|
fullzero (OP)
|
 |
July 10, 2017, 12:37:30 PM |
|
I think I've figured out why my profitability switcher was having problems with some coins. I noticed it when I tried switching my rig from Genoil back to Claymore (I'm having trouble getting Genoil to run for more than 24 hours without crashing)...the script would run, and I'd end up with two or more instances of the Claymore miner running.
pgrep and pkill, when called with the -f option (to look at the whole command line), need to have "+" escaped for some reason...most likely the pattern is processed as a regular expression and not a simple string. Any miner command string that included "stratum+tcp" (that's basically all of them except the equihash and Genoil daggerhashimoto miners) thus wasn't searchable or killable.
I've committed a fix that should take care of that. It also prepends the search string with "^" to match on the miner process itself, not the screen process that spawned it. (Killing the miner will automatically kill the parent screen process.)
Please test and ensure with confidence; that it is rock solid: then I will integrate these changes. It would be helpful if you did so with the integrated oneBash + switch version I made (swap the relevant part of switch with your updated code); so I can be sure it works as intended. I will be glad to test, just not sure what needs to be changed  I uploaded the Newest oneBash and versions of additional files; including a new switch file that merges salfters changes with the implementation. I did a once over on the new switch / seemed good except for pascal which seemed to reinitialize everytime. |
|
|
|
|
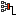
|
mnh_license@proton.me https://github.com/hartmanm How difficulty adjustment works: Every 2016 blocks, the Network adjusts the current difficulty to estimated difficulty in an attempt to keep the block generation time at 10 minutes or 600 seconds. Thus the Network re-targets the difficulty at a total difficulty time of: 2016 blocks * 10 minutes per block = 20160 minutes / 60 minutes = 336 hours / 24 hours = 14 days. When the Network hashrate is increasing; a difficulty ( 2016 blocks ) should take less than 14 days. How much less can be estimated by comparing the % Network hashrate growth + what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ) against what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ). This is only an estimate because you cannot account for "luck"; but you can calculate reasonably well using explicitly delimited stochastic ranges. The easy way to think about this is to look at this graph and see how close to 0 the current data points are on its y axis. If the blue line is above 0 the difficulty ( 2016 ) blocks should take less than 14 days; if it is below it should take more. http://bitcoin.sipa.be/growth-10k.png
|
|
|
lbrasi
Newbie

 Offline Offline
Activity: 26
Merit: 0

|
|
July 10, 2017, 12:44:54 PM |
|
I think I've figured out why my profitability switcher was having problems with some coins. I noticed it when I tried switching my rig from Genoil back to Claymore (I'm having trouble getting Genoil to run for more than 24 hours without crashing)...the script would run, and I'd end up with two or more instances of the Claymore miner running.
pgrep and pkill, when called with the -f option (to look at the whole command line), need to have "+" escaped for some reason...most likely the pattern is processed as a regular expression and not a simple string. Any miner command string that included "stratum+tcp" (that's basically all of them except the equihash and Genoil daggerhashimoto miners) thus wasn't searchable or killable.
I've committed a fix that should take care of that. It also prepends the search string with "^" to match on the miner process itself, not the screen process that spawned it. (Killing the miner will automatically kill the parent screen process.)
Please test and ensure with confidence; that it is rock solid: then I will integrate these changes. It would be helpful if you did so with the integrated oneBash + switch version I made (swap the relevant part of switch with your updated code); so I can be sure it works as intended. I will be glad to test, just not sure what needs to be changed I uploaded the Newest oneBash and versions of additional files; including a new switch file that merges salfters changes with the implementation. I did a once over on the new switch / seemed good except for pascal which seemed to reinitialize everytime. Awesome let me try this out... |
|
|
|
|
|
fullzero (OP)
|
|
July 10, 2017, 12:46:07 PM |
|
How tricky would it be to use the nvidia-settings commands from within oneBash to run the following command recursively for each card that's detected when it runs, rather than setting a specific power limit or clock offset?
Enable PowerMizer (Prefer Maximum Performance)
nvidia-settings -a '[gpu:0]/GPUPowerMizerMode=1'
essentially this, but with more efficient code because I never was good at foreach loops and such...
if [ $POWERLIMIT == "NO" ]
then
sudo nvidia-settings -a '[gpu:0]/GPUPowerMizerMode=1'
sudo nvidia-settings -a '[gpu:1]/GPUPowerMizerMode=1'
sudo nvidia-settings -a '[gpu:2]/GPUPowerMizerMode=1'
sudo nvidia-settings -a '[gpu:3]/GPUPowerMizerMode=1'
sudo nvidia-settings -a '[gpu:4]/GPUPowerMizerMode=1'
sudo nvidia-settings -a '[gpu:5]/GPUPowerMizerMode=1'
fi I was going to rewrite exactly these parts of script since I also don't like such code. But before doing so I asked (in another rxOC thread) to put oneBash files to GitHub repository, so such changes will not be like a monkey work to copy/paste a lot. Until that I feel no motivation since I have only couple of rigs with 1050 running nvOC. It might change when I receive 12 PCIe MOBO (waiting for Biostar board from Aliexpress). But I am pretty sure that git is the best way to handle a lot of change requests and integrate them into this great distro or run just own branch. PS. I was talking about putting oneBash only to a repository, not about full distribution. I understood that you meant to add oneBash only for github. Look at the number of changes in this oneBash alone; and then consider how much more there would be to look at with input from even a few members. Until most of the features members want have a basic implementation; this is essentially only going to give me another thing I need to pay attention to. Granted if you have a suggestion, you can always make a post here like you did. I uploaded the Newest oneBash and versions of additional files; I added a GPUPowerMizerMode implementation. oneBash is not only an implementation; it is also a learning experience for many members. This is the primary reason I don't use loops / nested loops; everywhere I could. I will change them out eventually. |
|
|
|
|
|
