years And this is good, we attract more miners, too ... 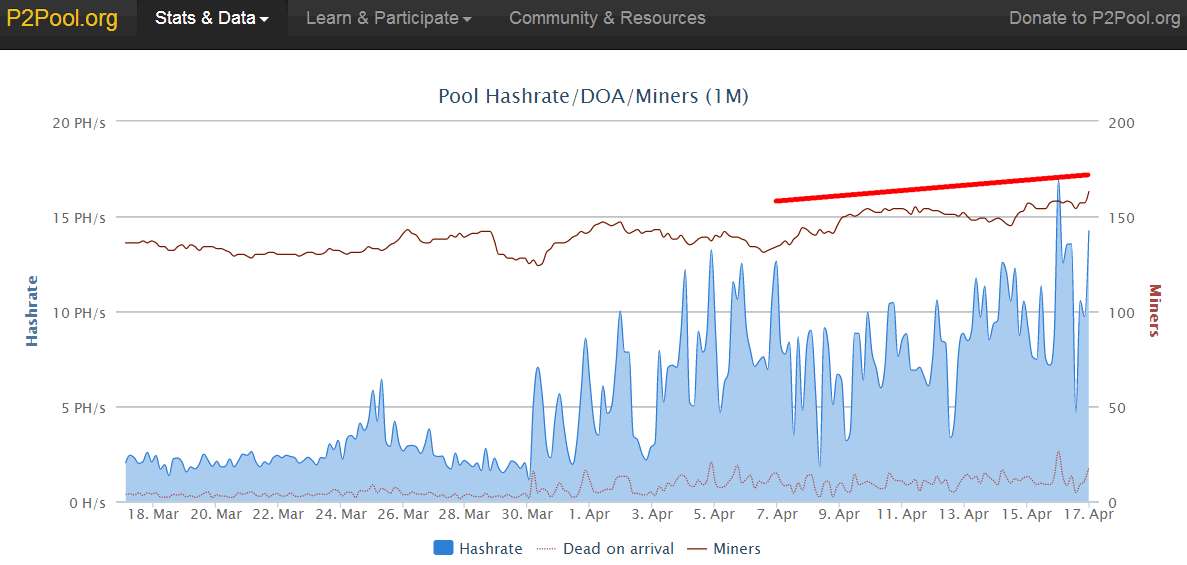 |
|
|
|
|
|
jtoomim
|
|
April 17, 2017, 02:10:23 AM |
|
It's probably not a trivial "Let's get rid of the clipping!" thing
I treated the problem as a trivial "Let's get rid of the clipping!" thing, and it's working much better now. Share rates equilibrated at around 30 seconds per share after an hour or so, versus the several days at around 2 shares per hour that I was dealing with before. That will make testing and development much easier. Soon, I'll add rejection of shares with timestamps in the future to protect against difficulty manipulation DoS attempts. I think I've found a good way to solve the replay protection thing and another issue at the same time. I'll check to make sure it will work before mentioning it. It's a little complicated of a solution, but it should be worth it for the side benefits: if I'm right, it will more fairly reward people for transaction fees while also making sure that my chain can't accidentally kill the old chain. |
Hosting bitcoin miners for $65 to $80/kW/month on clean, cheap hydro power. http://Toom.im |
|
|
|
jtoomim
|
|
April 17, 2017, 05:15:45 AM
Last edit: April 17, 2017, 06:15:08 AM by jtoomim |
|
I wanted to try to connect to your node http://ml.toom.im:9334/, but unfortunately for some reason it did not work. I will wait for the completed code. leri4 and I talked a little by PM. His issue appears to be DNS related. If you have trouble connecting, try using the IP address, 208.84.223.121. |
Hosting bitcoin miners for $65 to $80/kW/month on clean, cheap hydro power. http://Toom.im |
|
|
|
flameruk
|
|
April 17, 2017, 02:36:10 PM |
|
Have not seen a block party like this in a few years Things are going great! This kind of hash power should hopefully attract some other permanent miners to join up as well. Any ideas if its rentals that have taken the hash rate up? Just thinking if rentals, when those rentals end or how long they can keep it up. |
Find my P2POOL node at www.ukp2pool.uk:9332Donations for operating node? BTC 1CYevtGy3aqr1reuq7CFceNFAT7snsz3VM |
|
|
|
jtoomim
|
|
April 17, 2017, 03:42:03 PM
Last edit: April 17, 2017, 08:56:35 PM by jtoomim |
|
Any ideas if its rentals that have taken the hash rate up?
Just thinking if rentals, when those rentals end or how long they can keep it up.
