Master89
Newbie

 Offline Offline
Activity: 5
Merit: 0

|
 |
July 11, 2017, 08:41:06 AM |
|
ubuntu server 16.4
driver nvidia_381
does not work
X server nvidia-settings
sudo nvidia-settings
Failed to connect to Mir: Failed to connect to server socket
Unable to init server: Could not connect
ERROR: The control display is undefined; please run `nvidia-settings --help`
for usage information.
Reinstall does not help
Is this with nvOC or vanilla Ubuntu? Server ubuntu 16.4 without add-ons Clean OS |
|
|
|
|
TheHypnoToad
Newbie
Offline
Activity: 31
Merit: 0
|
|
July 11, 2017, 09:42:25 AM |
|
Hello this looks good, I'm looking to do away with Windows on my machine as it's being more of a hinderence than a help.
Quick question about running Linux from a USB, is the stick being mounted as read-only in a similar way to a LiveUSB drive?
I've heard this is a good idea as USB drives are often fast to read but slow to write. thanks
|
|
|
|
|
damNmad
Full Member
Offline
Activity: 378
Merit: 104
nvOC forever
|
|
July 11, 2017, 10:57:08 AM |
|
1First configure this section of oneBash: SALFTER_NICEHASH_PROFIT_SWITCHING="YES"
# LOCAL will attach the mining process to the guake terminal
# REMOTE will leave it unattached / ready for SSH
LOCALorREMOTE="LOCAL" # LOCAL or REMOTE
CURRENCY=USD
POWER_COST=0.10
MINIMUM_PROFIT=0.0
# this is salfters BTC address:
PAYMENT_ADDRESS=1TipsGocnz2N5qgAm9f7JLrsMqkb3oXe2
WORKER_NAME=nv$IP_AS_WORKER
daggerhashimoto_POWERLIMIT_WATTS=125
__daggerhashimoto_CORE_OVERCLOCK=100
daggerhashimoto_MEMORY_OVERCLOCK=100
_______daggerhashimoto_FAN_SPEED=75
equihash_POWERLIMIT_WATTS=125
__equihash_CORE_OVERCLOCK=100
equihash_MEMORY_OVERCLOCK=100
_______equihash_FAN_SPEED=75
neoscrypt_POWERLIMIT_WATTS=125
__neoscrypt_CORE_OVERCLOCK=100
neoscrypt_MEMORY_OVERCLOCK=100
_______neoscrypt_FAN_SPEED=75
lyra2rev2_POWERLIMIT_WATTS=125
__lyra2rev2_CORE_OVERCLOCK=100
lyra2rev2_MEMORY_OVERCLOCK=100
_______lyra2rev2_FAN_SPEED=75
lbry_POWERLIMIT_WATTS=125
__lbry_CORE_OVERCLOCK=100
lbry_MEMORY_OVERCLOCK=100
_______lbry_FAN_SPEED=75
pascal_POWERLIMIT_WATTS=125
__pascal_CORE_OVERCLOCK=100
pascal_MEMORY_OVERCLOCK=100
_______pascal_FAN_SPEED=75 ensure: SALFTER_NICEHASH_PROFIT_SWITCHING="YES" and replace salfters BTC address with your own: PAYMENT_ADDRESS=1TipsGocnz2N5qgAm9f7JLrsMqkb3oXe2 salfter implemented this for nicehash only. It makes a call to a nicehash api and receives the current profitability data. Using your input power cost (and what I am guessing are salfters benchmarks for each algo using 2x 1070s) it calculates which coin is currently the most profitable to mine. It then stops any mining process, and starts a new one with the most profitable coin and your OC settings for that coin. ================================================================================ SALFTER_NICEHASH_PROFIT_SWITCHING="YES"
# LOCAL will attach the mining process to the guake terminal
# REMOTE will leave it unattached / ready for SSH
LOCALorREMOTE="LOCAL" # LOCAL or REMOTE
CURRENCY=USD
POWER_COST=0.20
MINIMUM_PROFIT=2.5
# this is salfters BTC address:
PAYMENT_ADDRESS=1QJ6j3fY6fCRsN1WJqZ65U52Et4TVL9e7P
WORKER_NAME=$IP_AS_WORKER
daggerhashimoto_POWERLIMIT_WATTS=95
__daggerhashimoto_CORE_OVERCLOCK=150
daggerhashimoto_MEMORY_OVERCLOCK=1200
_______daggerhashimoto_FAN_SPEED=65
equihash_POWERLIMIT_WATTS=95
__equihash_CORE_OVERCLOCK=150
equihash_MEMORY_OVERCLOCK=1200
_______equihash_FAN_SPEED=65
neoscrypt_POWERLIMIT_WATTS=95
__neoscrypt_CORE_OVERCLOCK=150
neoscrypt_MEMORY_OVERCLOCK=1200
_______neoscrypt_FAN_SPEED=65
lyra2rev2_POWERLIMIT_WATTS=95
__lyra2rev2_CORE_OVERCLOCK=150
lyra2rev2_MEMORY_OVERCLOCK=1200
_______lyra2rev2_FAN_SPEED=65
lbry_POWERLIMIT_WATTS=95
__lbry_CORE_OVERCLOCK=150
lbry_MEMORY_OVERCLOCK=1200
_______lbry_FAN_SPEED=65
pascal_POWERLIMIT_WATTS=95
__pascal_CORE_OVERCLOCK=150
pascal_MEMORY_OVERCLOCK=1200
_______pascal_FAN_SPEED=65 I've done the above, mining hasn't started (have i missed to copy/include anything?), I'm using v0017 as is (My Mob is Asus Z270P with 8 GTX 6G 1060's) Saw this as output : m1@m1-desktop:~$ screen -r miner
There is no screen to be resumed matching miner.
m1@m1-desktop:~$ screen -r miner
There is no screen to be resumed matching miner.
m1@m1-desktop:~$
================================================================================ Set:
MINIMUM_PROFIT=0
and tell me if there is a difference.2You can use the SALFTER_NICEHASH_PROFIT_SWITCHING, or you can use the: COIN selection I still need to add all the other nicehash algos as normal COIN selections. Nicehash does use a BTC payout address, when using the NICE_ETHASH COIN selection set this in this area of the oneBash settings: # if YES ensure you update BTC_ADDRESS
VTC_AUTOCONVERT_TO_BTC="YES" #YES NO
VTC_WORKER="nv$IP_AS_WORKER"
VTC_ADDRESS="VsvtYL2mz3YFM3fpt5pb28zHodTbnJodRc"
VTC_POOL="stratum+tcp://lyra2v2.mine.zpool.ca:4533"
BTC_ADDRESS="18Y5HYe3BAwAhTAkFLbD52o8NqtrN3DtpF"
# NICE_ETHASH autoconverts to BTC: ensure you update BTC_ADDRESS if you use NICE_ETHASH
NICE_ETHASH_WORKER="nv$IP_AS_WORKER"
NICE_ETHASH_POOL="stratum+tcp://daggerhashimoto.usa.nicehash.com:3353"
GENOIL_NICE_ETHASH_POOL="daggerhashimoto.usa.nicehash.com:3353"
NICE_ETHASH_EXTENTION_ARGUMENTS="" # add any additional claymore arguments desired here this line: BTC_ADDRESS="18Y5HYe3BAwAhTAkFLbD52o8NqtrN3DtpF" ================================================================================ I've added my BTC address, if I run the oneBash with 'NICE_ETHASH' coin selection, which coin does it mines? (I know you said there is no coin selection/algos currently, just curious to know what it selects and mine) No matter what it mines, will it just coverts into BTC and pay to my BTC address? I've tried it using my BTC address for a while, it has started mining but not sure what it was mining (it was using Genoil)!, but saw ETH share accepted message most of the times ("stratum+tcp://daggerhashimoto.usa.nicehash.com:3353") Also where can I check how many shares per our stats related to my BTC address or Miner while mining with 'NICE_ETHASH' ================================================================================ It is mining whatever nicehash thinks is the most profitible Ethash Coin at the time.