mnh_license@proton.me https://github.com/hartmanm How difficulty adjustment works: Every 2016 blocks, the Network adjusts the current difficulty to estimated difficulty in an attempt to keep the block generation time at 10 minutes or 600 seconds. Thus the Network re-targets the difficulty at a total difficulty time of: 2016 blocks * 10 minutes per block = 20160 minutes / 60 minutes = 336 hours / 24 hours = 14 days. When the Network hashrate is increasing; a difficulty ( 2016 blocks ) should take less than 14 days. How much less can be estimated by comparing the % Network hashrate growth + what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ) against what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ). This is only an estimate because you cannot account for "luck"; but you can calculate reasonably well using explicitly delimited stochastic ranges. The easy way to think about this is to look at this graph and see how close to 0 the current data points are on its y axis. If the blue line is above 0 the difficulty ( 2016 ) blocks should take less than 14 days; if it is below it should take more. http://bitcoin.sipa.be/growth-10k.png
|
|
|
|
fullzero (OP)
|
|
July 10, 2017, 12:59:58 PM |
|
Thanks for links.  You bet.. If you get a second, i posted a while back about an issue I'm having in 0017 where one card runs at 66% capacity while the others are at 100%. I'm just wondering if that's something you've seen before, and if there might be a straight forward solution to it. If not, I'll probably just wait until I swap boards in a few days to mess with it since otherwise it's running solid as a rock with all 6 gpus. Is the hashrate lower with the GPU running at 66%? Hey FZ - just wanted to let you know I resolved the issue with my underpowered GPU... turns out having 2 risers on one SATA power line is frowned upon... once I put all the GPUs on their own lines the system is back up at 100% With 1080 or 1080ti that is best; especially if they are AM models. I haven't heard of anyone needing to do this with 1070s or 1060s; what type of GPUs are you using? I've got: 2x asus dual 1070 3x EVGA superclock 1070 1x Nvidia 1070 FE in the x16 slot Asrock z270 Killer SLI/AC mobo (no external power to mobo for pcie (no option for it)) dual 750w PSUs - 1x evga and 1x thermaltake 64gb USB 3 stick No 1080s in this rig atm, though I had a 1080 ti in there yesterday in the x16 slot so no riser but the problems I've had arose with all 1070s Before, I had it setup so that: 2 risers were powered on one molex power line 2 riser on 1 SATA lines 3x 1070 each on its own power line (450w); and mobo/cpu all on the EVGA 750w psu; [all of that should be well within the acceptable range of draw from the PSU] Then the other 3 1070 GPUs and 1 riser on molex were powered by the 750w thermaltake [again, well within the total power load taking overhead into account] New setup splits the risers between the PSUs 2 go to separate lines on the EVGA, the other 3 on separate lines on the thermaltake, all on SATA power cables except 1 (though that shouldn't make a difference), and the risers are powered by the same PSU as the GPU main power is coming from whereas before they weren't. the mobo/cpu are still on the primary EVGA PSU, and the thermaltake is connected by a Y splitter ATX cable. The result is that the more even power load resolved the problem, though I can't be absolutely certain it was solved by splitting the risers to different lines exclusively. Which driver version are you using? Also do you know which GPU model was the one that was insufficiently powered? I think driver 381.22 is installed right now. The cards that were underpowered were EVGA superclock 1070s, I had two of them on one SATA power cable and neither one worked properly that way. Once their risers were on their own lines they work great. Now I'm not seeing any dips in power - all cards are 100% and pulling about 3.25 sol / watt. Maybe the new driver pulls more power from the PCIe slot; I will have to test for this on more rigs. If it is the case; it will likely cause many previously stable 1070 rigs using 1x sata per every 2 GPUs to become unstable. |
|
|
|
|
|
mnh_license@proton.me https://github.com/hartmanm How difficulty adjustment works: Every 2016 blocks, the Network adjusts the current difficulty to estimated difficulty in an attempt to keep the block generation time at 10 minutes or 600 seconds. Thus the Network re-targets the difficulty at a total difficulty time of: 2016 blocks * 10 minutes per block = 20160 minutes / 60 minutes = 336 hours / 24 hours = 14 days. When the Network hashrate is increasing; a difficulty ( 2016 blocks ) should take less than 14 days. How much less can be estimated by comparing the % Network hashrate growth + what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ) against what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ). This is only an estimate because you cannot account for "luck"; but you can calculate reasonably well using explicitly delimited stochastic ranges. The easy way to think about this is to look at this graph and see how close to 0 the current data points are on its y axis. If the blue line is above 0 the difficulty ( 2016 ) blocks should take less than 14 days; if it is below it should take more. http://bitcoin.sipa.be/growth-10k.png
|
|
|
|
fullzero (OP)
|
|
July 10, 2017, 01:04:55 PM |
|
I will add it to the list. As this is a multi algo coin; do you know which algo is generally the best to mine with Nvidia GPUs? |
|
|
|
|
|
mnh_license@proton.me https://github.com/hartmanm How difficulty adjustment works: Every 2016 blocks, the Network adjusts the current difficulty to estimated difficulty in an attempt to keep the block generation time at 10 minutes or 600 seconds. Thus the Network re-targets the difficulty at a total difficulty time of: 2016 blocks * 10 minutes per block = 20160 minutes / 60 minutes = 336 hours / 24 hours = 14 days. When the Network hashrate is increasing; a difficulty ( 2016 blocks ) should take less than 14 days. How much less can be estimated by comparing the % Network hashrate growth + what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ) against what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ). This is only an estimate because you cannot account for "luck"; but you can calculate reasonably well using explicitly delimited stochastic ranges. The easy way to think about this is to look at this graph and see how close to 0 the current data points are on its y axis. If the blue line is above 0 the difficulty ( 2016 ) blocks should take less than 14 days; if it is below it should take more. http://bitcoin.sipa.be/growth-10k.png
|
|
|
|
Maxximus007
|
|
July 10, 2017, 01:16:55 PM |
|
please help. How can i add dcri argument to my onebash settings? what and where exactly i should whrite?