It looked to me like it was rentals. The current burst of hashrate started on Mar 29th right after I mined the first block in like 3 weeks. I know there was at least one entity who set up an automatic nicehash p2pool mining scheme with automatic reinvestment of p2pool rewards, and the timing suggests to me that this was something similar. Personally, I'm hoping that my new fork can attract permanent contributors. I think I've been able to fix some of the many bugs and issues with p2pool, and there are lots more optimizations that I've thought of but haven't had time to implement yet. I think we can get p2pool to scale up quite a bit and still give its users better revenue than they would get with most traditional pools. I may have to write some share propagation code specifically with the GFW in mind, though (e.g. UDP, weak shares, bloom filters to replace remember_tx and forget_tx, maybe IBLTs, and share-headers-first mining). Even without those things, revenue will probably be better in China than the main Chinese pools (which all have large fees). But we'll see. My company will also be adding quite a bit of hashrate over the next few months. I'm expecting to add 390 TH/s today alone, for example (30 S9s are on their way). We'll probably add a petahash or so by July. All of that hashrate will be going onto the new fork, of course. Edit: Yes, it's Nicehash. The p2pool user 1Hinenj9woDM8wLDffov4PUwFqqtRg5FRu sends regular payments of 2 to 10 btc to 3FNmBkdxorsjf7PFBf4d5JEYBybMicbDin about two times a week, adding funds from 19XLjEswgycrtbX1TcCJ8grw8zZYvbNaG6 as necessary. The 3FN address belongs to Nicehash, and makes regular payouts to Nicehash customers (examples 1 and 2). The 19XL address first sent money to Nicehash (2 BTC via 3FN) on November 6th, 2016. 19XL appears to be a user of Poloniex, as he frequently gets some money from Poloniex's 2nd-biggest wallet 17A16QmavnUfCW11DAApiJxp7ARnxN5pGX (about 0.2 btc every 2 days). The p2pool user 1NVoAeLBm3QLRCcezvwUzKYHDLU96dji8x is directly a customer of nicehash, and sells about 18 kSol/s of Equihash hashpower there (about 0.1 btc/day). We can't see via Nicehash's public UI what he buys, but 1NV has sent regular payments of 1.2 to 1.5 btc to 32DdAy7oDoovdxt6egJ2Zoip1sQf25pZs3, which is another Nicehash deposit address. 1Hinen and 1NV have made a ton of money from the recent luck, and have about 30 btc and 6 btc respectively saved up, but they're spending it at a rate of about 20 btc per week. If I'm right and these deposits are being made by a bot, then he can keep it up for about 1.5 weeks with 0% mining luck. If luck remains close to 100% (it has been over 200% recently), then he should be able to hold it up for quite a while, although I presume that Nicehash's fees will run down his balance eventually. That could be a month or two away, though. |
Hosting bitcoin miners for $65 to $80/kW/month on clean, cheap hydro power. http://Toom.im |
|
|
kavjlaeg
Newbie
 Offline
Offline
Activity: 66
Merit: 0
|
|
April 17, 2017, 05:02:05 PM |
|
|
|
|
|
|
|
flameruk
|
|
April 17, 2017, 05:24:00 PM |
|
Any ideas if its rentals that have taken the hash rate up?
Just thinking if rentals, when those rentals end or how long they can keep it up.
It looked to me like it was rentals. The current burst of hashrate started on Mar 29th right after I mined the first block in like 3 weeks. I know there was at least one entity who set up an automatic nicehash p2pool mining scheme with automatic reinvestment of p2pool rewards, and the timing suggests to me that this was something similar. Personally, I'm hoping that my new fork can attract permanent contributors. I think I've been able to fix some of the many bugs and issues with p2pool, and there are lots more optimizations that I've thought of but haven't had time to implement yet. I think we can get p2pool to scale up quite a bit and still give its users better revenue than they would get with most traditional pools. I may have to write some share propagation code specifically with the GFW in mind, though (e.g. UDP, weak shares, bloom filters to replace remember_tx and forget_tx, maybe IBLTs, and share-headers-first mining). Even without those things, revenue will probably be better in China than the main Chinese pools (which all have large fees). But we'll see. Thanks for the reply. Thinking this could be publicp2poolnode who was experimenting with rentals some time ago. Ive been really busy at work for a few weeks and been out in Spain for a week so just catching up. Ive barely been able to keep an eye on my node and miners with limited internet. Ive seen posts about your fork but not got to grips with it yet. Anyway Ive taken a gamble today and thrown 0.6 Ph of rentals onto my node. The node is handling it really well which is good as a test for my node stability. If the run keeps up im hoping to make some kind of gain myself. Given the current hash rate something should happen now varience is a bit lower. Be a winner if we drop a double block again like yesterday but dont want anything to soon. Need those shares up in the chain a bit first. |
Find my P2POOL node at www.ukp2pool.uk:9332Donations for operating node? BTC 1CYevtGy3aqr1reuq7CFceNFAT7snsz3VM |
|
|
|
M8BWNNRFMNdak68c
|
|
April 17, 2017, 08:26:07 PM |
|
Any ideas if its rentals that have taken the hash rate up?