It will payout in BTC to the
BTC_ADDRESS
assuming:
1QJ6j3fY6fCRsN1WJqZ65U52Et4TVL9e7P
is your BTC address
you would go to:
https://new.nicehash.com/miner/1QJ6j3fY6fCRsN1WJqZ65U52Et4TVL9e7P
to see your nicehash stats3at the top of oneBash ensure COIN is set to: then set your ETH settings here: ETHERMINEdotORG="NO"
CLAYMORE_VERSION="9_5" # choose 9_5 or 9_4 or 8_0
GENOILorCLAYMORE="GENOIL" # choose GENOIL or CLAYMORE
ETH_WORKER="nv$IP_AS_WORKER"
ETH_ADDRESS="0xe12bdd454997e443ec0cae6bebb6bb3c74242aae"
ETH_POOL="eth-us-east1.nanopool.org:9999"
ETH_EXTENTION_ARGUMENTS="" # add any additional claymore arguments desired here then set your DCR settings here: DCR_WORKER="nv$IP_AS_WORKER"
DCR_ADDRESS="fullzero22"
DCR_POOL="stratum+tcp://dcr.suprnova.cc:3252" Note that with supernova you need to set the workername beforehand, so I recommend changing the workername to whatever you have set already rather than making a new worker with the auto generated workername. replace: DCR_ADDRESS="fullzero22" with your supernova username Let me know if all this makes sense. ================================================================================ Yes it does makes sense, some of it, now I'm able to mine DCR with suprnova, using Claymore 9_7, Thanks for that Amigo  But I still have some questions regarding NICE HASH mining, can we mine any coin with nicehash pools? How can we check share rate while using nicehash pools (daggerhashimoto ?)? I may still need some help to understand my 2nd question, will try to google and find some info, Thank you so much for the replies mate, that really means a lot to people like me, wish I could give something back to community like you are doing ================================================================================ Answer to 3 is in the response to 2. ================================================================================ Now it all make sense, lots of questions got answered from your replies. I really appreciate you for the time and effort. & for the first question SALFTER_NICEHASH_PROFIT_SWITCHING="YES"
# LOCAL will attach the mining process to the guake terminal
# REMOTE will leave it unattached / ready for SSH
LOCALorREMOTE="LOCAL" # LOCAL or REMOTE
CURRENCY=USD
POWER_COST=0.20
MINIMUM_PROFIT=0
# this is salfters BTC address:
PAYMENT_ADDRESS=1QJ6j3fY6fCRsN1WJqZ65U52Et4TVL9e7P
WORKER_NAME=$IP_AS_WORKER
daggerhashimoto_POWERLIMIT_WATTS=95
__daggerhashimoto_CORE_OVERCLOCK=150
daggerhashimoto_MEMORY_OVERCLOCK=1200
_______daggerhashimoto_FAN_SPEED=65
equihash_POWERLIMIT_WATTS=95
__equihash_CORE_OVERCLOCK=150
equihash_MEMORY_OVERCLOCK=1200
_______equihash_FAN_SPEED=65
neoscrypt_POWERLIMIT_WATTS=95
__neoscrypt_CORE_OVERCLOCK=150
neoscrypt_MEMORY_OVERCLOCK=1200
_______neoscrypt_FAN_SPEED=65
lyra2rev2_POWERLIMIT_WATTS=95
__lyra2rev2_CORE_OVERCLOCK=150
lyra2rev2_MEMORY_OVERCLOCK=1200
_______lyra2rev2_FAN_SPEED=65
lbry_POWERLIMIT_WATTS=95
__lbry_CORE_OVERCLOCK=150
lbry_MEMORY_OVERCLOCK=1200
_______lbry_FAN_SPEED=65
pascal_POWERLIMIT_WATTS=95
__pascal_CORE_OVERCLOCK=150
pascal_MEMORY_OVERCLOCK=1200
_______pascal_FAN_SPEED=65 Even after changing the profit to '0', still getting the following. m1@m1-desktop:~$ screen -r miner
There is no screen to be resumed matching miner.
m1@m1-desktop:~$ screen -r miner
There is no screen to be resumed matching miner.
m1@m1-desktop:~$
* Do i need to connect(turn on) monitor to do so? (I do have monitor connected to Main GPU, but always remove power once RIG is UP and Running) * What coin I need to select on top while having SALFTER_NICEHASH_PROFIT_SWITCHING="YES"? (NICE_ETHASH??) |
|
|
|
IAmNotAJeep
Newbie
Offline
Activity: 44
Merit: 0
|
|
July 11, 2017, 12:00:58 PM
Last edit: July 11, 2017, 12:57:21 PM by IAmNotAJeep |
|
Hey fullzero, i have a question,
without a doubt my biggest problem right now is that when my miner crashes it takes the whole rig down with it, everything gets stuck, SSH barely works, average system load jumps to 14.5!! and Xorg takes up 100% of the CPU, its so bad that none of the standard reboot commands work, they just do nothing, the only thing that actually reboots the rig in this state is "echo b > /proc/sysrq-trigger" so i've set up a script that checks the average system load and if its over 2 it uses the command to reboot, and it works, but i dont like this "solution", yesterday after a reboot nvOC got corrupted somehow, lost my customized oneBash and the whole system became read-only (thankfully i had a oneBash backup that was only a few days behind).
so the question is, what can i do to relive this Xorg error, i run a 7 card rig and never plan on going for a higher number, what can i do with Xorg that would fix this?
Thanks.
@ tempgoga It seems that whenever a soft crash occurs most of the cards drop to zero, so while the display/keyboard is unresponsive you can catch the soft crash from nvidia-smi. The script below checks card utilization, if it drops below 90% it counts down a minute and if mining hasn't resumed it reboots the system. This seems to have worked at least once in my case (only got one soft crash this weekend) and the system recovered as expected. the threshold values work for my setup but others may find different values optimal Also if anyone knows a way to iterate the if && statements we can get the card count from "cards=$(nvidia-smi -L | wc -l); echo $cards" but the way below also works with manual editing to adjust the watchdog for the number of cards in you individual system. ___________ #!/bin/bash #m1 threshold=90 while sleep 5 do number=$(nvidia-smi |grep % |awk '{print $13}' |tr -d %) set -- $number echo -e "$@" # The "if and" statements below need to be manually adjusted to match the number of cards in your system # If you have 5 cards, leave is as, if a different number of cards remove or add the && statements as needed as in the example below if [[ "$1" -gt "$threshold" ]] && \ [[ "$2" -gt "$threshold" ]] && \ [[ "$3" -gt "$threshold" ]] && \ [[ "$4" -gt "$threshold" ]] && \ [[ "$5" -gt "$threshold" ]] # && \ # [[ "$6" -gt "$threshold" ]] then i=12 echo OK else echo $((i--)) fi if [ $i -le 0 ] then echo $(date) REBOOT due to soft crash >>~/watchdog.log sleep -5 sudo shutdown now -r fi done ___________ Hey thats funny I just made a script doing something similar, although it checks the powerdraw. Here it is: #!/bin/bash
# Miner restart script V001
# By Maxximus007
# for nvOC by fullzero
#
# POWERLIMIT MUST BE SET IN oneBash
#########################
### BELOW CODE, NO NEED FOR EDITING
#########################
echo "$(date) - Starting miner restart script." | tee -a ${LOG_FILE}
# Creating a log file to record restarts
LOG_FILE="/home/m1/restartlog.txt"
if [ ! -e "$LOG_FILE" ] ; then
touch "$LOG_FILE"
fi
while true
do
sleep 60
GPUS=$(nvidia-smi --query-gpu=count --format=csv,noheader,nounits | tail -1)
gpu=0
COUNT_LOW_POWER=0
while [ $gpu -lt $GPUS ]
do
{ IFS=', ' read POWERDRAW POWERLIMIT; } < <( nvidia-smi -i $gpu --query-gpu=power.draw,power.limit --format=csv,noheader,nounits)
let POWER_DIFF=$( printf "%.0f" $POWERLIMIT )-$( printf "%.0f" $POWERDRAW )
# If current draw is 30 Watt lower than the limit count them:
if [ "$POWER_DIFF" -gt "30" ]
then
let COUNT_LOW_POWER=COUNT_LOW_POWER+1
fi
let gpu=gpu+1
done
if [ $COUNT_LOW_POWER -eq $GPUS ]
then
echo "$(date) - Power draw is too low: kill miner and oneBash" | tee -a ${LOG_FILE}
# If miner runs in screen 'miner' kill the screen
screen -X -S miner kill
# Best to restart oneBash - settings might be adjusted already
kill ps -ef | awk '$NF~"oneBash" {print $2}'
else
echo "$(date) - All good! Will check again in 60 seconds"
fi
done
You can combine the above with your code, and find the utilization like this: nvidia-smi -i 1 --query-gpu=utilization.gpu --format=csv,noheader,nounits You have to iterate the GPU, starting at 0 to get them all Okay I've combined the two, perhaps this will work for most of us: #!/bin/bash
# Miner restart script V002
# By Maxximus007 && IAmNotAJeep
# for nvOC by fullzero
#
#########################
### BELOW CODE, NO NEED FOR EDITING
#########################
echo "$(date) - Starting miner restart script." | tee -a ${LOG_FILE}
# Creating a log file to record restarts
LOG_FILE="/home/m1/restartlog.txt"
if [ ! -e "$LOG_FILE" ] ; then
touch "$LOG_FILE"
fi
MIN_UTIL=90
RESTART=0
while true
do
sleep 60
GPUS=$(nvidia-smi --query-gpu=count --format=csv,noheader,nounits | tail -1)
gpu=0
COUNT=0
while [ $gpu -lt $GPUS ]
do
{ IFS=', ' read UTIL; } < <( nvidia-smi -i $gpu --query-gpu=utilization.gpu --format=csv,noheader,nounits)
let UTILIZATION=$( printf "%.0f" $UTIL )
# If current utilizations lower than the limit count them:
if [ $UTILIZATION -lt $MIN_UTIL ]
then
let COUNT=COUNT+1
fi
let gpu=gpu+1
done
if [ $COUNT -eq $GPUS ]
then
if [ $RESTART -gt 1 ]
then
echo "$(date) - Utilization is too low: reviving did not work so restarting system" | tee -a ${LOG_FILE}