It's not set by default in oneBash So you can set it in $ETH_EXTENTION_ARGUMENTS. Use 40 or even 20 (depending your cards etc). ETH_EXTENTION_ARGUMENTS="" # add any additional claymore arguments desired here
So: ETH_EXTENTION_ARGUMENTS="-dcri 40" # add any additional claymore arguments desired here
Thankyou When dual mining it requires a lot more power, my dual mining rig I have to have minimum 120 watts. This is on Claymore 9.7. 6x 1070 rig dcri 20 Core: -200 Mem: 1210-1270 Stats: ETH - Total Speed: 186.968 Mh/s, Total Shares: 410(85+78+67+77+66+54), Rejected: 0, Time: 03:04 ETH: GPU0 31.300 Mh/s, GPU1 31.268 Mh/s, GPU2 31.224 Mh/s, GPU3 30.860 Mh/s, GPU4 31.256 Mh/s, GPU5 31.059 Mh/s SC - Total Speed: 1246.454 Mh/s, Total Shares: 81(15+16+8+14+17+11), Rejected: 0 SC: GPU0 208.669 Mh/s, GPU1 208.454 Mh/s, GPU2 208.163 Mh/s, GPU3 205.734 Mh/s, GPU4 208.372 Mh/s, GPU5 207.062 Mh/s Incorrect ETH shares: none 1 minute average ETH total speed: 186.468 Mh/s Thanks! Will try with your power values. Seems that we need to have a conditional block with OC values depending on the mined coin and used miner in oneBash  .. |
|
|
|
|
tempgoga
Newbie
Offline
Activity: 29
Merit: 0
|
|
July 10, 2017, 01:28:35 PM |
|
Hey fullzero, i have a question,
without a doubt my biggest problem right now is that when my miner crashes it takes the whole rig down with it, everything gets stuck, SSH barely works, average system load jumps to 14.5!! and Xorg takes up 100% of the CPU, its so bad that none of the standard reboot commands work, they just do nothing, the only thing that actually reboots the rig in this state is "echo b > /proc/sysrq-trigger" so i've set up a script that checks the average system load and if its over 2 it uses the command to reboot, and it works, but i dont like this "solution", yesterday after a reboot nvOC got corrupted somehow, lost my customized oneBash and the whole system became read-only (thankfully i had a oneBash backup that was only a few days behind).
so the question is, what can i do to relive this Xorg error, i run a 7 card rig and never plan on going for a higher number, what can i do with Xorg that would fix this?
Thanks.
|
|
|
|
|
nklak
Newbie
Offline
Activity: 6
Merit: 9
|
|
July 10, 2017, 01:50:44 PM |
|
Hi,
I have few Gigabyte Z270-gaming K3 mobos...they have killer networks E2500 LAN and nvOC boots without LAN. I assume there is no driver support in this distribution. So can you tell me how to install LAN driver, manually or can it be inserted in next version (18) ?.
Or any other solution...
Let me know
Best regards
|
|
|
|
|
|
Maxximus007
|
|
July 10, 2017, 01:51:36 PM |
|
@fullzero, great to see the new oneBash with lots of stuff integrated! I made a small error in the autotemp code: { IFS=', ' read CURRENT_TEMP CURRENT_FAN POWERDRAW POWERLIMIT; } < <( nvidia-smi -i 1 --query-gpu=temperature.gpu,fan.speed,power.draw,power.limit --format=csv,noheader,nounits)
This needs to be: { IFS=', ' read CURRENT_TEMP CURRENT_FAN POWERDRAW POWERLIMIT; } < <( nvidia-smi -i $gpu --query-gpu=temperature.gpu,fan.speed,power.draw,power.limit --format=csv,noheader,nounits)
In the current code it only checks the second GPU, and applies it for all. Sorry for that. |
|
|
|
|
|
xleejohnx
|
|
July 10, 2017, 03:14:28 PM |
|
I have had a lot of requests for this; so here is a new oneBash and modded switch file which implement full integration of SALFTER_NICEHASH_PROFIT_SWITCHING see the OP for links: Replace your current oneBash with the new one. extract switch and move it to the: directory (the one which opens when you click the Files icon on the left) configure the following in oneBash SALFTER_NICEHASH_PROFIT_SWITCHING="YES"
# LOCAL will attach the mining process to the guake terminal
# REMOTE will leave it unattached / ready for SSH
LOCALorREMOTE="LOCAL" # LOCAL or REMOTE
CURRENCY=USD
POWER_COST=0.10
MINIMUM_PROFIT=0.0
# this is salfters BTC address:
PAYMENT_ADDRESS=1TipsGocnz2N5qgAm9f7JLrsMqkb3oXe2
WORKER_NAME=nv$IP_AS_WORKER
daggerhashimoto_POWERLIMIT_WATTS=125
__daggerhashimoto_CORE_OVERCLOCK=100
daggerhashimoto_MEMORY_OVERCLOCK=100
_______daggerhashimoto_FAN_SPEED=75
equihash_POWERLIMIT_WATTS=125
__equihash_CORE_OVERCLOCK=100
equihash_MEMORY_OVERCLOCK=100
_______equihash_FAN_SPEED=75
neoscrypt_POWERLIMIT_WATTS=125
__neoscrypt_CORE_OVERCLOCK=100
neoscrypt_MEMORY_OVERCLOCK=100
_______neoscrypt_FAN_SPEED=75
lyra2rev2_POWERLIMIT_WATTS=125
__lyra2rev2_CORE_OVERCLOCK=100
lyra2rev2_MEMORY_OVERCLOCK=100
_______lyra2rev2_FAN_SPEED=75
lbry_POWERLIMIT_WATTS=125
__lbry_CORE_OVERCLOCK=100
lbry_MEMORY_OVERCLOCK=100
_______lbry_FAN_SPEED=75
pascal_POWERLIMIT_WATTS=125
__pascal_CORE_OVERCLOCK=100
pascal_MEMORY_OVERCLOCK=100
_______pascal_FAN_SPEED=75 remember to thank salfter if you use this i havent been on in awhile to see if this question has been asked but how do we set individual limits with this i dont want my 1060s running the same as a 1080ti in the same system any help would be nice thanks |
As I see a super coin as the super highway and alt coins as taxis and trucks needed to move transactions. ~philipma1957
|
|
|
damNmad
Full Member
Offline
Activity: 378
Merit: 104
nvOC forever
|
|
July 10, 2017, 03:23:33 PM
Last edit: July 10, 2017, 03:51:00 PM by damNmad |
|
1First configure this section of oneBash: SALFTER_NICEHASH_PROFIT_SWITCHING="YES"
# LOCAL will attach the mining process to the guake terminal
# REMOTE will leave it unattached / ready for SSH
LOCALorREMOTE="LOCAL" # LOCAL or REMOTE
CURRENCY=USD
POWER_COST=0.10
MINIMUM_PROFIT=0.0
# this is salfters BTC address:
PAYMENT_ADDRESS=1TipsGocnz2N5qgAm9f7JLrsMqkb3oXe2
WORKER_NAME=nv$IP_AS_WORKER
daggerhashimoto_POWERLIMIT_WATTS=125
__daggerhashimoto_CORE_OVERCLOCK=100
daggerhashimoto_MEMORY_OVERCLOCK=100
_______daggerhashimoto_FAN_SPEED=75
equihash_POWERLIMIT_WATTS=125
__equihash_CORE_OVERCLOCK=100
equihash_MEMORY_OVERCLOCK=100
_______equihash_FAN_SPEED=75
neoscrypt_POWERLIMIT_WATTS=125
__neoscrypt_CORE_OVERCLOCK=100
neoscrypt_MEMORY_OVERCLOCK=100
_______neoscrypt_FAN_SPEED=75
lyra2rev2_POWERLIMIT_WATTS=125
__lyra2rev2_CORE_OVERCLOCK=100
lyra2rev2_MEMORY_OVERCLOCK=100
_______lyra2rev2_FAN_SPEED=75
lbry_POWERLIMIT_WATTS=125
__lbry_CORE_OVERCLOCK=100
lbry_MEMORY_OVERCLOCK=100
_______lbry_FAN_SPEED=75
pascal_POWERLIMIT_WATTS=125