Just thinking if rentals, when those rentals end or how long they can keep it up.
It looked to me like it was rentals. The current burst of hashrate started on Mar 29th right after I mined the first block in like 3 weeks. I know there was at least one entity who set up an automatic nicehash p2pool mining scheme with automatic reinvestment of p2pool rewards, and the timing suggests to me that this was something similar. Personally, I'm hoping that my new fork can attract permanent contributors. I think I've been able to fix some of the many bugs and issues with p2pool, and there are lots more optimizations that I've thought of but haven't had time to implement yet. I think we can get p2pool to scale up quite a bit and still give its users better revenue than they would get with most traditional pools. I may have to write some share propagation code specifically with the GFW in mind, though (e.g. UDP, weak shares, bloom filters to replace remember_tx and forget_tx, maybe IBLTs, and share-headers-first mining). Even without those things, revenue will probably be better in China than the main Chinese pools (which all have large fees). But we'll see. My company will also be adding quite a bit of hashrate over the next few months. I'm expecting to add 390 TH/s today alone, for example (30 S9s are on their way). We'll probably add a petahash or so by July. All of that hashrate will be going onto the new fork, of course. Edit: Yes, it's Nicehash. The p2pool user 1Hinenj9woDM8wLDffov4PUwFqqtRg5FRu sends regular payments of 2 to 10 btc to 3FNmBkdxorsjf7PFBf4d5JEYBybMicbDin about two times a week, adding funds from 19XLjEswgycrtbX1TcCJ8grw8zZYvbNaG6 as necessary. The 3FN address belongs to Nicehash, and makes regular payouts to Nicehash customers (examples 1 and 2). The 19XL address first sent money to Nicehash (2 BTC via 3FN) on November 6th, 2016. 19XL appears to be a user of Poloniex, as he frequently gets some money from Poloniex's 2nd-biggest wallet 17A16QmavnUfCW11DAApiJxp7ARnxN5pGX (about 0.2 btc every 2 days). The p2pool user 1NVoAeLBm3QLRCcezvwUzKYHDLU96dji8x is directly a customer of nicehash, and sells about 18 kSol/s of Equihash hashpower there (about 0.1 btc/day).(We can't see what he buys. 1NV has sent regular payments of 1.2 to 1.5 btc to 32DdAy7oDoovdxt6egJ2Zoip1sQf25pZs3, which is another Nicehash deposit address. 1Hinen and 1NV have made a ton of money from the recent luck, and has about 30 btc and 6 btc respectively saved up, but they're spending it at a rate of about 20 btc per week. If I'm right and these deposits are being made by a bot, then he can keep it up for about 1.5 weeks with 0% mining luck. If luck remains close to 100% (it has been over 200% recently), then he should be able to hold it up for quite a while, although I presume that Nicehash's fees will run down his balance eventually. That could be a month or two away, though. good analysis! i also see strong evidence that somebody is pushing p2pool with nicehash i really appreciate it. so we have a really strong p2pool and get frequent blocks. but one thing is not so clever - and this goes out especially from Fred to 1NPQQFTE2Loa6YyFiEFiNB2U6Pf58DCk3e aka 1MeD8aT5GAtZVsU5WqpRx8jyXcsYbG437z ( the person will know ): you exaggerate it way too much! ( this is also bad for your own profit ) |
|
|
|
|
kavjlaeg
Newbie
Offline
Activity: 66
Merit: 0
|
|
April 17, 2017, 10:33:48 PM |
|
good analysis?
this is open data.
|
|
|
|
|
|
jtoomim
|
|
April 18, 2017, 08:16:15 AM |
|
I think I've found a good way to solve the replay protection thing and another issue at the same time.