sudo shutdown now -r
fi
echo "$(date) - Utilization is too low: kill miner and oneBash" | tee -a ${LOG_FILE}
# If miner runs in screen 'miner' kill the screen
screen -X -S miner kill
# Best to restart oneBash - settings might be adjusted already
kill ps -ef | awk '$NF~"oneBash" {print $2}'
let RESTART=RESTART+1
else
echo "$(date) - All good! Will check again in 60 seconds"
fi
done
Pretty cool! I'll try it tonight, lets hope this put the softcrash issues behind us. I will try this out as well; good work. @ Maxximus007 Thanks for putting these together, great collab! I'm not a bash expert, so maybe I'm reading this wrong, but here are some thoughts. The combined code seems to be evaluating each gpu individually for the fault condition to be met, which means if one fails and you have say 5 other cards working then it keeps going until all the cards give reduced output since all of them have to fail individually to increment the counter?So if 5/6 fail we keep going? (Again just looking at it and tracing it in my head so maybe I'm reading wrong). The way I was thinking about it, is that I wanted all the cards to work at above 90% efficiency and reboot as soon as any card strays beyond the threshold - this is why I did the "if and" statement and didn't iterate though "if" statements alone (I didn't know how to iterate "if and" based on an unknown number of cards lol). I had a version giving 6xOK and such but I think it's more efficient to just get 1xOK if ALL meet the 90% criteria and start the countdown as soon as anything is out of norm - and if the miner recovers, flush the counter. I observed a number of these conditions with Claymore where it recovers half the time, but then eventually craps out and the script kicks in. I haven't seen it on my Genoil rig yet since my other script has kept it in check without any softcrash for day 3 now. A thought about the power draw as threshold measure - it is power limit/card specific and I guess people would need to tune their power threshold to their power limit so I agree it's best to use gpu util. (My cards are at 82W limit for example). Thoughts? The code checks each cards individually, at times (with Claymore, not Genoil) I've seen that Util (or Powerpraw) is dropping, maybe even below 90 for a few seconds. In order not to generate too much restarts I check all cards. We can lower this or make it so that each of us can decide when it should reboot. I've combined the restart/reboot so that the first attempt is to restart miner. If that doesn't work, we reboot the machine. We might want to reset the reboot counter after a while, so we don't loose time with a full reboot. In the first code I checked Powerdraw -> if 30 Watt less than Powerlimit there might be something wrong. Idling cards use around 10 Watt, so that works for all I think. We can combine this with Util if that helps. So sure we can make it more advanced, we just have to determine the right parameters. Hope others can let us know in what circumstances they see hanging miners. Just one card, or more or everything? Is Util back to zero? or hanging on to 100%? OK thanks for the clarification, it's really neat and rewarding to see different approaches to this problem  Here is why I coded to test that all the cards meet the threshold as one with "if &&": as an example I'll use an event from from my test rig overnight: one card dropped, the "if &&" script waited for claymore to recover for one minute, then booted the system and that was that. Total down time, 2 mins, if you add the 1 minute of reduced capacity waiting for the miner to right itself, 3 minutes impact. The "if &&" code does tests for a graceful miner recovery - by continuing to test the cards for above threshold utilization for 60 seconds after it detects a fault. If the miner recovers, but just sits there (saw both Claymore/Genoil do exactly that a number of times) that's not good enough and the system gets a boot. My other miner restart script did not handle this exact case and once every few days I would find the miner sitting pretty and blowing bubbles mining on one or two cards until I noticed because it did not "see" all the cards anymore but it did see some so it thought it "recovered". If the miner recovers properly, all cards need to hit above threshold and we can flush the counter and life goes on. On my test rig, graceful miner recovery occurred 5-6 times in the past 24 hours without prompting a restart - which is desirable above either running at reduced capacity or 5-6 reboots (IMHO). In contrast - if we test each card independently and increment the error counter one by one until it reaches the number of GPU's, then - depending on the number of cards in the system it could take a long time for all of them to fail - the more cards, the more time to fail (right? am I misunderstanding anything?) So the same event, would unfold differently: the test rig would continue at reduced capacity until COUNT reaches # of GPU's - but since it resets at next check, we can hobble on 5,4,3,2, 1 card until they all die or and the script kicks in or we freeze and require a manual intervention. This could be hours of impact (again if I'm reading this wrong, my apologies, but this is what I'm getting out of looking at it.) So IMHO, by testing that all the cards meet the 90% utilization threshold (as one, all or nothing = if &&), we avoid hours of impact/decreased capacity. My other concern is that as soon as cards start dropping off one at a time the system gets unstable, increasing the risk of a hang or corrupted file system due to a hard crash. My view is that it should be cycled at maximum stability for a graceful restart. Maybe there is a third approach not considered yet, Thoughts? ... edit: Actually one more thought - I did not test for this yet so I don't know the answer - but in the case where the miner does not see all the cards anymore, does this mean that nvidia-smi ALSO does not see all the cards anymore? If so, and if we get the number of cards from nvidia-smi, wouldn't the script assume that the rig has the right number of cards every time that nvidia-smi stop seeing one? I do recall cards disappearing even from nvidia-smi but I never kept track of this so I don't know how often this condition actually occurs. |
|
|
|
|
|
VoskCoin
|
|
July 11, 2017, 01:36:18 PM |
|
Is it possible to run nicehash equihash algo in this version ? If so how exactly do I implement it?
Also with all things the same my miners are performing a hundred sols faster going from 15 to 17 futhermore @fullzero as you suggested this software did fix my failed fan setting issue, at least so far and I did not activate the slow USB command as these Lexar seem to be fast USB!
|
|
|
|
|
VoskCoin
|
|
July 11, 2017, 02:06:03 PM |
|
I tried mining zec on slushpool, nice site, getting the workers to populate correctly with nvOC was frustrating, and the returns are not as high or consistent than other pools. However I did earn .33 zec when I normally earn .18 zec on their pool with 6.5k sols
What pools are you all using to mine ZEC currently
|
|
|
|
mattblack
Newbie
Offline
Activity: 2
Merit: 0
|
|
July 11, 2017, 04:39:15 PM |
|
Hi guys,
Using nvOC with latest updates. Great work! I like Salfter nicehash profit switch but i'm getting errors after 10-15 mins which locks the miner.
CUDA error in func 'search'at line 346: an illegal memory access was encountered.
How can i solve that?
|
|
|
|
|
|
Maxximus007
|
|
July 11, 2017, 05:28:37 PM |
|
Hi guys,
Using nvOC with latest updates. Great work! I like Salfter nicehash profit switch but i'm getting errors after 10-15 mins which locks the miner.
CUDA error in func 'search'at line 346: an illegal memory access was encountered.
How can i solve that?
This does sounds like too much OC. Try with lower clocks to see if it resolves itself. |
|
|
|
|
|
Maxximus007
|
|
July 11, 2017, 05:48:23 PM |
|
Hey fullzero, i have a question,
without a doubt my biggest problem right now is that when my miner crashes it takes the whole rig down with it, everything gets stuck, SSH barely works, average system load jumps to 14.5!! and Xorg takes up 100% of the CPU, its so bad that none of the standard reboot commands work, they just do nothing, the only thing that actually reboots the rig in this state is "echo b > /proc/sysrq-trigger" so i've set up a script that checks the average system load and if its over 2 it uses the command to reboot, and it works, but i dont like this "solution", yesterday after a reboot nvOC got corrupted somehow, lost my customized oneBash and the whole system became read-only (thankfully i had a oneBash backup that was only a few days behind).
so the question is, what can i do to relive this Xorg error, i run a 7 card rig and never plan on going for a higher number, what can i do with Xorg that would fix this?