__pascal_CORE_OVERCLOCK=100
pascal_MEMORY_OVERCLOCK=100
_______pascal_FAN_SPEED=75 ensure: SALFTER_NICEHASH_PROFIT_SWITCHING="YES" and replace salfters BTC address with your own: PAYMENT_ADDRESS=1TipsGocnz2N5qgAm9f7JLrsMqkb3oXe2 salfter implemented this for nicehash only. It makes a call to a nicehash api and receives the current profitability data. Using your input power cost (and what I am guessing are salfters benchmarks for each algo using 2x 1070s) it calculates which coin is currently the most profitable to mine. It then stops any mining process, and starts a new one with the most profitable coin and your OC settings for that coin. ================================================================================ SALFTER_NICEHASH_PROFIT_SWITCHING="YES"
# LOCAL will attach the mining process to the guake terminal
# REMOTE will leave it unattached / ready for SSH
LOCALorREMOTE="LOCAL" # LOCAL or REMOTE
CURRENCY=USD
POWER_COST=0.20
MINIMUM_PROFIT=2.5
# this is salfters BTC address:
PAYMENT_ADDRESS=1QJ6j3fY6fCRsN1WJqZ65U52Et4TVL9e7P
WORKER_NAME=$IP_AS_WORKER
daggerhashimoto_POWERLIMIT_WATTS=95
__daggerhashimoto_CORE_OVERCLOCK=150
daggerhashimoto_MEMORY_OVERCLOCK=1200
_______daggerhashimoto_FAN_SPEED=65
equihash_POWERLIMIT_WATTS=95
__equihash_CORE_OVERCLOCK=150
equihash_MEMORY_OVERCLOCK=1200
_______equihash_FAN_SPEED=65
neoscrypt_POWERLIMIT_WATTS=95
__neoscrypt_CORE_OVERCLOCK=150
neoscrypt_MEMORY_OVERCLOCK=1200
_______neoscrypt_FAN_SPEED=65
lyra2rev2_POWERLIMIT_WATTS=95
__lyra2rev2_CORE_OVERCLOCK=150
lyra2rev2_MEMORY_OVERCLOCK=1200
_______lyra2rev2_FAN_SPEED=65
lbry_POWERLIMIT_WATTS=95
__lbry_CORE_OVERCLOCK=150
lbry_MEMORY_OVERCLOCK=1200
_______lbry_FAN_SPEED=65
pascal_POWERLIMIT_WATTS=95
__pascal_CORE_OVERCLOCK=150
pascal_MEMORY_OVERCLOCK=1200
_______pascal_FAN_SPEED=65 I've done the above, mining hasn't started (have i missed to copy/include anything?), I'm using v0017 as is (My Mob is Asus Z270P with 8 GTX 6G 1060's) Saw this as output : m1@m1-desktop:~$ screen -r miner
There is no screen to be resumed matching miner.
m1@m1-desktop:~$ screen -r miner
There is no screen to be resumed matching miner.
m1@m1-desktop:~$
================================================================================ 2You can use the SALFTER_NICEHASH_PROFIT_SWITCHING, or you can use the: COIN selection I still need to add all the other nicehash algos as normal COIN selections. Nicehash does use a BTC payout address, when using the NICE_ETHASH COIN selection set this in this area of the oneBash settings: # if YES ensure you update BTC_ADDRESS
VTC_AUTOCONVERT_TO_BTC="YES" #YES NO
VTC_WORKER="nv$IP_AS_WORKER"
VTC_ADDRESS="VsvtYL2mz3YFM3fpt5pb28zHodTbnJodRc"
VTC_POOL="stratum+tcp://lyra2v2.mine.zpool.ca:4533"
BTC_ADDRESS="18Y5HYe3BAwAhTAkFLbD52o8NqtrN3DtpF"
# NICE_ETHASH autoconverts to BTC: ensure you update BTC_ADDRESS if you use NICE_ETHASH
NICE_ETHASH_WORKER="nv$IP_AS_WORKER"
NICE_ETHASH_POOL="stratum+tcp://daggerhashimoto.usa.nicehash.com:3353"
GENOIL_NICE_ETHASH_POOL="daggerhashimoto.usa.nicehash.com:3353"
NICE_ETHASH_EXTENTION_ARGUMENTS="" # add any additional claymore arguments desired here this line: BTC_ADDRESS="18Y5HYe3BAwAhTAkFLbD52o8NqtrN3DtpF" ================================================================================ I've added my BTC address, if I run the oneBash with 'NICE_ETHASH' coin selection, which coin does it mines? (I know you said there is no coin selection/algos currently, just curious to know what it selects and mine) No matter what it mines, will it just coverts into BTC and pay to my BTC address? I've tried it using my BTC address for a while, it has started mining but not sure what it was mining (it was using Genoil)!, but saw ETH share accepted message most of the times ("stratum+tcp://daggerhashimoto.usa.nicehash.com:3353") Also where can I check how many shares per our stats related to my BTC address or Miner while mining with 'NICE_ETHASH' ================================================================================ 3at the top of oneBash ensure COIN is set to: then set your ETH settings here: ETHERMINEdotORG="NO"
CLAYMORE_VERSION="9_5" # choose 9_5 or 9_4 or 8_0
GENOILorCLAYMORE="GENOIL" # choose GENOIL or CLAYMORE
ETH_WORKER="nv$IP_AS_WORKER"
ETH_ADDRESS="0xe12bdd454997e443ec0cae6bebb6bb3c74242aae"
ETH_POOL="eth-us-east1.nanopool.org:9999"
ETH_EXTENTION_ARGUMENTS="" # add any additional claymore arguments desired here then set your DCR settings here: DCR_WORKER="nv$IP_AS_WORKER"
DCR_ADDRESS="fullzero22"
DCR_POOL="stratum+tcp://dcr.suprnova.cc:3252" Note that with supernova you need to set the workername beforehand, so I recommend changing the workername to whatever you have set already rather than making a new worker with the auto generated workername. replace: DCR_ADDRESS="fullzero22" with your supernova username Let me know if all this makes sense. ================================================================================ Yes it does makes sense, some of it, now I'm able to mine DCR with suprnova, using Claymore 9_7, Thanks for that Amigo But I still have some questions regarding NICE HASH mining, can we mine any coin with nicehash pools? How can we check share rate while using nicehash pools (daggerhashimoto ?)? I may still need some help to understand my 2nd question, will try to google and find some info, Thank you so much for the replies mate, that really means a lot to people like me, wish I could give something back to community like you are doing ================================================================================ |
|
|
|
RonaldMcDongle
Newbie
Offline
Activity: 9
Merit: 0
|
|
July 10, 2017, 03:24:26 PM |
|
I will add it to the list. As this is a multi algo coin; do you know which algo is generally the best to mine with Nvidia GPUs? The myriad-groestl algo seems to be the best for me, I mentioned this a few pages back. |
|
|
|
|
|
salfter
|
|
July 10, 2017, 03:30:50 PM |
|
I think I've figured out why my profitability switcher was having problems with some coins. I noticed it when I tried switching my rig from Genoil back to Claymore (I'm having trouble getting Genoil to run for more than 24 hours without crashing)...the script would run, and I'd end up with two or more instances of the Claymore miner running.