Currently, p2pool weights each share by its difficulty alone. The expected revenue for the pool from each share equals the difficulty times the block reward (with fees). This means that shares with low fees get overcompensated, and shares with high fees get undercompensated, which means that the optimal strategy for most p2pool miners is to make small shares/blocks and hope that the rest of the pool irrationally mines big blocks. This misaligned incentive can be fixed by weighting shares by their difficulty times the block reward they would have generated. Pretty simple. As it affects payment calculations, which need to be precise down to the satoshi, t's a completely backwards-incompatible change, but that's something I want for this fork anyway. Yay! I'm trying to figure out the implementation now. These revenue calculations are done with a SkipList implementation so that p2pool doesn't have to add up every single share's weight every time it assigns new work, and it's taking me a while to understand the code well enough to change it without breaking everything. But I think it will be working soon. Once I've got the calculations correct, I'll deploy them along with a share version change to v64 (just to give the legacy chain room for plenty of upgrades if it continues to be used), and then I think the code will be ready for everyone else to use. After that, I might take a break from coding on p2pool, or I might continue for another week or two. If I continue, I have some ideas for optimizations that could improve p2pool's performance and orphan rates. They fall into two categories: CPU performance, and network performance. For CPU performance, almost all of p2pool's CPU time is spent packing and unpacking shares and transactions between Python objects and serialized bytestreams. I can probably accelerate this process either by rewriting the Python code into faster Python code, simplifying the Python data structures for transactions, and/or adding Cython support. If I go the Cython route, I can make it so that p2pool can run without Cython by stripping the static typing information from the code, but if you have Cython and a C compiler installed (or if you downloaded a binary package), you will use C compiled versions of a couple of the most performance-critical modules. This should give us about the same CPU performance benefit of pypy (or better) without any of pypy's 2GB memory overhead. Improving CPU performance could improve share propagation speed and new work generation, thereby reducing orphan/DOA rates and making revenue allocation more fair. Also, it will make it cheaper to run a p2pool node, and help p2pool scale. For network performance, it seems that the current code has a lot of room for improvement. I'd like to add a new network message that sends a list of transaction hashes to a p2pool peer and asks them to download the corresponding transactions from their bitcoind if possible. This would allow p2pool peers to get most of their transactions via localhost tcp instead of using the p2pool network, which should save a lot of bandwidth. I'd think it would reduce traffic by more than half, since p2pool is a lot more aggressive about forgetting transactions than bitcoind is. Another thing that can be done is to add a shorthash implementation like the one in xthin and compact blocks for share transmission. Once these two optimizations are in place, it should be practical for nodes to send the template of the share they're working on mining *before* it gets mined, and send only the nonce values and miner address once a share is found, at least to one's immediate peers. If I get that done, then I could also teach nodes to encode a message to each peer using the diff between the share being sent and the recipient's current work-in-progress, which would allow 1 MB shares with 95% new transactions to potentially be sent with only a dozen kilobytes or so of one-way traffic in the latency-critical path. After that, maybe I could play with bloom filters or IBLTs and and and... Anyway, first things first. Gonna try to get the properly weighted share rewards done in the next couple of days, and then things should be ready for others to join in on the fork fun. (By the way, my fork is over 1 PH/s of non-rented miners now.) |
Hosting bitcoin miners for $65 to $80/kW/month on clean, cheap hydro power. http://Toom.im |
|
|
Rabinovitch
Legendary
Offline
Activity: 2030
Merit: 1076
BTCLife.global participant
|
|
April 18, 2017, 10:04:21 AM |
|
Also, it will make it cheaper to run a p2pool node, and help p2pool scale.
IMHO to help p2pool scale there should be one or several simple but useful HOWTOs on p2pool node deployment, and these HOWTOs should be constantly kept up-to-date by their maintainers. So every newcomer will be able to deploy a p2pool node completely by himself. Just my two cents. |
|
|
|
leri4
Newbie
Offline
Activity: 6
Merit: 0
|
|
April 18, 2017, 10:34:55 AM |
|
IMHO to help p2pool scale there should be one or several simple but useful HOWTOs on p2pool node deployment, and these HOWTOs should be constantly kept up-to-date by their maintainers. So every newcomer will be able to deploy a p2pool node completely by himself. Just my two cents. I completely agree, for example, it took me more than a month to configure the node. |
|
|
|
|
|
tubexc
|
|
April 18, 2017, 11:05:50 AM |
|
Yes It needed a reliable source with the packages required for a correct installation on windows. Without broken links but updated links p2pool Windows binaries Python >=2.6 Twisted >=10.0.0 python-argparse (for Python =2.6)  What a big mess ( http://p2pool.in/#download ) |
|
|
|
|
|
jtoomim
|
|
April 18, 2017, 11:19:41 AM
Last edit: April 18, 2017, 11:53:21 AM by jtoomim |
|
And the install guide should be translated into Chinese.
|
Hosting bitcoin miners for $65 to $80/kW/month on clean, cheap hydro power. http://Toom.im |
|
|
|
tubexc
|
|
April 18, 2017, 11:29:10 AM |
|
And it should be translated into Chinese.
What ? Which version of python to install or the entire procedure |
|
|
|
|
windpath
Legendary
Offline
Activity: 1258
Merit: 1027
|
|
April 18, 2017, 01:38:33 PM |
|
Also, it will make it cheaper to run a p2pool node, and help p2pool scale.
IMHO to help p2pool scale there should be one or several simple but useful HOWTOs on p2pool node deployment, and these HOWTOs should be constantly kept up-to-date by their maintainers. So every newcomer will be able to deploy a p2pool node completely by himself. Just my two cents. If anyone feels inclined to write such a guide I'd be happy to host it on p2pool.org... |
|
|
|
|
|