Thanks.
@ tempgoga It seems that whenever a soft crash occurs most of the cards drop to zero, so while the display/keyboard is unresponsive you can catch the soft crash from nvidia-smi. The script below checks card utilization, if it drops below 90% it counts down a minute and if mining hasn't resumed it reboots the system. This seems to have worked at least once in my case (only got one soft crash this weekend) and the system recovered as expected. the threshold values work for my setup but others may find different values optimal Also if anyone knows a way to iterate the if && statements we can get the card count from "cards=$(nvidia-smi -L | wc -l); echo $cards" but the way below also works with manual editing to adjust the watchdog for the number of cards in you individual system. ___________ #!/bin/bash #m1 threshold=90 while sleep 5 do number=$(nvidia-smi |grep % |awk '{print $13}' |tr -d %) set -- $number echo -e "$@" # The "if and" statements below need to be manually adjusted to match the number of cards in your system # If you have 5 cards, leave is as, if a different number of cards remove or add the && statements as needed as in the example below if [[ "$1" -gt "$threshold" ]] && \ [[ "$2" -gt "$threshold" ]] && \ [[ "$3" -gt "$threshold" ]] && \ [[ "$4" -gt "$threshold" ]] && \ [[ "$5" -gt "$threshold" ]] # && \ # [[ "$6" -gt "$threshold" ]] then i=12 echo OK else echo $((i--)) fi if [ $i -le 0 ] then echo $(date) REBOOT due to soft crash >>~/watchdog.log sleep -5 sudo shutdown now -r fi done ___________ Hey thats funny I just made a script doing something similar, although it checks the powerdraw. Here it is: #!/bin/bash
# Miner restart script V001
# By Maxximus007
# for nvOC by fullzero
#
# POWERLIMIT MUST BE SET IN oneBash
#########################
### BELOW CODE, NO NEED FOR EDITING
#########################
echo "$(date) - Starting miner restart script." | tee -a ${LOG_FILE}
# Creating a log file to record restarts
LOG_FILE="/home/m1/restartlog.txt"
if [ ! -e "$LOG_FILE" ] ; then
touch "$LOG_FILE"
fi
while true
do
sleep 60
GPUS=$(nvidia-smi --query-gpu=count --format=csv,noheader,nounits | tail -1)
gpu=0
COUNT_LOW_POWER=0
while [ $gpu -lt $GPUS ]
do
{ IFS=', ' read POWERDRAW POWERLIMIT; } < <( nvidia-smi -i $gpu --query-gpu=power.draw,power.limit --format=csv,noheader,nounits)
let POWER_DIFF=$( printf "%.0f" $POWERLIMIT )-$( printf "%.0f" $POWERDRAW )
# If current draw is 30 Watt lower than the limit count them:
if [ "$POWER_DIFF" -gt "30" ]
then
let COUNT_LOW_POWER=COUNT_LOW_POWER+1
fi
let gpu=gpu+1
done
if [ $COUNT_LOW_POWER -eq $GPUS ]
then
echo "$(date) - Power draw is too low: kill miner and oneBash" | tee -a ${LOG_FILE}
# If miner runs in screen 'miner' kill the screen
screen -X -S miner kill
# Best to restart oneBash - settings might be adjusted already
kill ps -ef | awk '$NF~"oneBash" {print $2}'
else
echo "$(date) - All good! Will check again in 60 seconds"
fi
done
You can combine the above with your code, and find the utilization like this: nvidia-smi -i 1 --query-gpu=utilization.gpu --format=csv,noheader,nounits You have to iterate the GPU, starting at 0 to get them all Okay I've combined the two, perhaps this will work for most of us: #!/bin/bash
# Miner restart script V002
# By Maxximus007 && IAmNotAJeep
# for nvOC by fullzero
#
#########################
### BELOW CODE, NO NEED FOR EDITING
#########################
echo "$(date) - Starting miner restart script." | tee -a ${LOG_FILE}
# Creating a log file to record restarts
LOG_FILE="/home/m1/restartlog.txt"
if [ ! -e "$LOG_FILE" ] ; then
touch "$LOG_FILE"
fi
MIN_UTIL=90
RESTART=0
while true
do
sleep 60
GPUS=$(nvidia-smi --query-gpu=count --format=csv,noheader,nounits | tail -1)
gpu=0
COUNT=0
while [ $gpu -lt $GPUS ]
do
{ IFS=', ' read UTIL; } < <( nvidia-smi -i $gpu --query-gpu=utilization.gpu --format=csv,noheader,nounits)
let UTILIZATION=$( printf "%.0f" $UTIL )
# If current utilizations lower than the limit count them:
if [ $UTILIZATION -lt $MIN_UTIL ]
then
let COUNT=COUNT+1
fi
let gpu=gpu+1
done
if [ $COUNT -eq $GPUS ]
then
if [ $RESTART -gt 1 ]
then
echo "$(date) - Utilization is too low: reviving did not work so restarting system" | tee -a ${LOG_FILE}
sudo shutdown now -r
fi
echo "$(date) - Utilization is too low: kill miner and oneBash" | tee -a ${LOG_FILE}
# If miner runs in screen 'miner' kill the screen
screen -X -S miner kill
# Best to restart oneBash - settings might be adjusted already
kill ps -ef | awk '$NF~"oneBash" {print $2}'
let RESTART=RESTART+1
else
echo "$(date) - All good! Will check again in 60 seconds"
fi
done
Pretty cool! I'll try it tonight, lets hope this put the softcrash issues behind us. I will try this out as well; good work. @ Maxximus007 Thanks for putting these together, great collab! I'm not a bash expert, so maybe I'm reading this wrong, but here are some thoughts. The combined code seems to be evaluating each gpu individually for the fault condition to be met, which means if one fails and you have say 5 other cards working then it keeps going until all the cards give reduced output since all of them have to fail individually to increment the counter?So if 5/6 fail we keep going? (Again just looking at it and tracing it in my head so maybe I'm reading wrong). The way I was thinking about it, is that I wanted all the cards to work at above 90% efficiency and reboot as soon as any card strays beyond the threshold - this is why I did the "if and" statement and didn't iterate though "if" statements alone (I didn't know how to iterate "if and" based on an unknown number of cards lol). I had a version giving 6xOK and such but I think it's more efficient to just get 1xOK if ALL meet the 90% criteria and start the countdown as soon as anything is out of norm - and if the miner recovers, flush the counter. I observed a number of these conditions with Claymore where it recovers half the time, but then eventually craps out and the script kicks in. I haven't seen it on my Genoil rig yet since my other script has kept it in check without any softcrash for day 3 now. A thought about the power draw as threshold measure - it is power limit/card specific and I guess people would need to tune their power threshold to their power limit so I agree it's best to use gpu util. (My cards are at 82W limit for example). Thoughts? The code checks each cards individually, at times (with Claymore, not Genoil) I've seen that Util (or Powerpraw) is dropping, maybe even below 90 for a few seconds. In order not to generate too much restarts I check all cards. We can lower this or make it so that each of us can decide when it should reboot. I've combined the restart/reboot so that the first attempt is to restart miner. If that doesn't work, we reboot the machine. We might want to reset the reboot counter after a while, so we don't loose time with a full reboot. In the first code I checked Powerdraw -> if 30 Watt less than Powerlimit there might be something wrong. Idling cards use around 10 Watt, so that works for all I think. We can combine this with Util if that helps. So sure we can make it more advanced, we just have to determine the right parameters. Hope others can let us know in what circumstances they see hanging miners. Just one card, or more or everything? Is Util back to zero? or hanging on to 100%? OK thanks for the clarification, it's really neat and rewarding to see different approaches to this problem Here is why I coded to test that all the cards meet the threshold as one with "if &&": as an example I'll use an event from from my test rig overnight: one card dropped, the "if &&" script waited for claymore to recover for one minute, then booted the system and that was that. Total down time, 2 mins, if you add the 1 minute of reduced capacity waiting for the miner to right itself, 3 minutes impact. The "if &&" code does tests for a graceful miner recovery - by continuing to test the cards for above threshold utilization for 60 seconds after it detects a fault. If the miner recovers, but just sits there (saw both Claymore/Genoil do exactly that a number of times) that's not good enough and the system gets a boot. My other miner restart script did not handle this exact case and once every few days I would find the miner sitting pretty and blowing bubbles mining on one or two cards until I noticed because it did not "see" all the cards anymore but it did see some so it thought it "recovered". If the miner recovers properly, all cards need to hit above threshold and we can flush the counter and life goes on. On