pgrep and pkill, when called with the -f option (to look at the whole command line), need to have "+" escaped for some reason...most likely the pattern is processed as a regular expression and not a simple string. Any miner command string that included "stratum+tcp" (that's basically all of them except the equihash and Genoil daggerhashimoto miners) thus wasn't searchable or killable.
I've committed a fix that should take care of that. It also prepends the search string with "^" to match on the miner process itself, not the screen process that spawned it. (Killing the miner will automatically kill the parent screen process.)
Please test and ensure with confidence; that it is rock solid: then I will integrate these changes. It would be helpful if you did so with the integrated oneBash + switch version I made (swap the relevant part of switch with your updated code); so I can be sure it works as intended. The script looks like it's stopping and starting miners properly, but that has only caused another problem to surface: GPUs start crashing on the switch, and the only way to reboot is either SysRq-B or the reset switch. I've had this problem in the past with my other switchers; if I had to guess, some miners leave the GPU in a state that other miners don't expect when they start up. I've done some testing with shell scripts that shows a way forward: stop the previous miner, stop X, unload the nVidia driver, reload the driver, restart X, and start the next miner. This puts the GPUs back to a known-good state before getting back to mining. I've switched back and forth between a known-troublesome pair of miners, and it hasn't failed yet. I'm going to put these changes into the switcher next and see how it goes. |
|
|
|
lost_post
Newbie
Offline
Activity: 13
Merit: 0
|
|
July 10, 2017, 03:32:53 PM |
|
Hi fullzero. Thanks for your great work. I am using your bash and I rewrite some parts for my own needs. I have some suggestions you can use "export INDIVIDUAL_POWERLIMIT_0 ....." instead of using echo $INDIVIDUAL_POWERLIMIT_0 > '/home/m1/p0'
and
POWER_LIMIT[0]=$(cat /home/m1/p0 | sed '/ /d')
and
rm /home/m1/p0 Just write "export ALL YOUR variables" that you need in next bash, before running bash file. IN bash file you can just call them as always. I added an email notification when certain conditions are being met. Put all the control code in a separate file, the settings of wallets in a separate file, the settings of the cards are in another file, fans control ins a separate file, emails send is also a separate file. Also made a web page on which using iframes and gotty https://github.com/yudai/gotty you can watch GPU mining process, CPU mining process and card info (temp, fans, power draw and so on). If someone is interesting in these features - white, and I will post my code. |
|
|
|
|
IAmNotAJeep
Newbie
Offline
Activity: 44
Merit: 0
|
|
July 10, 2017, 05:24:38 PM |
|
Hey fullzero, i have a question,
without a doubt my biggest problem right now is that when my miner crashes it takes the whole rig down with it, everything gets stuck, SSH barely works, average system load jumps to 14.5!! and Xorg takes up 100% of the CPU, its so bad that none of the standard reboot commands work, they just do nothing, the only thing that actually reboots the rig in this state is "echo b > /proc/sysrq-trigger" so i've set up a script that checks the average system load and if its over 2 it uses the command to reboot, and it works, but i dont like this "solution", yesterday after a reboot nvOC got corrupted somehow, lost my customized oneBash and the whole system became read-only (thankfully i had a oneBash backup that was only a few days behind).
so the question is, what can i do to relive this Xorg error, i run a 7 card rig and never plan on going for a higher number, what can i do with Xorg that would fix this?
Thanks.
@ tempgoga It seems that whenever a soft crash occurs most of the cards drop to zero, so while the display/keyboard is unresponsive you can catch the soft crash from nvidia-smi. The script below checks card utilization, if it drops below 90% it counts down a minute and if mining hasn't resumed it reboots the system. This seems to have worked at least once in my case (only got one soft crash this weekend) and the system recovered as expected. the threshold values work for my setup but others may find different values optimal Also if anyone knows a way to iterate the if && statements we can get the card count from "cards=$(nvidia-smi -L | wc -l); echo $cards" but the way below also works with manual editing to adjust the watchdog for the number of cards in you individual system. ___________ #!/bin/bash #m1 threshold=90 while sleep 5 do number=$(nvidia-smi |grep % |awk '{print $13}' |tr -d %) set -- $number echo -e "$@" # The "if and" statements below need to be manually adjusted to match the number of cards in your system # If you have 5 cards, leave is as, if a different number of cards remove or add the && statements as needed as in the example below if [[ "$1" -gt "$threshold" ]] && \ [[ "$2" -gt "$threshold" ]] && \ [[ "$3" -gt "$threshold" ]] && \ [[ "$4" -gt "$threshold" ]] && \ [[ "$5" -gt "$threshold" ]] # && \ # [[ "$6" -gt "$threshold" ]] then i=12 echo OK else echo $((i--)) fi if [ $i -le 0 ] then echo $(date) REBOOT due to soft crash >>~/watchdog.log sleep -5 sudo shutdown now -r fi done ___________ |
|
|
|
|
|
Maxximus007
|
|
July 10, 2017, 05:45:37 PM
Last edit: July 10, 2017, 05:57:05 PM by Maxximus007 |
|
Hey fullzero, i have a question,
without a doubt my biggest problem right now is that when my miner crashes it takes the whole rig down with it, everything gets stuck, SSH barely works, average system load jumps to 14.5!! and Xorg takes up 100% of the CPU, its so bad that none of the standard reboot commands work, they just do nothing, the only thing that actually reboots the rig in this state is "echo b > /proc/sysrq-trigger" so i've set up a script that checks the average system load and if its over 2 it uses the command to reboot, and it works, but i dont like this "solution", yesterday after a reboot nvOC got corrupted somehow, lost my customized oneBash and the whole system became read-only (thankfully i had a oneBash backup that was only a few days behind).
so the question is, what can i do to relive this Xorg error, i run a 7 card rig and never plan on going for a higher number, what can i do with Xorg that would fix this?