my test rig, graceful miner recovery occurred 5-6 times in the past 24 hours without prompting a restart - which is desirable above either running at reduced capacity or 5-6 reboots (IMHO). In contrast - if we test each card independently and increment the error counter one by one until it reaches the number of GPU's, then - depending on the number of cards in the system it could take a long time for all of them to fail - the more cards, the more time to fail (right? am I misunderstanding anything?) So the same event, would unfold differently: the test rig would continue at reduced capacity until COUNT reaches # of GPU's - but since it resets at next check, we can hobble on 5,4,3,2, 1 card until they all die or and the script kicks in or we freeze and require a manual intervention. This could be hours of impact (again if I'm reading this wrong, my apologies, but this is what I'm getting out of looking at it.) So IMHO, by testing that all the cards meet the 90% utilization threshold (as one, all or nothing = if &&), we avoid hours of impact/decreased capacity. My other concern is that as soon as cards start dropping off one at a time the system gets unstable, increasing the risk of a hang or corrupted file system due to a hard crash. My view is that it should be cycled at maximum stability for a graceful restart. Maybe there is a third approach not considered yet, Thoughts? ... edit: Actually one more thought - I did not test for this yet so I don't know the answer - but in the case where the miner does not see all the cards anymore, does this mean that nvidia-smi ALSO does not see all the cards anymore? If so, and if we get the number of cards from nvidia-smi, wouldn't the script assume that the rig has the right number of cards every time that nvidia-smi stop seeing one? I do recall cards disappearing even from nvidia-smi but I never kept track of this so I don't know how often this condition actually occurs. Thanks for explaining, and you do have valid points here. Like your thinking. I will rework it with this in mind. Just wondering: Your script reboots the rig, if the miner itself does not recover. Instead we could introduce reloading miner as the first step here. In my experience that resolves the issue almost every time. It will only save 1-2 minutes so it's not a big deal to just reboot (still had the boot time of V0014 in mind). I did not experience that nvidia-smi looses a card while it's there, but I can imagine that happens with faulty risers. Perhaps we can run the card number count nvidia-smi only at startup the number of cards (saves a call as well) and keep that number during the watchdog process. If we loose a card we do have to reboot anyway. One other thought: Perhaps it would be an idea to echo the output of the log to a screen (tail -f) so the former reboots are shown as well? |
|
|
|
|
IAmNotAJeep
Newbie
Offline
Activity: 44
Merit: 0
|
|
July 11, 2017, 06:15:23 PM |
|
Hey fullzero, i have a question,
without a doubt my biggest problem right now is that when my miner crashes it takes the whole rig down with it, everything gets stuck, SSH barely works, average system load jumps to 14.5!! and Xorg takes up 100% of the CPU, its so bad that none of the standard reboot commands work, they just do nothing, the only thing that actually reboots the rig in this state is "echo b > /proc/sysrq-trigger" so i've set up a script that checks the average system load and if its over 2 it uses the command to reboot, and it works, but i dont like this "solution", yesterday after a reboot nvOC got corrupted somehow, lost my customized oneBash and the whole system became read-only (thankfully i had a oneBash backup that was only a few days behind).
so the question is, what can i do to relive this Xorg error, i run a 7 card rig and never plan on going for a higher number, what can i do with Xorg that would fix this?
Thanks.
@ tempgoga It seems that whenever a soft crash occurs most of the cards drop to zero, so while the display/keyboard is unresponsive you can catch the soft crash from nvidia-smi. The script below checks card utilization, if it drops below 90% it counts down a minute and if mining hasn't resumed it reboots the system. This seems to have worked at least once in my case (only got one soft crash this weekend) and the system recovered as expected. the threshold values work for my setup but others may find different values optimal Also if anyone knows a way to iterate the if && statements we can get the card count from "cards=$(nvidia-smi -L | wc -l); echo $cards" but the way below also works with manual editing to adjust the watchdog for the number of cards in you individual system. ___________ #!/bin/bash #m1 threshold=90 while sleep 5 do number=$(nvidia-smi |grep % |awk '{print $13}' |tr -d %) set -- $number echo -e "$@" # The "if and" statements below need to be manually adjusted to match the number of cards in your system # If you have 5 cards, leave is as, if a different number of cards remove or add the && statements as needed as in the example below if [[ "$1" -gt "$threshold" ]] && \ [[ "$2" -gt "$threshold" ]] && \ [[ "$3" -gt "$threshold" ]] && \ [[ "$4" -gt "$threshold" ]] && \ [[ "$5" -gt "$threshold" ]] # && \ # [[ "$6" -gt "$threshold" ]] then i=12 echo OK else echo $((i--)) fi if [ $i -le 0 ] then echo $(date) REBOOT due to soft crash >>~/watchdog.log sleep -5 sudo shutdown now -r fi done ___________ Hey thats funny I just made a script doing something similar, although it checks the powerdraw. Here it is: #!/bin/bash
# Miner restart script V001
# By Maxximus007
# for nvOC by fullzero
#
# POWERLIMIT MUST BE SET IN oneBash
#########################
### BELOW CODE, NO NEED FOR EDITING
#########################
echo "$(date) - Starting miner restart script." | tee -a ${LOG_FILE}
# Creating a log file to record restarts
LOG_FILE="/home/m1/restartlog.txt"
if [ ! -e "$LOG_FILE" ] ; then
touch "$LOG_FILE"
fi
while true
do
sleep 60
GPUS=$(nvidia-smi --query-gpu=count --format=csv,noheader,nounits | tail -1)
gpu=0
COUNT_LOW_POWER=0
while [ $gpu -lt $GPUS ]
do
{ IFS=', ' read POWERDRAW POWERLIMIT; } < <( nvidia-smi -i $gpu --query-gpu=power.draw,power.limit --format=csv,noheader,nounits)
let POWER_DIFF=$( printf "%.0f" $POWERLIMIT )-$( printf "%.0f" $POWERDRAW )
# If current draw is 30 Watt lower than the limit count them:
if [ "$POWER_DIFF" -gt "30" ]
then
let COUNT_LOW_POWER=COUNT_LOW_POWER+1
fi
let gpu=gpu+1
done
if [ $COUNT_LOW_POWER -eq $GPUS ]
then
echo "$(date) - Power draw is too low: kill miner and oneBash" | tee -a ${LOG_FILE}
# If miner runs in screen 'miner' kill the screen
screen -X -S miner kill
# Best to restart oneBash - settings might be adjusted already
kill ps -ef | awk '$NF~"oneBash" {print $2}'
else
echo "$(date) - All good! Will check again in 60 seconds"
fi
done
You can combine the above with your code, and find the utilization like this: nvidia-smi -i 1 --query-gpu=utilization.gpu --format=csv,noheader,nounits You have to iterate the GPU, starting at 0 to get them all Okay I've combined the two, perhaps this will work for most of us: #!/bin/bash
# Miner restart script V002
# By Maxximus007 && IAmNotAJeep
# for nvOC by fullzero
#
#########################
### BELOW CODE, NO NEED FOR EDITING
#########################
echo "$(date) - Starting miner restart script." | tee -a ${LOG_FILE}
# Creating a log file to record restarts
LOG_FILE="/home/m1/restartlog.txt"
if [ ! -e "$LOG_FILE" ] ; then
touch "$LOG_FILE"
fi
MIN_UTIL=90
RESTART=0
while true
do
sleep 60
GPUS=$(nvidia-smi --query-gpu=count --format=csv,noheader,nounits | tail -1)
gpu=0
COUNT=0
while [ $gpu -lt $GPUS ]
do
{ IFS=', ' read UTIL; } < <( nvidia-smi -i $gpu --query-gpu=utilization.gpu --format=csv,noheader,nounits)
let UTILIZATION=$( printf "%.0f" $UTIL )
# If current utilizations lower than the limit count them:
if [ $UTILIZATION -lt $MIN_UTIL ]
then
let COUNT=COUNT+1
fi
let gpu=gpu+1
done
if [ $COUNT -eq $GPUS ]
then
if [ $RESTART -gt 1 ]
then
echo "$(date) - Utilization is too low: reviving did not work so restarting system" | tee -a ${LOG_FILE}
sudo shutdown now -r
fi
echo "$(date) - Utilization is too low: kill miner and oneBash" | tee -a ${LOG_FILE}
# If miner runs in screen 'miner' kill the screen
screen -X -S miner kill
# Best to restart oneBash - settings might be adjusted already
kill ps -ef | awk '$NF~"oneBash" {print $2}'
let RESTART=RESTART+1
else
echo "$(date) - All good! Will check again in 60 seconds"
fi
done
Pretty cool! I'll try it tonight, lets hope this put the softcrash issues behind us. I will try this out as well; good work. @ Maxximus007 Thanks for putting these together, great collab! I'm not a bash expert, so maybe I'm reading this wrong, but here are some thoughts. The combined code seems to be evaluating each gpu individually for the fault condition to be met, which means if one fails and you have say 5 other cards working then it keeps going until all the cards give reduced output since all of them have to fail individually to increment the counter?So if 5/6 fail we keep going? (Again just looking at it and tracing it in my head so maybe I'm reading wrong). The way I was thinking about it, is that I wanted all the cards to work at above 90% efficiency and reboot as soon as any card strays beyond the threshold - this is why I did the "if and" statement and didn't iterate though "if" statements alone (I didn't know how to iterate "if and" based on an unknown number of cards lol). I had a version giving 6xOK and such but I think it's more efficient to just get 1xOK if ALL meet the 90% criteria and start the countdown as soon as anything is out of norm - and if the miner recovers, flush the counter. I observed a number of these conditions with Claymore where it recovers half the time, but then eventually craps out and the script kicks in. I haven't seen it on my Genoil rig yet since my other script has kept it in check without any softcrash for day 3 now. A thought about the power draw as threshold measure - it is power limit/card specific and I guess people would need to tune their power threshold to their power limit so I agree it's best to use gpu util. (My cards are at 82W limit for example). Thoughts? The code checks each cards individually, at times (with Claymore, not Genoil) I've seen that Util (or Powerpraw) is dropping, maybe even below 90 for a few seconds. In order not to generate too much restarts I check all cards. We can lower this or make it so that each of us can decide when it should reboot. I've combined the restart/reboot so that the first attempt is to restart miner. If that doesn't work, we reboot the machine. We might want to reset the reboot counter after a while, so we don't loose time with a full reboot. In the first code I checked Powerdraw -> if 30 Watt less than Powerlimit there might be something wrong. Idling cards use around 10 Watt, so that works for all I think. We can combine this with Util if that helps. So sure we can make it more advanced, we just have to determine the right parameters. Hope others can let us know in what circumstances they see hanging miners. Just one card, or more or everything? Is Util back to zero? or hanging on to 100%? OK thanks for the clarification, it's really neat and rewarding to see different approaches to this problem Here is why I coded to test that all the cards meet the threshold as one with "if &&": as an example I'll use an event from from my test rig overnight: one card dropped, the "if &&" script waited for claymore to recover for one minute, then booted the system and that was that. Total down time, 2 mins, if you add the 1 minute of reduced capacity waiting for the miner to right itself, 3 minutes impact. The "if &&" code does tests for a graceful miner recovery - by continuing to test the cards for above threshold utilization for 60 seconds after it detects a fault. If the miner recovers, but just sits there (saw both Claymore/Genoil do exactly that a number of times) that's not good enough and the system gets a boot. My other miner restart script did not handle this exact case and once every few days I would find the miner sitting pretty and blowing bubbles mining on one or two cards until I noticed because it did not "see" all the cards anymore but it did see some so it thought it "recovered". If the miner recovers properly, all cards need to hit above threshold and we can flush the counter and life goes on. On my test rig, graceful miner recovery occurred 5-6 times in the past 24 hours without prompting a restart - which is desirable above either running at reduced capacity or 5-6 reboots (IMHO). In contrast - if we test each card independently and increment the error counter one by one until it reaches the number of GPU's, then - depending on the number of cards in the system it could take a long time for all of them to fail - the more cards, the more time to fail (right? am I misunderstanding anything?) So the same event, would unfold differently: the test rig would continue at reduced capacity until COUNT reaches # of GPU's - but since it resets at next check, we can hobble on 5,4,3,2, 1 card until they all die or and the script kicks in or we freeze and require a manual intervention. This could be hours of impact (again if I'm reading this wrong, my apologies, but this is what I'm getting out of looking at it.) So IMHO, by testing that all the cards meet the 90% utilization threshold (as one, all or nothing = if &&), we avoid hours of impact/decreased capacity. My other concern is that as soon as cards start dropping off one at a time the system gets unstable, increasing the risk of a hang or corrupted file system due to a hard crash. My view is that it should be cycled at maximum stability for a graceful restart. Maybe there is a third approach not considered yet, Thoughts? ... edit: Actually one more thought - I did not test for this yet so I don't know the answer - but in the case where the miner does not see all the cards anymore, does this mean that nvidia-smi ALSO does not see all the cards anymore? If so, and if we get the number of cards from nvidia-smi, wouldn't the script assume that the rig has the right number of cards every time that nvidia-smi stop seeing one? I do recall cards disappearing even from nvidia-smi but I never kept track of this so I don't know how often this condition actually occurs. Thanks for explaining, and you do have valid points here. Like your thinking. I will rework it with this in mind. Just wondering: Your script reboots the rig, if the miner itself does not recover. Instead we could introduce reloading miner as the first step here. In my experience that resolves the issue almost every time. It will only save 1-2 minutes so it's not a big deal to just reboot (still had the boot time of V0014 in mind). I did not experience that nvidia-smi looses a card while it's there, but I can imagine that happens with faulty risers. Perhaps we can run the card number count nvidia-smi only at startup the number of cards (saves a call as well) and keep that number during the watchdog process. If we loose a card we do have to reboot anyway. One other thought: Perhaps it would be an idea to echo the output of the log to a screen (tail -f) so the former reboots are shown as well? Hi, if it's a Genoil rig I run this setup: https://bitcointalk.org/index.php?topic=1854250.msg19943144#msg19943144 plus the watchdog script being discussed here in separate "screen -dmS" sessions so I have the watchdog and restart scripts running separately. for that setup I also tail the "ltail" script but if we run only one script then it would make sense to echo some diagnostic output of what faults and recoveries it detects (or log it - but then we need to think about logrotate or someone will run out of space in a few months lol). For the Claymore setup I only run the watchdog since Claymore has it's own fault detection and it restarts by itself so if the built in restart doesn't work, I cycle the box and log the reboot condition only so I don't have to logrotate. |
|
|
|
|
|
TenaciousJ
|
|
July 11, 2017, 07:36:33 PM |
|
Hey guys, any clue what might account for the difference in PCIE utilization? asking because GPU6 is my least stable card that requires the lowest clocks of the bunch and evidently it also has the lowest PCIE utilization.  I had an issue like that, it was because the pcie risers were not giving sufficient power. I had multiple risers on one power line, and the setup didn't work right. Once I put them all on their own power lines it worked properly again. You might be able to get away with 2 on a line, depending on your PSU, but if you have enough lines to put them all on their own i'd do that. |
|
|
|
|
nklak
Newbie
Offline
Activity: 6
Merit: 9
|
|
July 11, 2017, 10:11:16 PM |
|
Hi,
I have few Gigabyte Z270-gaming K3 mobos...they have killer networks E2500 LAN and nvOC boots without LAN. I assume there is no driver support in this distribution. So can you tell me how to install LAN driver, manually or can it be inserted in next version (18) ?.
Or any other solution...