Thanks.
@ tempgoga It seems that whenever a soft crash occurs most of the cards drop to zero, so while the display/keyboard is unresponsive you can catch the soft crash from nvidia-smi. The script below checks card utilization, if it drops below 90% it counts down a minute and if mining hasn't resumed it reboots the system. This seems to have worked at least once in my case (only got one soft crash this weekend) and the system recovered as expected. the threshold values work for my setup but others may find different values optimal Also if anyone knows a way to iterate the if && statements we can get the card count from "cards=$(nvidia-smi -L | wc -l); echo $cards" but the way below also works with manual editing to adjust the watchdog for the number of cards in you individual system. ___________ #!/bin/bash #m1 threshold=90 while sleep 5 do number=$(nvidia-smi |grep % |awk '{print $13}' |tr -d %) set -- $number echo -e "$@" # The "if and" statements below need to be manually adjusted to match the number of cards in your system # If you have 5 cards, leave is as, if a different number of cards remove or add the && statements as needed as in the example below if [[ "$1" -gt "$threshold" ]] && \ [[ "$2" -gt "$threshold" ]] && \ [[ "$3" -gt "$threshold" ]] && \ [[ "$4" -gt "$threshold" ]] && \ [[ "$5" -gt "$threshold" ]] # && \ # [[ "$6" -gt "$threshold" ]] then i=12 echo OK else echo $((i--)) fi if [ $i -le 0 ] then echo $(date) REBOOT due to soft crash >>~/watchdog.log sleep -5 sudo shutdown now -r fi done ___________ Hey thats funny I just made a script doing something similar, although it checks the powerdraw. Here it is: #!/bin/bash
# Miner restart script V001
# By Maxximus007
# for nvOC by fullzero
#
# POWERLIMIT MUST BE SET IN oneBash
#########################
### BELOW CODE, NO NEED FOR EDITING
#########################
echo "$(date) - Starting miner restart script." | tee -a ${LOG_FILE}
# Creating a log file to record restarts
LOG_FILE="/home/m1/restartlog.txt"
if [ ! -e "$LOG_FILE" ] ; then
touch "$LOG_FILE"
fi
while true
do
sleep 60
GPUS=$(nvidia-smi --query-gpu=count --format=csv,noheader,nounits | tail -1)
gpu=0
COUNT_LOW_POWER=0
while [ $gpu -lt $GPUS ]
do
{ IFS=', ' read POWERDRAW POWERLIMIT; } < <( nvidia-smi -i $gpu --query-gpu=power.draw,power.limit --format=csv,noheader,nounits)
let POWER_DIFF=$( printf "%.0f" $POWERLIMIT )-$( printf "%.0f" $POWERDRAW )
# If current draw is 30 Watt lower than the limit count them:
if [ "$POWER_DIFF" -gt "30" ]
then
let COUNT_LOW_POWER=COUNT_LOW_POWER+1
fi
let gpu=gpu+1
done
if [ $COUNT_LOW_POWER -eq $GPUS ]
then
echo "$(date) - Power draw is too low: kill miner and oneBash" | tee -a ${LOG_FILE}
# If miner runs in screen 'miner' kill the screen
screen -X -S miner kill
# Best to restart oneBash - settings might be adjusted already
kill ps -ef | awk '$NF~"oneBash" {print $2}'
else
echo "$(date) - All good! Will check again in 60 seconds"
fi
done
You can combine the above with your code, and find the utilization like this: nvidia-smi -i 1 --query-gpu=utilization.gpu --format=csv,noheader,nounits You have to iterate the GPU, starting at 0 to get them all |
|
|
|
|
|
fk1
|
|
July 10, 2017, 05:57:16 PM
Last edit: July 10, 2017, 11:03:59 PM by fk1 |
|
Since I got problems with w10 I decided to give this distro a try and I am very surprised things went so easy, good job at this one!
I use this on a headlesss rig and atm I only know that this rig is running by checking pool URL or loginto it with SSH and using nvidia-smi for checking temps.
I am struggling with administrating, a couple of questions:
1. how can I get the terminal output of the automatic starting process (claymore) over SSH?
2. I configured teamviewer to start but how can I connectto it when I can't see the desktop?
3. On Windows,when mining monero with xmr-stak-cpu I was ableto achive about 200-250h/s with my amd fx6300. on the wolfminer its 100~150. Any tweaking options or possible to change to stak-miner?
keep up the good work!
|
|
|
|
|
|
Maxximus007
|
|
July 10, 2017, 06:09:08 PM |
|
Hey fullzero, i have a question,
without a doubt my biggest problem right now is that when my miner crashes it takes the whole rig down with it, everything gets stuck, SSH barely works, average system load jumps to 14.5!! and Xorg takes up 100% of the CPU, its so bad that none of the standard reboot commands work, they just do nothing, the only thing that actually reboots the rig in this state is "echo b > /proc/sysrq-trigger" so i've set up a script that checks the average system load and if its over 2 it uses the command to reboot, and it works, but i dont like this "solution", yesterday after a reboot nvOC got corrupted somehow, lost my customized oneBash and the whole system became read-only (thankfully i had a oneBash backup that was only a few days behind).
so the question is, what can i do to relive this Xorg error, i run a 7 card rig and never plan on going for a higher number, what can i do with Xorg that would fix this?
Thanks.