Let me know
Best regards
Personally I dislike Killer Ethernet NICs. I would get one of these or similar for each mobo and never use the Killer NICs. https://www.amazon.com/Cable-Matters-Ethernet-Network-Adapter/dp/B00ET4KHJ2Any of the usb 2.0 adapters should be more than enough for a mining rig. Hi Fullzero... I have managed to find solution in order that existing drivers works for killerNIC E2500 (device ID 1969) sudo modprobe alx
echo 1969 e0b1 | sudo tee /sys/bus/pci/drivers/alx/new_id However , this need to be done after every reset...is there way to insert this to autostart after system boots...sorry for noob questions. I received 10 of these motherboards and need to get them to work. USB NIC are last option... let me know if you can help me to solve this...probably more other owners of GA mobos with Killer NICs. Best regards |
|
|
|
|
|
fullzero (OP)
|
|
July 11, 2017, 10:16:22 PM |
|
I keep getting a database error when I try to update the OP:  plusWATCHDOG_oneBash + additional files (includes newest SRR, switch_v3, reboot, AutoTEMP, Watchdog, Claymore 9.7) Link plusWATCHDOG_oneBash + additional files (includes newest SRR, switch_v3, reboot, AutoTEMP, Watchdog, Claymore 9.7) Link
I integrated a slightly modified IAmNotAJeep_and_Maxximus007_WATCHDOG, fixed the typo in Maxximus007_AUTO_TEMPERATURE_CONTROL. saflter your newest version of switch was causing problems when run with a monitor connected (LOCAL); I would recommend relying on the: IAmNotAJeep_and_Maxximus007_WATCHDOG to handle miner crashes / 0 hashrates. I spent a couple hours testing this, and it is very effective; it is worth noting that it currently only works when the mining process is launched in a screen ( I will make it work for all the clients even when run locally soon: so don't spend a lot of time upgrading rigs with this) Also even if your crashes are perfectly handled; if your OC is so high it crashes every 7 minutes or less: you are losing more time restarting the mining process then you are gaining with a slightly higher hashrate. Use reasonable OC. Please provide me with: # IAmNotAJeep BTC address: <not yet provided> # Maxximus007 BTC address: <not yet provided> # _Parallax_ BTC address: <not yet provided> |
|
|
|
|
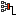
|
mnh_license@proton.me https://github.com/hartmanm How difficulty adjustment works: Every 2016 blocks, the Network adjusts the current difficulty to estimated difficulty in an attempt to keep the block generation time at 10 minutes or 600 seconds. Thus the Network re-targets the difficulty at a total difficulty time of: 2016 blocks * 10 minutes per block = 20160 minutes / 60 minutes = 336 hours / 24 hours = 14 days. When the Network hashrate is increasing; a difficulty ( 2016 blocks ) should take less than 14 days. How much less can be estimated by comparing the % Network hashrate growth + what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ) against what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ). This is only an estimate because you cannot account for "luck"; but you can calculate reasonably well using explicitly delimited stochastic ranges. The easy way to think about this is to look at this graph and see how close to 0 the current data points are on its y axis. If the blue line is above 0 the difficulty ( 2016 ) blocks should take less than 14 days; if it is below it should take more. http://bitcoin.sipa.be/growth-10k.png
|
|
|
|
Nexillus
|
|
July 11, 2017, 10:19:15 PM |
|
Hi,
I have few Gigabyte Z270-gaming K3 mobos...they have killer networks E2500 LAN and nvOC boots without LAN. I assume there is no driver support in this distribution. So can you tell me how to install LAN driver, manually or can it be inserted in next version (18) ?.
Or any other solution...
Let me know
Best regards
Personally I dislike Killer Ethernet NICs. I would get one of these or similar for each mobo and never use the Killer NICs. https://www.amazon.com/Cable-Matters-Ethernet-Network-Adapter/dp/B00ET4KHJ2Any of the usb 2.0 adapters should be more than enough for a mining rig. Hi Fullzero... I have managed to find solution in order that existing drivers works for killerNIC E2500 (device ID 1969) sudo modprobe alx
echo 1969 e0b1 | sudo tee /sys/bus/pci/drivers/alx/new_id However , this need to be done after every reset...is there way to insert this to autostart after system boots...sorry for noob questions. I received 10 of these motherboards and need to get them to work. USB NIC are last option... let me know if you can help me to solve this...probably more other owners of GA mobos with Killer NICs. Best regards First make the command above you have it into a script. Once you have done this you can then call it to your cron job so it will execute on every startup. Now run "crontab -e" this will allow you to edit cron Now add this to cron @reboot /path/to/myscript |
|
|
|
|
|
fullzero (OP)
|
|
July 11, 2017, 10:25:29 PM |
|
Since I got problems with w10 I decided to give this distro a try and I am very surprised things went so easy, good job at this one!
I use this on a headlesss rig and atm I only know that this rig is running by checking pool URL or loginto it with SSH and using nvidia-smi for checking temps.
I am struggling with administrating, a couple of questions:
1. how can I get the terminal output of the automatic starting process (claymore) over SSH?
2. I configured teamviewer to start but how can I connectto it when I can't see the desktop?
3. On Windows,when mining monero with xmr-stak-cpu I was ableto achive about 200-250h/s with my amd fx6300. on the wolfminer its 100~150. Any tweaking options or possible to change to stak-miner?
keep up the good work!
2: As far as I know: you have to setup teamviewer via its GUI; So you are going to need to connect a monitor for that. Could be wrong about this; I don't use teamviewer myself; so other members would know better than I. 3: The cpu miner is intended to be used in a minial capacity so as to not interfere with the GPU mining. Depending on the GPU COIN you are mining; heavy CPU use will impact GPU mining. I would look at the OP for the cpu client: https://bitcointalk.org/index.php?topic=1326803.0 for optimal settings. thx for your reply. on point 3: I mine eth/sia with GPUs and used 4/6 cores on windows. I will try to tweak some settings but I'd like to request this cpu miner for future releases: https://github.com/fireice-uk/xmr-stak-cpusince i'd like to give something back: I am currently using just 3x 1050 ti GPUs, one is only single-fan multimedia GPU, the other 2 are gaming with some extra power. I run all of them at clocks 150/1300 stable. I get them to 13MH/s eth plus 280MH/s SIA per GPU @75w. what I really prefer is setting the power limits to the cards possible lows: The gaming cards can run at 66w and the multimedia edition even 53.5w limit and they do about 11MH/s ETH 270MH/s SIA still. to do this individually for your card you can use 'nvidia-smi'. It will show stats like fan speed, temp, usage and power limit. set a power limit with 'nvidia-smi --power-limit=XX' where XX is power limit in W. If you choose incorrect limit it will show allowed range. this will set limit for all cards, if you want to specify you can do it with '--id=$GPUID' where $GPUID you can find when overviewing with'nvidia-smi' hope its useful for someone now I wonder how to tweak clocks with SSH without killing process, editing config and restart terminal session? I can add https://github.com/fireice-uk/xmr-stak-cpuI will add it to the list once I can update the OP again. The easiest way to do this would be to take a copy of oneBash; rename it, remove everything but the OC settings and implementation. Then you can run that renamed bashfile whenever to change clocks. |
|
|
|
|
|
mnh_license@proton.me https://github.com/hartmanm How difficulty adjustment works: Every 2016 blocks, the Network adjusts the current difficulty to estimated difficulty in an attempt to keep the block generation time at 10 minutes or 600 seconds. Thus the Network re-targets the difficulty at a total difficulty time of: 2016 blocks * 10 minutes per block = 20160 minutes / 60 minutes = 336 hours / 24 hours = 14 days. When the Network hashrate is increasing; a difficulty ( 2016 blocks ) should take less than 14 days. How much less can be estimated by comparing the % Network hashrate growth + what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ) against what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ). This is only an estimate because you cannot account for "luck"; but you can calculate reasonably well using explicitly delimited stochastic ranges. The easy way to think about this is to look at this graph and see how close to 0 the current data points are on its y axis. If the blue line is above 0 the difficulty ( 2016 ) blocks should take less than 14 days; if it is below it should take more. http://bitcoin.sipa.be/growth-10k.png
|
|
|
|
fullzero (OP)
|
|
July 11, 2017, 10:27:22 PM |
|
Hi,
I have few Gigabyte Z270-gaming K3 mobos...they have killer networks E2500 LAN and nvOC boots without LAN. I assume there is no driver support in this distribution. So can you tell me how to install LAN driver, manually or can it be inserted in next version (18) ?.
Or any other solution...
Let me know
Best regards
Personally I dislike Killer Ethernet NICs. I would get one of these or similar for each mobo and never use the Killer NICs. https://www.amazon.com/Cable-Matters-Ethernet-Network-Adapter/dp/B00ET4KHJ2Any of the usb 2.0 adapters should be more than enough for a mining rig. Hi Fullzero... I have managed to find solution in order that existing drivers works for killerNIC E2500 (device ID 1969) sudo modprobe alx
echo 1969 e0b1 | sudo tee /sys/bus/pci/drivers/alx/new_id However , this need to be done after every reset...is there way to insert this to autostart after system boots...sorry for noob questions. I received 10 of these motherboards and need to get them to work. USB NIC are last option... let me know if you can help me to solve this...probably more other owners of GA mobos with Killer NICs. Best regards First make the command above you have it into a script. Once you have done this you can then call it to your cron job so it will execute on every startup. Now run "crontab -e" this will allow you to edit cron Now add this to cron @reboot /path/to/myscript You can also insert this near the top of oneBash with a sleep 5 after it; which is probably easier. |
|
|
|
|
|
mnh_license@proton.me https://github.com/hartmanm How difficulty adjustment works: Every 2016 blocks, the Network adjusts the current difficulty to estimated difficulty in an attempt to keep the block generation time at 10 minutes or 600 seconds. Thus the Network re-targets the difficulty at a total difficulty time of: 2016 blocks * 10 minutes per block = 20160 minutes / 60 minutes = 336 hours / 24 hours = 14 days. When the Network hashrate is increasing; a difficulty ( 2016 blocks ) should take less than 14 days. How much less can be estimated by comparing the % Network hashrate growth + what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ) against what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ). This is only an estimate because you cannot account for "luck"; but you can calculate reasonably well using explicitly delimited stochastic ranges. The easy way to think about this is to look at this graph and see how close to 0 the current data points are on its y axis. If the blue line is above 0 the difficulty ( 2016 ) blocks should take less than 14 days; if it is below it should take more. http://bitcoin.sipa.be/growth-10k.png
|
|
|
|
fullzero (OP)
|
|
July 11, 2017, 10:30:59 PM |
|
Maybe slightly off topic but I have Finally gotten my GTX 970 overclocked. Even in Windows 10 with afterburner it took some creativity. I am wondering about trying this in linux but I really don't want to take my Win10 rig down now since I am trying to test stability duration.
If anybody wants to try a 970 overclock here is what finally worked in windows for me. Not sure how the commands should be changed for linux. This MUST be done BEFORE any overclocking done by afterburner and I would assume nvidia x server settings. After running these commands I can then overclock the card. If you try applying any overclock settings before running these commands it will not work and you must reset all overclock settings, apply these commands, and then try overclocking with afterburner again (i would assume nvidia x server would be treated the same?). The following also must be run in elevated command prompt. I created a scheduled task to run a .bat file with highest privileges on startup.
cd C:\Program Files\NVIDIA Corporation\NVSMI\
nvidia-smi -acp UNRESTRICTED
nvidia-smi -ac 3505,1455
The overclock values may not be compatible with other cards but it doesn't matter. It will ignore it. If nobody else tries this on Maxwell I will go back to nvOC, try it and report back. Thanks for the work!!
this will not work and also is not needed in linux cd C:\Program Files\NVIDIA Corporation\NVSMI\ these may work: nvidia-smi -acp UNRESTRICTED
nvidia-smi -ac 3505,1455 might need to be run as sudo: sudo nvidia-smi -acp UNRESTRICTED
sudo nvidia-smi -ac 3505,1455 good to know. Please let me know if these commands work as intended with nvOC; if they do I will integrate maxwell OC into oneBash. not having any Maxwell cards I am entirely dependent on others to test these things. |
|
|
|
|
|
mnh_license@proton.me https://github.com/hartmanm How difficulty adjustment works: Every 2016 blocks, the Network adjusts the current difficulty to estimated difficulty in an attempt to keep the block generation time at 10 minutes or 600 seconds. Thus the Network re-targets the difficulty at a total difficulty time of: 2016 blocks * 10 minutes per block = 20160 minutes / 60 minutes = 336 hours / 24 hours = 14 days. When the Network hashrate is increasing; a difficulty ( 2016 blocks ) should take less than 14 days. How much less can be estimated by comparing the % Network hashrate growth + what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ) against what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ). This is only an estimate because you cannot account for "luck"; but you can calculate reasonably well using explicitly delimited stochastic ranges. The easy way to think about this is to look at this graph and see how close to 0 the current data points are on its y axis. If the blue line is above 0 the difficulty ( 2016 ) blocks should take less than 14 days; if it is below it should take more. http://bitcoin.sipa.be/growth-10k.png
|
|
|
|
fullzero (OP)
|
|
July 11, 2017, 10:34:19 PM |
|
Quick question that I'm sure many of you have solved various ways. Any thoughts on the safest way to power the 7th GPU(1070)/riser with an EVGA 1300 G2? Custom adapter cable? Molex to 6+2? Two of the VGA cables have a split connection from the PSU, but I didn't want to connect two cards and two risers split twice from the same cable.
Thanks for any quick thoughts.
There are dual molex to pcie 6+2 adapters; if you use both molex cables 2 different molex cables(from the psu each from a different molex port) into one adapter it should be able to handle 160 watts. I would keep it below 135 if you use this method. |
|
|
|
|
|
mnh_license@proton.me https://github.com/hartmanm How difficulty adjustment works: Every 2016 blocks, the Network adjusts the current difficulty to estimated difficulty in an attempt to keep the block generation time at 10 minutes or 600 seconds. Thus the Network re-targets the difficulty at a total difficulty time of: 2016 blocks * 10 minutes per block = 20160 minutes / 60 minutes = 336 hours / 24 hours = 14 days. When the Network hashrate is increasing; a difficulty ( 2016 blocks ) should take less than 14 days. How much less can be estimated by comparing the % Network hashrate growth + what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ) against what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ). This is only an estimate because you cannot account for "luck"; but you can calculate reasonably well using explicitly delimited stochastic ranges. The easy way to think about this is to look at this graph and see how close to 0 the current data points are on its y axis. If the blue line is above 0 the difficulty ( 2016 ) blocks should take less than 14 days; if it is below it should take more. http://bitcoin.sipa.be/growth-10k.png
|
|
|
|
fullzero (OP)
|
|
July 11, 2017, 10:36:26 PM |
|
Hey fullzero keep up the awesome work! What's the ETA on nvOC18?
I want to test the new Biostar and ASRock mobos first; I have a shipping notification for both; so I should get them this week. I managed to get an ASRock when newegg had them in stock for 5 mins yesterday.  |
|
|
|
|
|
mnh_license@proton.me https://github.com/hartmanm How difficulty adjustment works: Every 2016 blocks, the Network adjusts the current difficulty to estimated difficulty in an attempt to keep the block generation time at 10 minutes or 600 seconds. Thus the Network re-targets the difficulty at a total difficulty time of: 2016 blocks * 10 minutes per block = 20160 minutes / 60 minutes = 336 hours / 24 hours = 14 days. When the Network hashrate is increasing; a difficulty ( 2016 blocks ) should take less than 14 days. How much less can be estimated by comparing the % Network hashrate growth + what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ) against what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ). This is only an estimate because you cannot account for "luck"; but you can calculate reasonably well using explicitly delimited stochastic ranges. The easy way to think about this is to look at this graph and see how close to 0 the current data points are on its y axis. If the blue line is above 0 the difficulty ( 2016 ) blocks should take less than 14 days; if it is below it should take more. http://bitcoin.sipa.be/growth-10k.png
|
|
|
|
fullzero (OP)
|
|
July 11, 2017, 10:38:21 PM |
|
How many NVIDIA GPUs does nvOC support on 1 mainboard?
In theory 14x; I may need to update some system files the new Biostar and ASRock monster mobos. see: https://bitcointalk.org/index.php?topic=1854250.msg20018178#msg20018178I have received a shipping notification for the Biostar; but I still need one of the ASRock H110 Pro BTC+ to test / ensure support: https://www.newegg.com/Product/Product.aspx?Item=N82E16813157781If a member has one arriving early this week (before Wednesday preferably): I am offering double the newegg price for one + $20 for USPS Priority Mail Flatrate Box shipping (with insurance) to me: $285 in BTCUnless your Trust exceeds mine; I will pay upon receipt: I am also willing to use most trusted forum members as escrow if desired. I can confirm it works out of the box on H110 which I received today from newegg. Currently with 9 cards (8x1070 and 1x1050). Will hook up a few more to see if my Celeron holds up to it and 4GB RAM will be enough. I'm clueless in linux but it was completely painless to get nvOC running. I just wanted to confirm it will work with 8+ cards and it did. I followed Phil's instructions and pointed it to my Nicehash wallet. Modified OC settings and it picked it up no problem. I'm pretty happy with it but will not sell you the board. I can run a few tests for you if you like but will need detailed instructions. And thanks for making nvOC. It rocks! -scsi I managed to get an ASRock when newegg had them in stock for 5 mins yesterday. Thanks for the info; I really need a 14x test using 1x m2 adapter to ensure full compatibility. Its good there isn't a chipset problem. |
|
|
|
|
|
mnh_license@proton.me https://github.com/hartmanm How difficulty adjustment works: Every 2016 blocks, the Network adjusts the current difficulty to estimated difficulty in an attempt to keep the block generation time at 10 minutes or 600 seconds. Thus the Network re-targets the difficulty at a total difficulty time of: 2016 blocks * 10 minutes per block = 20160 minutes / 60 minutes = 336 hours / 24 hours = 14 days. When the Network hashrate is increasing; a difficulty ( 2016 blocks ) should take less than 14 days. How much less can be estimated by comparing the % Network hashrate growth + what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ) against what the Network hashrate was at the beginning of the difficulty ( 2016 blocks ). This is only an estimate because you cannot account for "luck"; but you can calculate reasonably well using explicitly delimited stochastic ranges. The easy way to think about this is to look at this graph and see how close to 0 the current data points are on its y axis. If the blue line is above 0 the difficulty ( 2016 ) blocks should take less than 14 days; if it is below it should take more. http://bitcoin.sipa.be/growth-10k.png
|
|
|
|