@ tempgoga It seems that whenever a soft crash occurs most of the cards drop to zero, so while the display/keyboard is unresponsive you can catch the soft crash from nvidia-smi. The script below checks card utilization, if it drops below 90% it counts down a minute and if mining hasn't resumed it reboots the system. This seems to have worked at least once in my case (only got one soft crash this weekend) and the system recovered as expected. the threshold values work for my setup but others may find different values optimal Also if anyone knows a way to iterate the if && statements we can get the card count from "cards=$(nvidia-smi -L | wc -l); echo $cards" but the way below also works with manual editing to adjust the watchdog for the number of cards in you individual system. ___________ #!/bin/bash #m1 threshold=90 while sleep 5 do number=$(nvidia-smi |grep % |awk '{print $13}' |tr -d %) set -- $number echo -e "$@" # The "if and" statements below need to be manually adjusted to match the number of cards in your system # If you have 5 cards, leave is as, if a different number of cards remove or add the && statements as needed as in the example below if [[ "$1" -gt "$threshold" ]] && \ [[ "$2" -gt "$threshold" ]] && \ [[ "$3" -gt "$threshold" ]] && \ [[ "$4" -gt "$threshold" ]] && \ [[ "$5" -gt "$threshold" ]] # && \ # [[ "$6" -gt "$threshold" ]] then i=12 echo OK else echo $((i--)) fi if [ $i -le 0 ] then echo $(date) REBOOT due to soft crash >>~/watchdog.log sleep -5 sudo shutdown now -r fi done ___________ Hey thats funny I just made a script doing something similar, although it checks the powerdraw. Here it is: #!/bin/bash
# Miner restart script V001
# By Maxximus007
# for nvOC by fullzero
#
# POWERLIMIT MUST BE SET IN oneBash
#########################
### BELOW CODE, NO NEED FOR EDITING
#########################
echo "$(date) - Starting miner restart script." | tee -a ${LOG_FILE}
# Creating a log file to record restarts
LOG_FILE="/home/m1/restartlog.txt"
if [ ! -e "$LOG_FILE" ] ; then
touch "$LOG_FILE"
fi
while true
do
sleep 60
GPUS=$(nvidia-smi --query-gpu=count --format=csv,noheader,nounits | tail -1)
gpu=0
COUNT_LOW_POWER=0
while [ $gpu -lt $GPUS ]
do
{ IFS=', ' read POWERDRAW POWERLIMIT; } < <( nvidia-smi -i $gpu --query-gpu=power.draw,power.limit --format=csv,noheader,nounits)
let POWER_DIFF=$( printf "%.0f" $POWERLIMIT )-$( printf "%.0f" $POWERDRAW )
# If current draw is 30 Watt lower than the limit count them:
if [ "$POWER_DIFF" -gt "30" ]
then
let COUNT_LOW_POWER=COUNT_LOW_POWER+1
fi
let gpu=gpu+1
done
if [ $COUNT_LOW_POWER -eq $GPUS ]
then
echo "$(date) - Power draw is too low: kill miner and oneBash" | tee -a ${LOG_FILE}
# If miner runs in screen 'miner' kill the screen
screen -X -S miner kill
# Best to restart oneBash - settings might be adjusted already
kill ps -ef | awk '$NF~"oneBash" {print $2}'
else
echo "$(date) - All good! Will check again in 60 seconds"
fi
done
You can combine the above with your code, and find the utilization like this: nvidia-smi -i 1 --query-gpu=utilization.gpu --format=csv,noheader,nounits You have to iterate the GPU, starting at 0 to get them all Okay I've combined the two, perhaps this will work for most of us: #!/bin/bash
# Miner restart script V002
# By Maxximus007 && IAmNotAJeep
# for nvOC by fullzero
#
#########################
### BELOW CODE, NO NEED FOR EDITING
#########################
echo "$(date) - Starting miner restart script." | tee -a ${LOG_FILE}
# Creating a log file to record restarts
LOG_FILE="/home/m1/restartlog.txt"
if [ ! -e "$LOG_FILE" ] ; then
touch "$LOG_FILE"
fi
MIN_UTIL=90
RESTART=0
while true
do
sleep 60
GPUS=$(nvidia-smi --query-gpu=count --format=csv,noheader,nounits | tail -1)
gpu=0
COUNT=0
while [ $gpu -lt $GPUS ]
do
{ IFS=', ' read UTIL; } < <( nvidia-smi -i $gpu --query-gpu=utilization.gpu --format=csv,noheader,nounits)
let UTILIZATION=$( printf "%.0f" $UTIL )
# If current utilizations lower than the limit count them:
if [ $UTILIZATION -lt $MIN_UTIL ]
then
let COUNT=COUNT+1
fi
let gpu=gpu+1
done
if [ $COUNT -eq $GPUS ]
then
if [ $RESTART -gt 1 ]
then
echo "$(date) - Utilization is too low: reviving did not work so restarting system" | tee -a ${LOG_FILE}
sudo shutdown now -r
fi
echo "$(date) - Utilization is too low: kill miner and oneBash" | tee -a ${LOG_FILE}
# If miner runs in screen 'miner' kill the screen
screen -X -S miner kill
# Best to restart oneBash - settings might be adjusted already
kill ps -ef | awk '$NF~"oneBash" {print $2}'
let RESTART=RESTART+1
else
echo "$(date) - All good! Will check again in 60 seconds"
fi
done
|
|
|
|
|
|
salfter
|
|
July 10, 2017, 06:16:09 PM |
|
I've done some testing with shell scripts that shows a way forward: stop the previous miner, stop X, unload the nVidia driver, reload the driver, restart X, and start the next miner. This puts the GPUs back to a known-good state before getting back to mining. I've switched back and forth between a known-troublesome pair of miners, and it hasn't failed yet. I'm going to put these changes into the switcher next and see how it goes.
This part seems to be working well, but now I'm running into a problem where ccminer (used by several algos) doesn't want to start within a screen session. It works fine if started at the command line by itself. It works fine inside an already-running screen session. It falls on its face when the invocation is preceded by "screen -dmS miner": /home/m1/SPccminer/ccminer: error while loading shared libraries: libcudart.so.8.0: cannot open shared object file: No such file or directorylibcudart.so.8.0 is in /usr/local/cuda-8.0/lib64. There appears to be something different in the environment when screen is starting up vs. the rest of the time. Here's a quick hack which fixes it, but I suspect this really shouldn't be necessary: sudo ln -s /usr/local/cuda-8.0/lib64/libcudart.so.8.0 /usr/lib/ With this fix in place, most miners respond well to the switch...except the Pascal miner. It takes its time responding to SIGTERM, and there's a higher likelihood of a GPU still falling off the bus, locking up, or whatever, necessitating a reboot. Given that it's moving well into negative territory WRT profitability anyway (currently -$0.23 on my rig), I might just disable it and continue testing with the other miners. |
|
|
|
IAmNotAJeep
Newbie
Offline
Activity: 44
Merit: 0
|
|
July 10, 2017, 06:32:34 PM |
|
Hey fullzero, i have a question,
without a doubt my biggest problem right now is that when my miner crashes it takes the whole rig down with it, everything gets stuck, SSH barely works, average system load jumps to 14.5!! and Xorg takes up 100% of the CPU, its so bad that none of the standard reboot commands work, they just do nothing, the only thing that actually reboots the rig in this state is "echo b > /proc/sysrq-trigger" so i've set up a script that checks the average system load and if its over 2 it uses the command to reboot, and it works, but i dont like this "solution", yesterday after a reboot nvOC got corrupted somehow, lost my customized oneBash and the whole system became read-only (thankfully i had a oneBash backup that was only a few days behind).
so the question is, what can i do to relive this Xorg error, i run a 7 card rig and never plan on going for a higher number, what can i do with Xorg that would fix this?
Thanks.
@ tempgoga It seems that whenever a soft crash occurs most of the cards drop to zero, so while the display/keyboard is unresponsive you can catch the soft crash from nvidia-smi. The script below checks card utilization, if it drops below 90% it counts down a minute and if mining hasn't resumed it reboots the system. This seems to have worked at least once in my case (only got one soft crash this weekend) and the system recovered as expected. the threshold values work for my setup but others may find different values optimal Also if anyone knows a way to iterate the if && statements we can get the card count from "cards=$(nvidia-smi -L | wc -l); echo $cards" but the way below also works with manual editing to adjust the watchdog for the number of cards in you individual system. ___________ #!/bin/bash #m1 threshold=90 while sleep 5 do number=$(nvidia-smi |grep % |awk '{print $13}' |tr -d %) set -- $number echo -e "$@" # The "if and" statements below need to be manually adjusted to match the number of cards in your system # If you have 5 cards, leave is as, if a different number of cards remove or add the && statements as needed as in the example below if [[ "$1" -gt "$threshold" ]] && \ [[ "$2" -gt "$threshold" ]] && \ [[ "$3" -gt "$threshold" ]] && \ [[ "$4" -gt "$threshold" ]] && \ [[ "$5" -gt "$threshold" ]] # && \ # [[ "$6" -gt "$threshold" ]] then i=12 echo OK else echo $((i--)) fi if [ $i -le 0 ] then echo $(date) REBOOT due to soft crash >>~/watchdog.log sleep -5 sudo shutdown now -r fi done ___________ Hey thats funny I just made a script doing something similar, although it checks the powerdraw. Here it is: #!/bin/bash
# Miner restart script V001
# By Maxximus007
# for nvOC by fullzero
#
# POWERLIMIT MUST BE SET IN oneBash
#########################
### BELOW CODE, NO NEED FOR EDITING
#########################
echo "$(date) - Starting miner restart script." | tee -a ${LOG_FILE}
# Creating a log file to record restarts
LOG_FILE="/home/m1/restartlog.txt"
if [ ! -e "$LOG_FILE" ] ; then
touch "$LOG_FILE"
fi
while true
do
sleep 60
GPUS=$(nvidia-smi --query-gpu=count --format=csv,noheader,nounits | tail -1)
gpu=0
COUNT_LOW_POWER=0
while [ $gpu -lt $GPUS ]
do
{ IFS=', ' read POWERDRAW POWERLIMIT; } < <( nvidia-smi -i $gpu --query-gpu=power.draw,power.limit --format=csv,noheader,nounits)
let POWER_DIFF=$( printf "%.0f" $POWERLIMIT )-$( printf "%.0f" $POWERDRAW )
# If current draw is 30 Watt lower than the limit count them:
if [ "$POWER_DIFF" -gt "30" ]
then
let COUNT_LOW_POWER=COUNT_LOW_POWER+1
fi
let gpu=gpu+1
done
if [ $COUNT_LOW_POWER -eq $GPUS ]
then
echo "$(date) - Power draw is too low: kill miner and oneBash" | tee -a ${LOG_FILE}
# If miner runs in screen 'miner' kill the screen
screen -X -S miner kill
# Best to restart oneBash - settings might be adjusted already
kill ps -ef | awk '$NF~"oneBash" {print $2}'
else
echo "$(date) - All good! Will check again in 60 seconds"
fi
done
You can combine the above with your code, and find the utilization like this: nvidia-smi -i 1 --query-gpu=utilization.gpu --format=csv,noheader,nounits You have to iterate the GPU, starting at 0 to get them all Okay I've combined the two, perhaps this will work for most of us: #!/bin/bash
# Miner restart script V002
# By Maxximus007 && IAmNotAJeep
# for nvOC by fullzero
#
#########################
### BELOW CODE, NO NEED FOR EDITING
#########################
echo "$(date) - Starting miner restart script." | tee -a ${LOG_FILE}
# Creating a log file to record restarts
LOG_FILE="/home/m1/restartlog.txt"
if [ ! -e "$LOG_FILE" ] ; then
touch "$LOG_FILE"
fi
MIN_UTIL=90
RESTART=0
while true
do
sleep 60
GPUS=$(nvidia-smi --query-gpu=count --format=csv,noheader,nounits | tail -1)
gpu=0
COUNT=0
while [ $gpu -lt $GPUS ]
do
{ IFS=', ' read UTIL; } < <( nvidia-smi -i $gpu --query-gpu=utilization.gpu --format=csv,noheader,nounits)
let UTILIZATION=$( printf "%.0f" $UTIL )
# If current utilizations lower than the limit count them:
if [ $UTILIZATION -lt $MIN_UTIL ]
then
let COUNT=COUNT+1
fi
let gpu=gpu+1
done
if [ $COUNT -eq $GPUS ]
then
if [ $RESTART -gt 1 ]
then
echo "$(date) - Utilization is too low: reviving did not work so restarting system" | tee -a ${LOG_FILE}
sudo shutdown now -r
fi
echo "$(date) - Utilization is too low: kill miner and oneBash" | tee -a ${LOG_FILE}
# If miner runs in screen 'miner' kill the screen
screen -X -S miner kill
# Best to restart oneBash - settings might be adjusted already
kill ps -ef | awk '$NF~"oneBash" {print $2}'
let RESTART=RESTART+1
else
echo "$(date) - All good! Will check again in 60 seconds"
fi
done
Pretty cool! I'll try it tonight, lets hope this put the softcrash issues behind us. |
|
|
|
|
|


